
VRAM 4GBではじめるStable Diffusion - ゲーム素材を作ろう6 キャラにポーズを付ける

この草稿は、VRAM 4GB環境下で『Stable Diffusion』を利用して、ローカルでの画像生成をするためのものです。生成する画像はファンタジー系の同人ゲーム/インディーゲームの画像素材です。この草稿は、2023年の2月下旬~3月上旬にかけて執筆されました。
草稿をまとめて大幅増補したものを電子書籍で出しました。VRAMがなくても、Google Colabでも大丈夫なように対応しています。『Kindle Unlimited』ユーザーの方は無料で読めます。是非読んでください。
この草稿では『Stable Diffusion』の簡単な解説をおこない、『AUTOMATIC1111版 Stable Diffusion web UI』の導入や使い方について説明します。また「背景」「キャラクター」「アイテム」「絵地図」「UI部品」といった画像素材の作成方法を説明します。
この草稿は、私が2022~2023年に、同人ゲーム『Little Land War SRPG』を開発した時の知見を中心にまとめたものです。こちらも購入して遊んでいただけると幸いです。

本章の概要
本章では「ControlNetの導入」「ControlNetの利用」「ControlNetの各モデル」を扱います。
3Dデッサン人形の画像をもとに、実際にポーズを反映させる方法を、環境構築から順に見ていきます。また、ControlNetの各モデルの特徴や、いくつかのモデルで実際に画像生成する様子を示していきます。
以下、本章の目次です。
ControlNet
ControlNetの導入
モデルの入手と配置
使用手順
各Modelの簡単な説明
openposeの生成例
cannyの生成例
depthの生成例
scribbleの生成例
ControlNet
2023年2月半ばに登場した『ControlNet』を使えば、正確なポーズのデータを指定して画像を出力できます。『ControlNet』は、条件を追加して拡散モデルを制御するニューラル ネットワークです。
まずは『ControlNet』の導入方法を示します。
まず、VRAMが4GBの場合は「webui-user-my.bat」を修正する必要があります。「--medvram」ではメモリーが足らずにエラーが起きるからです。「--medvram」と書いている人は「--lowvram」に変更する必要があります。
:: set COMMANDLINE_ARGS=--medvram --xformers
set COMMANDLINE_ARGS=--lowvram --xformers注意すべき点としては、この原稿を執筆している時点では、学習モデルは1.5をベースにしたもののみが有効です。それ以外の学習モデルではエラーが出ます。これは、そのうち改善されるのではないかと思います。
ControlNetの導入
『Web UI』で「Extensions」タブを開きます。続いて「Install from URL」タブを開きます。
「URL for extension's git repository」入力欄に以下のURLを入力します。
「Local directory name」は空のままでよいです。「Install」ボタンをクリックするとインストールが始まります。2~3分でインストールは完了します。
『ControlNet』のファイルは、以下にダウンロードされます。サイズは12.3MBほどです。
<インストール先>/extensions/sd-webui-controlnet
ここでいったん『Web UI』を終了してください。Webブラウザーを閉じるだけでなく、コマンド プロンプトも終了します。
モデルの入手と配置
インストールしただけでは『ControlNet』は使えません。別途、モデルをダウンロードして配置する必要があります。
初期の頃は各5.71GBのファイルでしたが、その後、軽いモデルが登場しました。以下のURLから「.safetensors」と付いたファイルを全てダウンロードします。1つあたり723MBで、8種類あります。
https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main
ダウンロードしたファイルは、以下のパスに配置します。
<インストール先>/extensions/sd-webui-controlnet/models/
ファイルの配置が終わったら『Web UI』を起動してください。モデルが利用できる状態で『Web UI』が起動します。
「txt2img」タブの中に「ControlNet」という項目が増えています。クリックすると設定が開きます。以下、『ControlNet』の使い方を説明します。
使用手順
『ControlNet』の使用手順を書きます。
「txt2img」タブを開きます。これまでと同じように「Prompt」や「Negative Prompt」を入力します。また、その他の設定をおこないます。
「ControlNet」をクリックして設定を開きます。「Image」領域に、ポーズの参考にする画像をドロップします。
「Enable」チェックボックスにチェックを入れて『ControlNet』を有効にします。また「Low VRAM」チェックボックスにチェックを入れて低VRAM環境でも動作するようにします。
「Preprocessor」と「Model」を設定します。この2つは対になっています。たとえば「Preprocessor」で「canny」を選んだ場合は、「Model」の項目で名前に「canny」と入っている「control_canny-fp16」を選びます。基本的に、同じ名前が入っている「Model」を選べばよいです。
