
2018年の人工知能、データ分析 - できること、できないことのホントノトコロ

[追記] 書籍化しました!
2018年7月に作成したこの記事から、アップデートなどを詰め込んで、2019年5月11日発刊の図解速習DEEP LEARNINGという本ができました。[2019年5月版] 機械学習・深層学習を学び、トレンドを追うためのリンク150選 - Qiitaでも、一部内容をご覧いただけます。ぜひ手にとってみてください。
Binnovative - UNBOX THE BLACKBOX!シリーズ
6月21日にVenture Cafe Tokyo Thursday gathering@虎ノ門ヒルズカフェの一枠で、NPO Binnovativeとして掲題の機械学習イベントを開きました。ゲストにPegara Inc. 中塚さんをお招きし、前後半30分ずつに分けて話をしました。筆者の話した前半部分、その後の補足やアップデートを本記事にまとめます。
課題認識
ビッグデータ、データ分析という言葉が2010年代前半に注目されました。その後、人工知能、深層学習が盛んに取り上げられ数年がたちます。しかし、今日、一年後、五年後何がどこまでできるのか、色々な人、メディアで語る時間軸も異なり、今ひとつ全体像を掴みづらいところです。
セッションのテーマ
・今日の人工知能/ データ分析のできる/できないを各々なりに理解する
・求める人には明日からできることをお持ち帰りいただく
「シンギュラリティ」「AIが仕事を奪う」といった内容はとりあげません。また、エンジニアリング、プログラミングなどの事前知識は前提としません。下記のように、2017-2018年に発表された論文/学会、各社発表から、デモ/動画を中心に、事実ベースでかみくだき紹介し、帰納的に読者が掴めることはないか探ります。
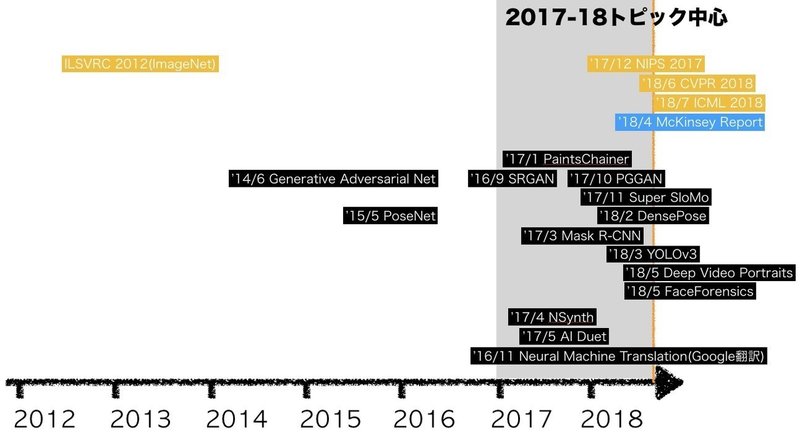
では、まず導入からはじめます。
弱いAIをみていきましょう
強いAI、弱いAIという言葉があります。
人工知能と聞くと、映画などのイメージから「人間と同じか、それ以上の知性を発揮するなにか」を思い浮かべるかもしれません。そうした、いわゆる強いAIの研究は行われています。人工知能学会2018でもパネルが行われましたし、先週もDeep Mind等のサーベイ資料が話題となりました。ただ、強いAIへのアプローチは研究者の間でも諸説ある段階です。実装/デモとして紹介できるものは存在しないため、本稿では対象としません。
2018年現在、実際に使えるのは「特定タスクを解くのに優れている」いわゆる、弱いAIです。本稿はそちらを対象とします。まずWhyとHowを概観したのち、残りの時間は"What - 現状できること"に着目します。

Why? - 人工知能をつかう目的、理由
ビジネス活用
実際のところ、実ビジネスの世界では、どれだけAI活用が進んでいるのか。McKinseyが19業界、400のAI事例を分析したレポートを2018年4月に公開しています。
いわゆる深層学習のビジネス活用も始まっているが、大半は、
・回帰分析などtraditionalな方法
・保険、広告、製造などの限られた産業での活用にとどまる
とされています。これは「すごいAIが突然やってきて、一気産業が塗り変わっている」といったことは起きておらず、適材適所、かつ試行錯誤をしながら産業適用が始まっているというステータスを正確に表しています。
アート活用
