Uber徹底研究 -MaaSを支えるデータサイエンス編-

今回はUberが使用する高度な手法について紹介します。紹介するのは以下の5つですが、レコメンドに関しては次回に回します。今回からは少し専門的な内容になります。
・需要予測
・配車最適化
・ダイナミックプライシング
・解約予測
・レコメンド(ボリュームが多いので、次回説明)
本記事は連載4回目の投稿ですが、これまでの投稿は以下の通りです。
・Uber徹底研究 -ビジネス概要編-
・Uber徹底研究 -UX改善編-
・Uber徹底研究 -ゲーミフィケーション・行動科学編-
Uberのサービスは、まるで魔法を唱えてタクシーを召喚するかのように表現されますが、その魔法の裏にあるデータサイエンスを今回は紹介していきます。
■需要予測
昨今、様々な企業が需要予測を行っています。需要予測には、通常はいわゆる時系列モデル(ARIMA等)を活用した予測や、Xgboostやランダムフォレスト等の機械学習モデルを活用した予測が多くあります。
日本でもNTTドコモがAIタクシーとして、AIを活用した需要予測を行っています。この需要予測は実際には時系列モデルと深層学習モデルを組み合わせて予測を行っているようです。
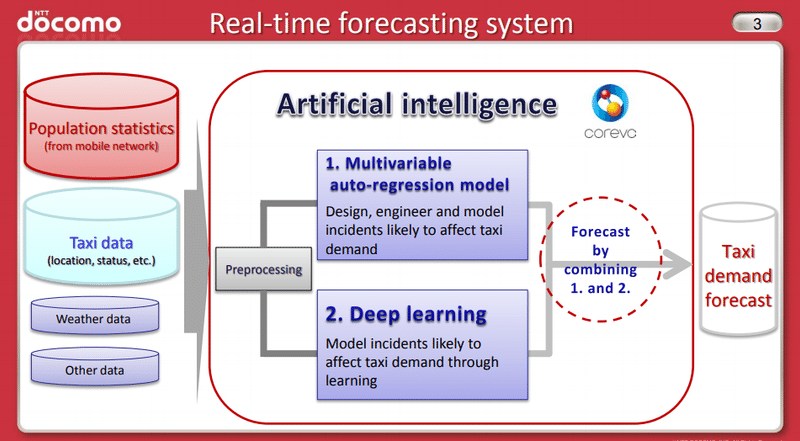
出所:https://www.nttdocomo.co.jp/english/info/media_center/event/mwc2017/pdf/about_ai_taxi.pdf
Uberはモデルを複数検討していましたが、需要変動の大きい休日やスポーツイベントなどの突発的な事象が発生した際の予測が課題になっていました。この予測はドライバーの割り当てや、予算計画、ユーザーエクスペリエンス(UX)にも関わるため大変重要です。とはいっても、突発的な事象は複数の外的要因に左右されるため、これらの要因(変数)を予測することは困難です。
そこでUberは時系列予測と不確実性推定を行うベイジアンニューラルネットワーク(BNN)フレームワークを使用しました。BNNを使用した背景としては、過学習を防げることに加え、点推定ではないので予測結果の不確実性を考慮できる等が挙げられます。
UberはBNNを活用することで需要予測とその際の異常検知を試みました。
(前提条件などは以下2つ参照。)
・Deep and Confident Prediction for Time Series at Uber
Uberが以下の各モデルで予測誤差を検証した所、BNNモデルが最も誤差が小さかった結果も出ています。また、異常検知も行えました。
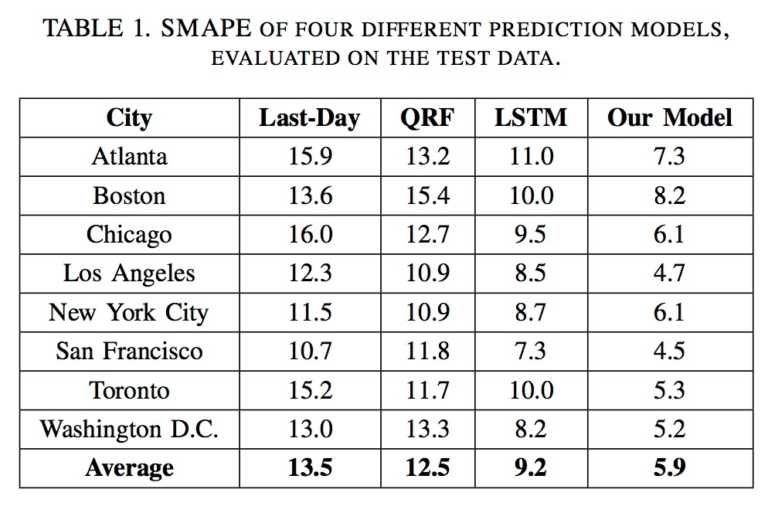
誤差の検証にはSMAPEを使用しています。
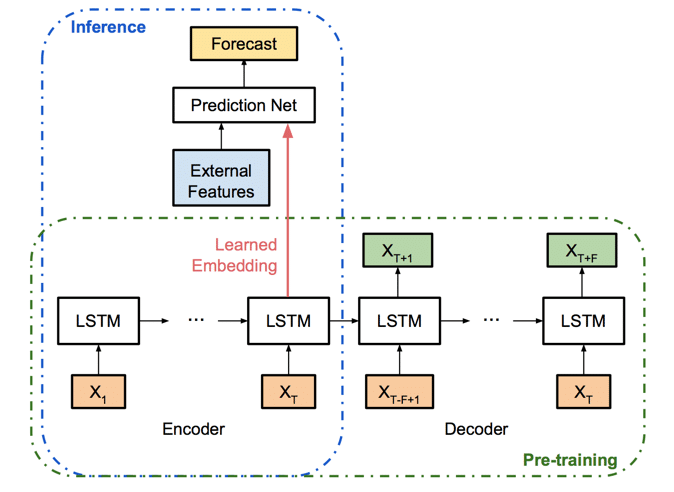
なお、Uberが実際に設計したBNNのアーキテクチャは以下の通りです。LSTMがメインで使用されています。詳細はこちらをご覧ください。
■配車の最適化
Uberのアプリで配車を設定してから、どれくらい待ち時間があるでしょうか。実はこの待ち時間は全体で最適・最短になるように設定されています。
