Mac で StreamDiffusion やってみる

昨年末頃 100 fps 超えの超高速 Stable Diffusion(SD)として話題になった StreamDiffusion。
CUDA 前提のため Mac では厳しかろうと思われたが結論から言うと動かせた。
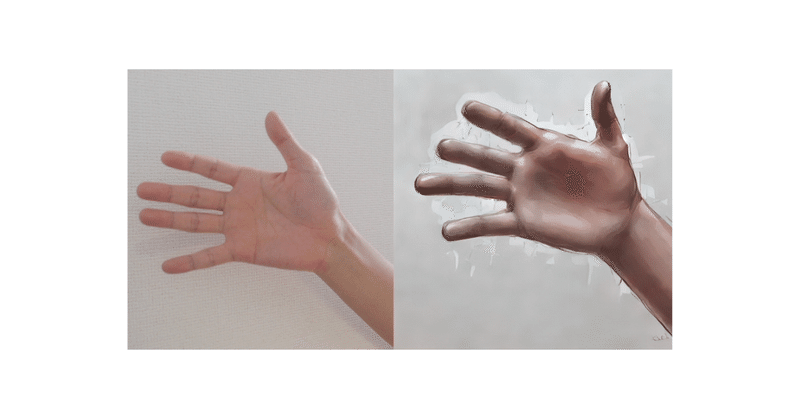
下記が実行結果で少々遅くカクツキあるが(GPU 利用で)3〜4 fps くらいで動く。
Web カメラで読み取った手の動作をリアルタイム変換している。

StreamDiffusion とは
従来より SD を高速化させるための研究は数多くある。
StreamDiffusion もそのひとつであり複数の高速化技術を組み合わせることで既存モデルを爆速化する技術(フレームワーク)。
(LCMやADDで生成に必要なステップを減らした上に)StreamDiffusionでは、以下の様な処理のパイプラインを構築して全体の画像生成速度を高速化しています。
・Stream Batch
・Residual Classifier-Free Guidance (RCFG)
・Stochastic Similarity Filter
・IO queueの最適化
・Pre-computationの最適化
・Modelの高速化する技術の利用
例えば高速な SD のひとつ Stability AI の SD Turbo と StreamDiffusion を組み合わせて使うイメージ。
全体像は下記の記事が分かりやすい(Mac で動かす上でも大変お世話になった)。
StreamDiffusion を動かす上で各パラメータが何を表しているかはこちらの記事に網羅されている。
また、踏み込んだ技術詳細は論文著者による解説動画が詳しい。再生時間は長いが基礎から説明あり SD 赤ちゃんの自分はこれを観て知識をゼロから蓄えた。
Mac で実行する
サンプルリポジトリ作成した。README 通りに動かせば動作する(はず)。
一応軽く解説すると、StreamDiffusionWrapper を利用するのが最も動かしやすかったため stream_diffusion.py にて更にラップし利用している。
class StreamDiffusion:
def __init__(
self,
model_id_or_path: str = "stabilityai/sd-turbo",
prompt: str = "1girl with brown dog hair, thick glasses, smiling",
negative_prompt: str = "low quality, bad quality, blurry, low resolution",
acceleration: Literal["none", "xformers", "tensorrt"] = "none",
use_denoising_batch: bool = True,
use_tiny_vae: bool = True,
guidance_scale: float = 1.2,
delta: float = 0.5,
) -> None:
device = "mps" if torch.backends.mps.is_available() else "cpu"
self.stream = StreamDiffusionWrapper(
model_id_or_path=model_id_or_path,
t_index_list=[16, 32],
warmup=10,
device=device, # type: ignore
acceleration=acceleration,
mode="img2img",
use_denoising_batch=use_denoising_batch,
use_tiny_vae=use_tiny_vae,
cfg_type="self" if guidance_scale > 1.0 else "none",
)
self.stream.prepare(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=guidance_scale,
delta=delta,
)コード中で重要なのは 2 点あり:
acceleration(tensorrt 等)は Mac 非対応なので none にする
device の型が mps 受け付けてないので # type: ignore で回避
後は本家の pipeline.py にある CUDA 依存部分をコメントアウトしたら Mac(MPS 利用)で動作するようになった(詳細は README に書いているため割愛)。
補足:高速化に寄与してそうな部分
StreamDiffusion にて利用している SD Turbo を生で動かすとどれくらいの速度出るかも検証してみたが 1.1 fps くらいだった。StreamDiffusion にて use_tiny_vae を False にすると 1.4 fps くらい。StreamDiffusion の本懐ではない(?)が Tiny な VAE がだいぶ効いてそう。どうすりゃもっと早くなるかは調査したいところ。
(下記のように生の SD Turbo を CoreML 等使って頑張って速くしてる人もいる)
Vanilla SD turbo runs at ~1.5fps on my M1 Max with the diffusers lib.
— Cyril Diagne (@cyrildiagne) December 23, 2023
I wonder how close to realtime it can get?
Maybe CoreML compilation, 6bits palettisation, TAESD and a few more tricks like RCFG from StreamDiffusion can push it to ~20fps? pic.twitter.com/mIZ7eGBugS
この記事が気に入ったらサポートをしてみませんか?