AIというと、人間にはできない正確無比、かつビジネス判断をばっさばっさと行うマシンを想像するかもしれません。一方NIPS2017で、面白いWorkshopが開催されました。Machine Learning for Creativity and Designという、機械学習を画像、音などの生成を通して、アートに適用するというものです。応募された作品のギャラリーがオンライン公開されています。
機械学習を取り入れたデモの完成度には驚かされますし、後に取り上げるようにクリエイティブ系の仕事に機械学習を取り入れ、人のエイドとして使うことは始まっています。
How? - 人工知能を実現する方法
機械学習の各手法
弱いAI = 領域特化型AIが取る方法は、機械学習です。機械学習とは何か。今日は、Whatに着目するため、あまり深入りはしませんが、このようなプロセスを辿ります。
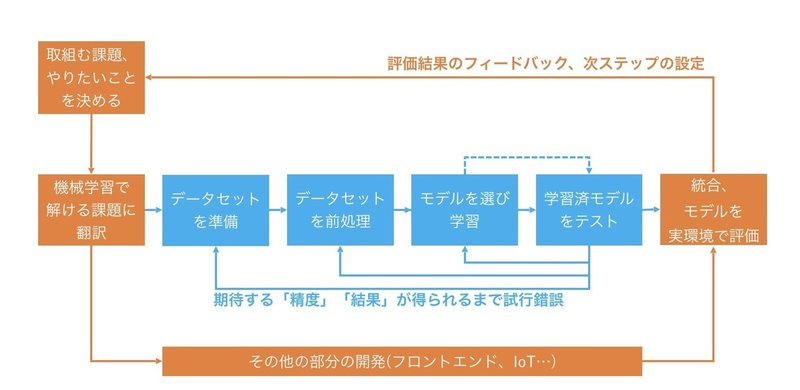
モデルを選び学習、学習済モデルのテスト、実環境での評価にズームインするとこんな感じです。

ざっくりとまとめると、
・ある入力を取り、期待された出力を返す箱(モデル)がある
・データを与えることで、その箱を訓練する
・さまざまな種類の箱がある
・与えるデータの種類ごとに、その処理が得意な箱の種類は限られる
というものです。
さて、箱の種類(モデルのかたち)には様々な名前がついています。
数値系を扱う時には、線形回帰, RandomForest, SVM, 最近では勾配ブースティング木の実装(xgboost, LightGBM, catboost)がよく使われ、Multilayer perceptron(MLP)が使われることもある。画像/映像系はConvolutional Neuralnets(CNN)の様々な変形。文章や音声を扱う時は時系列を扱えるRecurrent Neuralnets(RNN)の変形が主に使われます。ドメインによらず生成にはGAN、AutoEncoderの類型もあります。連続した行動の最適化(強化学習)には、Deep Q Network、Rainbowなどの名が挙がります。またそれらが直列、並列で組み合わされることがあります。
実用には、どんな課題にどんなモデルのかたちが適当で、それにより一般にどの程度のレベルで目的が叶えられるかを知っておくことが大事です。
ソフトウェアやハードウェア
「箱」の訓練、および利用には、それをのせるソフトウェアやハードウェアが必要です。ソフトェアとしては、PyTorch, TensorFlow, Chainerなどのフレームワークとそれを活用したコード、それらを支えるローレベルのライブラリ。さらにそれらの実行環境としての、CPUやGPU, 場合により専用チップを搭載したサーバからスマートフォンまで、用途にあわせて選択されます。2015年以前は、ふんだんな計算リソース、クラウド側での実行が前提でしたが、2016年以降徐々に、組み込み機器やスマートフォンなど、現場に近いところで動かすための仕組みの研究、実装が進んでいます。
これくらいの説明で、今日はとどめておくことにします。
What? - 人工知能でできること
ここまで人工知能のWhy, Howを見て来ました。「人工知能のできること、できないこと」をざっくり掴むためには、それらに挟まれたWhatの例をできるだけ沢山知ることが大事ではと考えます。ここからは、

上のような、ヨコの分類(適用ドメイン)とタテの分類(出力の種類)にわけて、各事例をみていきます。各事例はデモと「できること」の概要にとどめ、ドメイン横断で数多くを紹介することを試みます。
数値系 - 推論: データから、対象を予測する