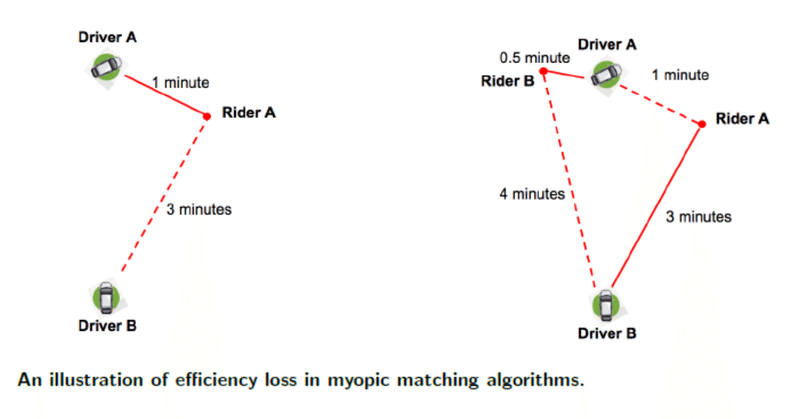
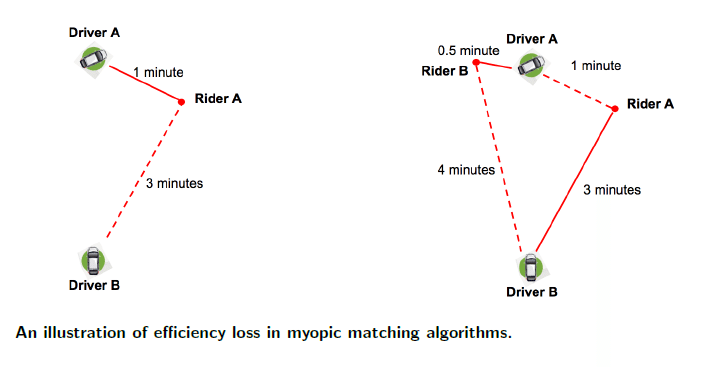
この最適化の例を以下の図に示します。左下図では、乗客(Rider)とドライバー(Driver)が1人と車両2台、右下図では2人と車両2台が存在している状況を示しています。左図ではドライバーAは乗客から1分、ドライバーBは乗客から3分の距離です。 次の瞬間、右図でドライバーAから0.5分、ドライバーBから4分離れた別の乗客Bが表示されたとします。そうすると、乗客AとドライバーBを、乗客BとドライバーAをマッチングさせます。 こうすることで、これら2つの移動時間・待ち時間は全体で 1 + 4 = 5分から3 + 0.5 = 3.5分に短縮されるのです。
中国の配車アプリDiDiでも、配車の最適化を行っています。DiDiはタクシーと乗客のマッチングに関して、ハンガリアンアルゴリズムという他の最適配車アルゴリズムを使用しています。
(追記) 近年では、深層強化学習が使われているようです。
Uberの場合、実際には同じプラットフォーム上に多種かつ複数の車両が共存するため、マッチングはさらに複雑になります。 例えば、UberPoolやExpress Poolなど他者と相乗りするサービスもあります。そのため、マッチングの決定プロセスはより複雑になります。
このような大規模かつ複雑な問題をUberは解いているのです。相乗りの最適配車については以下のダイナミックプライシングの節で説明します。
■ダイナミックプライシング
従来から需要と供給に応じて価格を変動させる方法はホテルや飛行機チケットの価格設定などで使用されてきました。現在では、ダイナミックプライシング(DP)は高度化し、経済学、オペレーションズリサーチ、コンピュータサイエンス、物流などの分野で活発な研究分野の1つになりました。特に、高度なマッチングとDPは非常に注目を集めています。
DPは、既に多くのプラットフォームで利用されています。
例えば以下のようなサービスでDPが利用されています。
・eコマース:eBay
・駐車スペース:SpotHero
・コンサートやスポーツの試合チケット:StubHub
・カーシェアリング:TuroやGetaround
・民泊:Airbnb
また、UberEats、Instacart、またはGrubhubなどの食料品配達プラットフォームは、Uberなどのプラットフォームに似ていますが、サービスに対する緊急度が低いため配達までには比較的時間に余裕があります。
しかし、Uberの場合には乗客(ライダー)とドライバーは時間に敏感であるため、乗車価格とマッチングはリアルタイムで行われる必要があります。そのため、Uberでは乗車価格は1秒以内に提示され、乗客とドライバーのマッチングは数秒以内に行われます。
そしてドライバーのアプリでは、マップ上にこの地域に行けば報酬が何倍か高くなるという表示がされます。これにより、需要と供給のバランスを取ろうとするのです。