以前から、数理・統計的なデータ分析は金融、保険をはじめとした業界で使われてきました。そして2010年代前半、ビッグデータ/ データサイエンティストブームがありました。ある部分はバズワードとして消えた一方、ある部分はしっかりと産業に根付きました。デジタル広告、ゲームなどのアプリ・Webサービスの改善に大量のデータ分析が役立てられています。
AI/人工知能ブームで、データ分析の領域も、しばしば一緒に語られます。もともとはデータ分析を行う職場でないと、実データや、どういった手法がどれだけの効果を生むのかに触れられませんでした。近年の静かな競技データ分析ブーム、個人でも望めば一定の情報に触れられるようになりました。

継続的にデータ分析コンペが開かれる場所としては、グローバルではKaggle、日本ではSIGNATEが有名です。他にも、学会と併催されたりと、単発のものも含めると、様々な開催形態があります。このように、実社会やビジネスのデータを使ったコンペ、参加者、そのコミュニティが増えました。
Kaggleでは、コンペによっては1000万円を超える賞金を狙って、数ヶ月の間、熱い戦いが繰り広げられます。サイトにはForumが設置されており、参加者同士で議論が展開されます。また、コンペが終わったらすぐ、上位入賞者や、惜しくも届かなかった参加者間で、解法共有が始まります。そうして、生きたデータに、その時点のスペシャリスト達が手を尽くしたノウハウが得られます。こちらに有志、コンペ横断で解法がまとめられています。
SIGNATEは、コンペ中および終了後のForumは提供されないものの、この7月から過去コンペの上位入賞解法が順次公開となりました。こちらは日本語、日本企業の課題設定が多く、よりとっつきやすいのではと思います。
(手前味噌ながら、私の2017年画像分類コンペ入賞解法も掲載されました)
画像/映像 - 認識: AIの目にうつるもの

数値の次に、画像/映像を取り上げます。
実は「画像/映像」も、この後取り上げる「音声/音楽」も「文章/言語」も、基本的には「数値の集まり」の表現に置き換え、機械学習を適用します。
例えば、コンピュータ上で表現される「画像/映像」は、小さな点(ピクセル)の集まりで、それらの点は、[赤, 緑, 青] = [255, 0, 0] というように、光の三原色の強さでひとつひとつが表現され、200ピクセル x 200ピクセルの画像ならば、その40,000点分 x 3 = 120,000 の数値として扱われます。「音声」も、[0, 2, 4, 3, 5, ...] のように、ある音の波が数字の列で表され、扱われます。
ただこの記事では簡単のため、あくまで人が認識する入力、という軸でカテゴリを分けることにしました。
画像/映像の認識とはどのようなものを指すのでしょうか。基本的な課題を図にしてみました。一つのもののみ写った画像から、複数のものが写った画像、と右へ行くほど課題は難しくなります。2010年代のAIブームの興りとして触れられることの多い(参照記事) ImageNet LSVRC 2012における深層学習の躍進は、この一番左、「一つのモノの名前あて」タスクにおけるものでした。

いま、物体認識はここまでできる
そこから6年。時は流れ、できることは飛躍的に増えました。「複数のモノ」「名前と位置、もしくは輪郭あて」を行った動画がこちらです。
こうした物体認識は、例えば自動運転の基礎技術のひとつとなります。自動車のオンボードカメラ映像から、複数モデル(YOLOv3, MaskRCNN)の認識精度を比べています。それぞれ四角(bounding box)や、塗り分けられたエリアは、「くるま」「道路」「建物」「標識」などを指します。まず、自動運転応用を考えると、こうした「目」が必要になることは想像に難くないでしょう。
用途を特化した認識の応用
輪郭から一歩進んで、人間に特化して、そのポーズを推定するようなモデルもあります。
そのポーズ推定をつかって、似たポーズをとった写真を表示するというデモも話題になりました。
つい先日、CVPR2018のOralで発表されたDensePoseは、ポーズ推定にとどまらず、2Dの映像から、人間の3D表面モデルを抽出することができます。
上のPoseNetの初出は2015年ですが、動画のデモ実装はTensorFlow.js(旧deeplearn.jsを2018年3月にTensorFlow familyへ統合発表)というブラウザ上の実行環境、Webカメラのみで行われています。今回は取り上げませんが、ここ数年の流れとして、GPUを積んだ専用サーバではなく、スマートフォンやPC、組み込み機器など深層学習モデルを動かすための、軽量化や処理削減、専用チップの開発も、テーマとして活気付いています。
一般物体認識と特定物体認識
ここまで見てきたのは、あるものを一般名詞などのカテゴリ(ねこ、いぬ等)に識別、分類するものでした。それだけでなく、固有名詞をもつモノ(東京タワー、エッフェル塔等)の識別もあります。顔写真からの人名推定もそのひとつと言えるでしょう。
2018年5月までKaggleで開催されたLandmark Recognition Challengeはその一例です。数万枚の写真から、10000もの名所旧跡を検出、分類します。
画像/映像 - 生成系: AIの描き出すもの

さて、前出のImageNet LSVRC 2012から2年、2014年6月にIan Goodfellow氏によりGenerative Adversarial Network(GAN)が発表されました。ざっくりというと、これは画像を含む、様々なものを生成することのできるモデルです。画像は、最初は低解像度であり、粗も目立つものでしたが、その後数年で、GitHubにthe GAN zooというリポジトリができるほど手法は乱立し、驚くべき進化を遂げています。ここから、そんな生成の最前線を見ていきます。
Progressive GANは2017年10月に発表、画像の滑らかさ、高解像度で目を惹きました。
「ラーメン二郎」という一部熱狂的固定ファンを持つラーメン屋があります。店舗ごとに微妙にアレンジが違うらしく、それをGANで生成し、つなげたビデオがあります。
ラーメンのみならず、アニメキャラクターや、
アイドル顔写真の自動生成(データグリッド社)まで行われています。
クリエイティブプロセスへの活用
漫画家や、アニメータのハードワーク環境がしばしば取り上げられます。また「AIが仕事を奪う」という言説もしばしば。「AIと人の共同作業」が模索されています。
こちらはラフスケッチから線画を自動作成します。
PFN @tai2an氏のサイドプロジェクトから始まり、2017年1月発表の後、機能や美しさに磨きをかけるPaintsChainerは、線画を与えると自動着色してくれます。完全自動に任せるのではなく、領域ごとに、色のガイドを与えることもできます。
発展させると、静止した漫画風の絵だけでなく、こうした映画への着色もできます。こちらはSIGRAPH 2016論文のモデルを「ローマの休日」に適用したものです。
自然な着色がされていることに驚かれるかと思います。ただ、実はよく見ると、同じ衣服のはずが場面により色が変わってしまっているもの、色の判断がつかず、ねずみ色に近い着色となっているものがあるのに気付きます。