このように需給バランスを取らなければならない理由としては、純粋に利益の最大化のためだけでなく、突発的に需要が増えた場合に供給が不足する事態を防ぐためでもあります。供給が不足している状態でユーザーから連絡をもらっても、配車させるドライバーが存在しません。このような状態はユーザーにとって無駄足であり、この状態は”Wild Gouse Chase(WGC)”とも呼ばれています(野生のカモ猟は難しいことから)。
供給不足を防ぐためにDPを行いますが、具体的にどのように価格を調整するのでしょうか。
ここで登場するのが以下の基本式です。

L:Uberのプラットフォーム上のドライバー数
O:配車可能なドライバー数
η・Y:配車場所に向かっているドライバー数(ηは向かっている時間)
T・Y:稼働中のドライバー数(Tは目的地までの所要時間)
この基本式に基づき、あとは各パラメータの関係を職人技で調整してDPを設計します。その職人技についてはかなり細かくなるので、論文の方をご参照ください。
>論文:Dynamic Pricing and Matching in Ride-Hailing Platforms
・ハイレベルな相乗りの最適化
Uberはライドヘイリングと呼ばれる、乗客に対してドライバーが迎えに行くだけでなく、近年はExpress Poolと呼ばれる通勤客向けの相乗りサービスを始めています。
Express PoolはUber Poolの最大50パーセント、Uber Xの最大75パーセントオフの料金でサーヴィスを利用できるからだ。料金をバスや電車、地下鉄と同じ価格帯にすることによって、Uberは自社サーヴィスを通勤手段の選択肢に加えたのである。Express Poolの仕組みもまた、公共の交通機関に似ている。アプリでExpressを選んだユーザーは、クルマに迎えに来てもらうポイントではなく、エリアを選ぶことになる。その後、Uberは最大2分で移動に最も効率的な相乗り相手を探す。乗客や目的地が決まったら、ユーザーは待ち合わせ場所を指示される。
このサービスはドライバーにとっては、1回の稼働で2人以上の乗客を乗せられるのでうまく価格を調整するとお得になる可能性があります。
Uberはよりダイナミックプライシング(DP)の難易度が高いExpress PoolでDPを行うだけでなく、待ち時間の最適化(Dynamic Waiting:DW)を行っています。
実際にDPとDWを組み合わせた結果、
・収益と稼働率を高く維持しつつ、
・乗客の待ち時間を6分以内に抑えることができ、
・DPの大きな変動を防ぐ
ことができました。
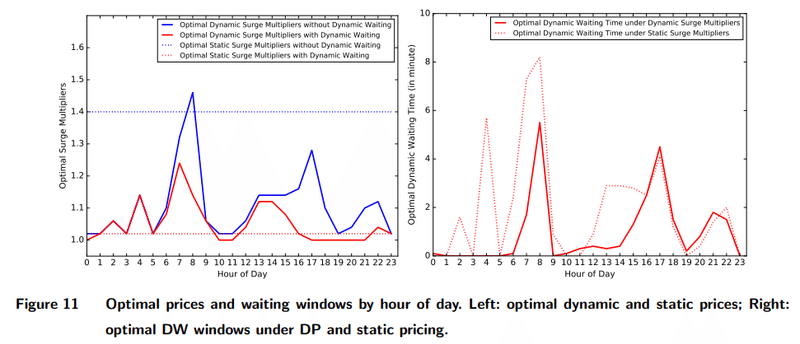
特に3つめのDPの大きな変動を防げたのは重要です。
というのも、例えばある突発的な事象が起こったがためにUberへの需要が高くなり、ダイナミックプライシングによって急激に乗車価格が上がった場合、Uberの利用をためらう人も多く出てくるからです。その中には、Uberへの好感度が非常に下がり、UberではなくLyftなど他社のサービスを今後は利用しようという人も出てきます。
そのため、価格をどの程度、どのタイミングで上下させるのかを入念に考える必要があったのです。