デモとして、「すごいね」と驚く分にはいいのですが、例えば昔の映像を、時代考証に基づき着色する、などのガチタスクには適用できません。そうした課題に目をつけたRidge-i社は、NHKの「映像の世紀」を映像着色AIで支援しました。こちらは完全自動で着色してしまう、のではなく、キーフレームでの色指定は人が行い、キーフレーム間の映像は機械学習による生成で着色する、という人と協働するAIです。
どんどん生成系のデモ紹介を続けます。SuperSloMo(2017年11月)は、キーフレームの間を補間し、フレームレートを上げ、超スローモーション映像を後から作ることができます。
画像や映像のアップサンプリング(高解像度化)を行うこともできます。こちらはSRGAN(2016年9月)のデモです。左が元映像、右が生成された高解像度映像です。輪郭などにシャープネスフィルタなどをかけただけではない、テクスチャの生成が見られます。
こうした「超解像」の技術手法をまとめたスライドも、最近発表されました。
認識と生成のはざまに

Adversarial Examples
ここまで生成系のデモを見てきました。生成される画像/映像の自然さに驚かれされます。実はこれを発展させて、人間には普通に見えるが、機械学習モデルだけは騙される、という巧妙な罠=Adversarial Examplesを仕掛けることができます。

Deepfake 捏造や"アイコラ"問題
例えば、重要な選挙期間中に、対立候補を貶めるために映像をでっち上げSNSに放流すれば、その事実検証とは別に、一定のネガティブインパクトを与えることができるでしょう。Deepfake(Wikipedia)という名前で、いわゆる「動画版のアイコラ」が、政治、ポルノで悪用されることが問題視されています。
そんなことが本当にできるのか。関連の技術を見ていきます。SNOWやTikTokなどの動画編集・発信アプリでは、顔や体型を自在に「盛れる (=好きなようにモーフィングする、変形する)」ものがでてきており、その延長線上に、こうした技術があることは不思議ではありません。
Deep Video Portraits [SIGRAPH 18]
ターゲットの顔の表情や動きを、他人の演じるもので置き換える技術があります。
不正な映像を見破るFaceForensics
ただ、それを見破るという研究もあります。映像が人工的に書き換えられた疑いのある部分を抽出します。
判断根拠や解釈可能性
機械学習モデルをビジネスに適用する現場では、ブラックボックスで精度をあげるのか、ある程度説明性を重視して精度を犠牲にするのか、という判断に迫られることがあります。
人が見ている画像を脳活動から推定
画像/映像系の最後に、少し毛色の違うものを紹介します。被験者が見ている映像を、脳活動から復元する実験です。左側が実際に見せている映像、右側が復元映像です。近年、fMRIイメージングの解像度が飛躍的に増しており、NICTはそれを使った研究を進めています。
今回は発表の時間の関係もあり、これ以降の強化学習系、文章/言語系、音声/音楽系はデモの列挙にとどめます。より網羅的な紹介や説明は、第2回以降に予定しています。
強化学習: 行動を学ぶAI

人も、強化学習アルゴリズムも、何かを習熟するときの基本の流れは同じです。
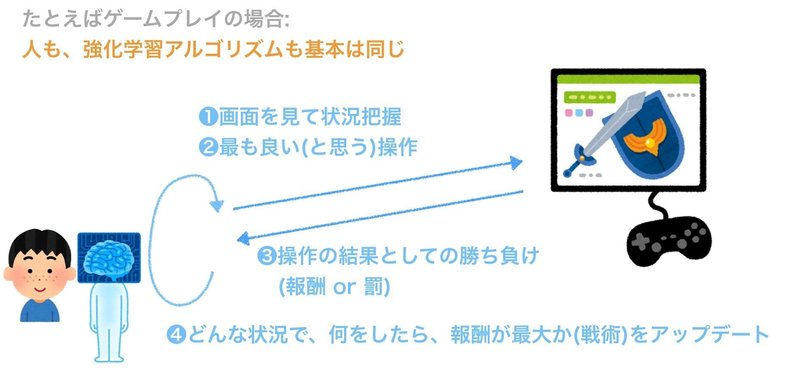
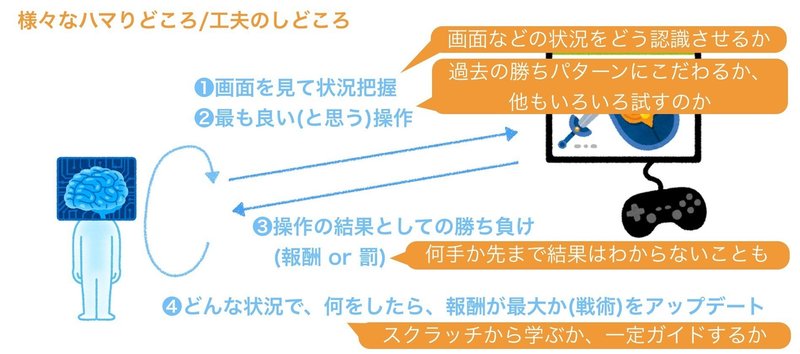
ただ、強化学習アルゴリズムには、まださまざまな課題があり、それらが日々研究の対象になっています。実社会での本格利用まではまだ、時間がかかりそうです。
Open AI Gymが、Gym Retroというコンシューマ機(ファミコン、メガドライブ、Atari他)のゲームに強化学習で挑むための環境を提供しています。ゲームは、ルールの複雑さ、一人プレイ、二人プレイ、多人数プレイと、難しくなっていきます。
ブロック崩し
より複雑な横スクロール型のアクションゲームではどうでしょうか。解説(英語)を含めたプレイ動画があります。
ここまでは一人プレイですが、多人数プレイのQuake III Arena CTFについてのAchievementでDeepMindが最近世を驚かせました。
DeepMimic [SIGRAPH18]
強化学習の適用範囲はゲームプレイだけではありません。ロボティクスや、プラントの操業等、他の研究分野もあります。まったくゼロから何かの動作を学習するのではなくお手本を与える、カリキュラム式に徐々に難しい課題を与えることで、スムーズに学習を進めるなど、様々な方法が提案されています。まるで、人間の子供に何かを教えるものに似ています。
音声/音楽系: AIの聴くもの、演奏するもの

音声/音楽は、二種類の入力に分かれます。波形を直接扱うもの、譜面のような系列データを扱うものです。前者は画像/映像を扱うモデルに近く、後者は文章/言語を扱うモデルに近いものを使います。
聴いたことのない音を、音楽にとりいれる: NSynth
これは波形を直接扱っています。
人間 vs AIのインプロ(即興演奏)合戦: A.I. Duet
これは譜面の系列データを扱っています。
驚くほど自然な歌声合成
初音ミクなどのVOCALOIDが一世を風靡しました。統計的手法が使われています。深層学習を用いた、より自然な歌声合成方法が発表されています。
文章/言語系: ことばを操るAI

従来の統計的手法から、深層学習を用いた方法の適用がはじまっています。グノシー、スマートニュースなど2012年頃から注目を浴びたキュレーションニュースでは、文章の分類を活用し、それぞれのニュースのカテゴリを自動分類するなどをします。
文章の要約は、まだ難易度の高いタスクと捉えられています。文章から、文を加工せず、重要文を抽出する、といったタスクは一定の成果を挙げています。
2016年12月にはGoogleが、従来の統計的機械翻訳から、ニューラルネットを使ったモデルを採用し、その性能向上や自然な翻訳が話題となりました。
NIPS 2017では、クイズ王者対決コンペが開催されました。優勝チームは日本企業で、こちらにコンペの模様が解説されています。
その他の領域: グラフほか
化合物の構造を推定したり、生成したりといったエリア、さまざまな知識、医療関係など、グラフで表す必要のあるデータがあります。それらに適用するGraph Convolutional Networkという仕組みがあります。
最近発表された、DeepMind Generative Query Networkも、ここまでのカテゴリにあてはまらないものといえるでしょう。
明日から最新の知見についていくには
ここまでのデモはいかがでしたか。今回の記事では、2018年6月時点で、私自身が面白いと感じたデモを中心に紹介しました。ただ、それで終わっては一時の知識で終了です。
興味をもった方がいたら、自律的に情報収集を続ける方法を紹介します。まず、人工知能/データ分析界隈における情報収集は、求める情報の鮮度別にいくつかのアプローチがあります。下の図をご覧ください。
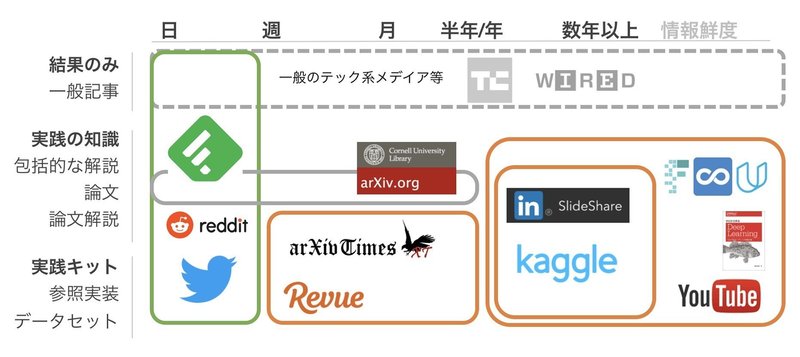