以上のように、Uberは非常に複雑な価格設定・配車の最適化が可能なのです。
■解約予測
解約予測は通信会社、保険会社、Eコマースの企業など、利用者の多い様々な企業で行われています。
Uberも既に利用者数が非常に多くなったため、今後は利用者を減らさないための取り組みとしてユーザーの離脱防止をしています。そのためにUberもCharn analytics(解約予測)をしています。
Uberでは、乗客が最初にUberの配車サービスを利用した後、2回目に利用するまでにかかる時間に重点を置いています。なぜならば、利用者の多くは紹介やプロモーションを通して初めてUberを利用しており、2回目の利用(セカンドライド)は、利用者がUberの利用に価値を見出していることを示す重要な指標だとUberは考えているためです。ただし、セカンドライドまでの時間をモデル化するのは難しいです。例えば、Eコマースでの解約者は最後にサイトを訪れてから40日以上経過した人などと定義できますが、Uberの利用者の中にはそれほど頻繁には配車サービスを利用せず、出張中にのみUberを使用する利用者もいます。そのため、モデリングをする際に解約者の定義・モデルに注意する必要があります。定義・モデルの詳細はこちらを参照していただき、Google Colabでも実際のコードを確認して頂けます。
解約予測をする際には単なる精度予測とは異なり、予測モデルのブラックボックス化を避けています。なぜならば、解約予測の場合には、予測後の「打ち手」が重要であり、その打ち手を考えるためには何が解約につながっているのか原因を追究する必要があるためです。そのため、Uberでは解約予測をする際に、Xgboostなどのブラックボックス化しやすい手法を避け、確率的プログラミング言語(特にUberでは”Pyro”)を用いたベイズ推定を使用しています。一般的にモデルが単純な場合には最尤推定法など最初によく使う手法でも問題ないのですが、Uberが使用するのは複雑なモデルであり、このようなモデルの多くは尤度関数が正規分布(多変量なものも含めて)でよく近似できないため、最尤推定で求めた予測分布は既存のデータに過剰に適合してしまう傾向があります。
ベイズ推定であれば、全てのパラメータを確率変数とみなして確率分布を推定し、上記の問題を解消した柔軟なモデリングが可能です。
これにより、解約予測をしつつも解約の要因ごとに変数を設定し、解約の中でもどの要因が効いているのかを表現できるのです。この予測により、離脱しそうな利用者に対して先んじて個別に特別クーポンを配信する等の手を打つことができるようになります。
少し長くなったので、レコメンドについては次回紹介します。
続き↓
BNNの参考文献:
https://www.slideshare.net/masa_s/dl-hacksbayesian-neural-network
https://www.slideshare.net/yutakashino/ss-79165738
https://www.slideshare.net/TakeshiYoneda/db-analytics-showcase-sapporo-2017
この記事が気に入ったらサポートをしてみませんか?