大きく分けて、日次、週次、月次、四半期、年次等で、追うメディアが異なります。
現状研究活動を生業にしていない私にとっては、
・日次: 趣味の領域
・週次〜月次: 最新情報を追うに十分
・四半期〜半年: 大きめの学会、付随する論文読み会、レビュースライド
・年次: CS231n(Stanford)や、MOOCsなどの講義、書籍
と捉えています。
フォローするメディアとしてはpiqcy氏が発行する週刊のメーリングリストが、おすすめです。筆者自身も毎週お世話になっています。
cv.paperchallengeは、産業総合研究所の片岡氏を中心に、学生、研究員総勢30名が関わるプロジェクトです。CVPR2018(2018年6月)の速報スライドは163ページにもわたり圧巻です。冒頭2018年現在の研究トレンドが噛み砕いて紹介されており、一読の価値があります。
より腰を据え、探索の幅や深さを求めたい方には、こちらの大学修士1年生向けレクチャスライドがおすすめです。どのようにArXivの論文をキャッチアップするか、また各学会のまとめ情報をどうフォローし、研究トレンドを追うか等が紹介されています。p.23〜の今すぐフォローすべき論文紹介Twitterアカウントは、とりあえずフォローしてみるのがおすすめです。一定アクティブなTwitterユーザであれば、息をするように最新の情報がフィードされることでしょう。
トレンドを追いかけるだけでなく動かしたい
情報収集をしていると、「自分でも何らか動かしたい!」となるものです。以前は、その段階で様々な壁にぶちあたることになりました。
・GPUマシンを持っていないと、チュートリアルより先に進めない
・環境構築時に、ライブラリのバージョン違い等で時間を溶かす 他
ですが、2017年12月から、GoogleがColaboratoryというサービスでPython3/GPUインスタンスを解放したことで、初学者でも環境構築不要でとりあえず動かしてみることができるようになりました。また、以前は英語でのレクチャ、教材しかありませんでしたが、日本語リソースも徐々に増えてきました。例をあげます。
データ分析系、無料の学習リソースは、東大松尾研の公開するものがおすすめです。下記は、それをColaboratory上で動かす方法です。
こちらは、Colaboratory上、対話型でソースコードを確認しながら試せる実装を集めたSeedbankから、今回の画像/映像系、音声/音楽系、文章/言語系それぞれのデモをまとめた記事です。
深層学習について、理論含めしっかりと理解したい方には、こちらがおすすめです。
文章/言語を扱えるRNNを取り上げた第二弾がまもなく発売です。私も読む予定です。
それぞれの活用については、需要があれば次回以降に解説します。
なお、英語リソースは、日本語と比べとても層が厚いです。edX、Udacity、Udemy、CourseraなどメジャーなMOOCsはそれぞれ講座を持っており、有名どころではAndrew Ng氏の手がけるdeeplearning.aiが挙げられます。また、Stanford大学のCS231nは、毎シリーズで講義動画が更新されており、最新の知見に触れられます。
個人的なおすすめは、元Kaggle CSOのJeremy Howard氏、USFのRachel Thomas氏が提供するfast.aiです。University of San Franciscoでの講義動画が無償公開されおり、Forumで独習者をフォローするコミュニティも構築されており、また教え合うだけでなく、新たなアイデアも生まれています。最新の下記2018年版はPyTorchを採用していますが、Kerasが使われた2017年版動画もアーカイブされており、視聴可能です。(Lesson 1のみ私が日本語字幕をつけています)
応用
数値系(データ分析)の動向
また、先にKaggleのくだりで触れたように、SlackやDiscordを用いたオンライン学習コミュニティが盛んに形成されているのも、ここ1-2年の特徴です。今や日本有数のデータサイエンス・コミュニティと言って良いだろうKaggler Slackは、あれよあれよと言う間に、参加者数が2000人を突破しました。
最近kaggler SlackによるWikiもスタートしました。過去ログもアーカイブされており、強いKagglersが、日本語で答える知見満載のログを読むことができます。Slackでは、初学者有志でコンペを行うなど、今後の展開が楽しみです。
画像/映像(畳み込みニューラルネットワーク)の研究動向
2017年12月 パターン認識・メディア理解研究会(PRMU)の発表資料です。JSAI Cup 2018で使われた手法も網羅されています。
2018年8月のMIRU 2018のチュートリアルセッションも、画像や映像を扱う深層学習手法について網羅的、実践的なチュートリアル資料です。用途は、本記事でも取り上げた、画像分類にとどまらず物体検出や姿勢推定まで、ShakeDrop/Cutout/Mixupなどの新しめの手法、RNN/3dconvによる時系列取扱、マルチタスクが扱われています。(貼って気付きましたが、両方中部大 山下先生が関わられていました)
文章/言語の研究動向
人工知能学会2018(2018年6月)のチュートリアルセッションのひとつとして発表されたものです。統計的手法ではなく、深層学習的アプローチが初歩から網羅的に解説されています。
強化学習の動向
Shibuya Synapse #3 (2018年6月)で発表されたものです。同イベントは網羅的に"いまの強化学習の姿"を捉えるものでした。
音声/音楽
Text-to-Speech(テキストからの発話合成)は、2017年~2018年4月までのディープラーニングを用いたText to speech手法まとめ - Qiitaが網羅的です。その他適用フィールドについて、良いものがあれば教えてください。
マルチモーダル
ここまであげたような、端的にいうと「人間の五感」複数を統合するような領域=マルチモーダルについてのレビュースライドはこちら。
お礼と次回へ向けて
筆者は、大学や研究機関に身を置いていません。数年来分析コンペ、MOOCs、書籍で独学を進めた一介のMachine Learning Enthusiastです。その過程で、断片的な知識や経験だった点と点がつながり、線として見え始めました。振り返り「こんな資料がまとまってたら嬉しかったな」「理解がよりはやく進んだのでは」と思った内容を、棚卸しを兼ねてまとめたものです。甘い考察、誤解などお気付きの点は、些細なことでもフィードバックいただけると幸いです。
今回、開催2週間程前にconnpassでイベントを公開したところ、「30人来たらいいかな」の想定を大きく上回り、100人以上の方の登録いただき、当日も80人超ご参加いただきました。至らぬ点も多々ありましたが、次回以降もよろしくお願いいたします。こちらのconnpassグループに登録いただければ、次回以降のイベント情報が配信されます。
末筆ながら、Venture Cafe Tokyo, Pegara Inc., Binnovativeのみなさまにお礼申し上げます。
この記事が気に入ったらサポートをしてみませんか?