「Preprocessor」と「Model」についてもう少し詳しく書きます。『ControlNet』では、「Preprocessor」で「Image」の画像を事前処理して中間画像を作ります。そして、この中間画像を元に「Model」で処理をおこない、「txt2img」の画像生成をコントロールします。
中間画像は、他の生成画像と同じように出力されます。そして中間画像を保存しておけば再利用できます。「Image」に中間画像をドロップして、「Preprocessor」を「none」にすれば、「Preprocessor」の処理を飛ばして画像を生成できます。覚えておくとよいです。
その他の設定は、基本的には変更する必要はありません。必要と思った時に変更してください。
各Modelの簡単な説明
以下に、各「Model」の簡単な説明をまとめておきます。これらは『ControlNet』の『GitHub』のページに詳細が書いてあります。
lllyasviel/ControlNet: Let us control diffusion models
https://github.com/lllyasviel/ControlNet
私が使った印象では「scribble」が使いやすかったです。
canny(Canny Edge 検出)
入力画像の輪郭線を抽出して、その線に従った画像を生成します。
2次元イラストや、境界のはっきりした3D画像に向いています。かなり上手くポーズを拾ってくれます。
depth(深度マップ)
入力画像の深度情報を抽出して、その深度に沿った画像を生成します。
カメラで撮影した写真に向いています。奥行きを持ったレイアウトを反映したい時に使えます。
hed(ソフト HED 境界)
入力画像のエッジ検出(ソフトエッジ)をおこない、大雑把な輪郭と形状を抽出します。
元の画像に大きく引きずられるために「色だけ変えたい」といった用途に使います。キャラクターのポーズを付ける用途には向いていません。
mlsd(M-LSD 直線検出)
入力画像の直線検出をおこない、直線で構成された画像を抽出します。
パースが入った屋内画像から、同じパースの屋内画像を作るといった用途に使います。建物向けです。キャラクターのポーズを付ける用途には向いていません。
normal(法線マップ)
入力画像の凸凹を検出して、同じような立体構造を持つ画像を生成します。
「depth」より、よい結果が出る傾向にあります。背景は、多くの場合で無視されます。3Dのデッサン人形や、マネキンの写真といった画像からポーズを付けるのに向いています。
openpose(人間のポーズ)
入力画像から色付き棒人間の画像を作り、そのポーズに沿った画像を生成します。
関節位置をかなり正確に認識してくれます。ただし、最終出力画像は、このポーズに正確に従うわけではありません。あくまで参考程度といった印象です。
scribble(落書き)
落書きをもとに、ポーズを再現してくれます。ポーズ人形からでも、かなりよい結果を出せます。
「Preprocessor」の「fake_scribble」(偽の落書き)は、入力画像から落書き風の画像を作ったあと、その入力を元に「Model」「scribble」を利用します。「fake_scribble」を使うことは、あまりないでしょう。
seg(セマンティック セグメンテーション)
写真から領域を検出して、その領域に合わせた画像を生成します。
写真のレイアウトに合わせて、建物を違うものにするなどの用途に適しています。
各「Model」の簡単な説明は以上です。
以降では、いくつかの「Model」を使った画像生成と出力結果を見ていきます。
openposeの生成例
「openpose」は人間のポーズを認識してくれます。「Preprocessor」を「openpose」にして、「Model」を「control_openpose-fp16」にします。
私の環境では、入力画像が灰色のデッサン人形では上手くいきませんでした。デッサン人形を肌色に着色すると上手く認識しました。
以下、生成に使った呪文です。
masterpiece, best quality, concept art, extremely detailed,
(watercolor:1.2), (oil painting:1.1),
one fantasy girl, young little girl,
long wavy hear, dress costume,
beautiful perfect symmetrical face,
small nose and mouth, aesthetic eyes,
sharp focus, realism, 8k,
(style of granblue fantasy:1.1),
(style of genshin impact:0.9),
(style of renaissance:0.7),
(style of gothic:0.6),
(style of high fantasy:0.5),
artstation, deviantart, pixiv ranking 1st,bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, missing fingers, bad hands, missing arms, long neck, Humpbacked, shadow, flat shading, flat color, grayscale, black&white, monochrome, まずは「Preprocessor」を「openpose」にした場合です。
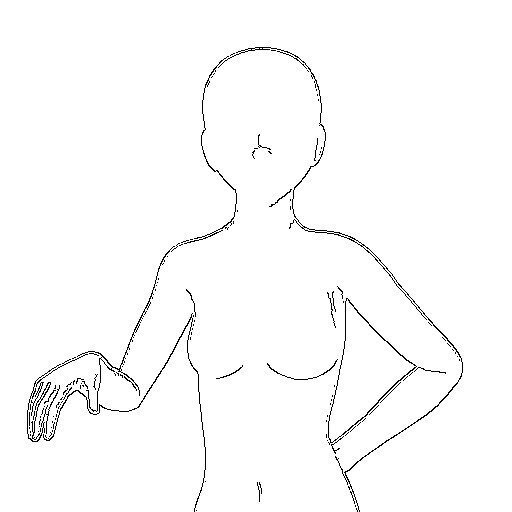
以下、入力画像、中間画像、出力画像です。ポーズはあまり上手く反映されませんでした。特に手がぐちゃぐちゃになりやすかったです。出力画像は、数多く出力したうちの1枚です。
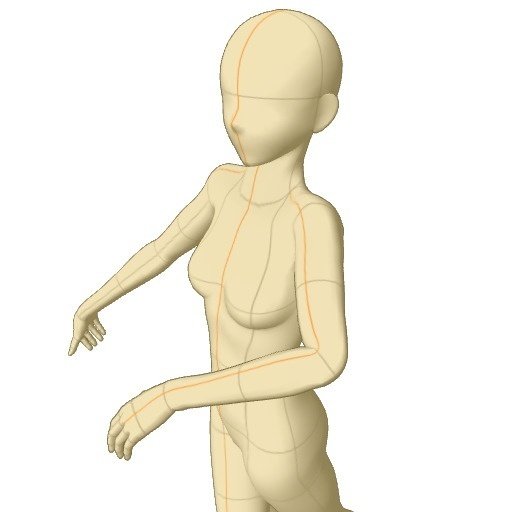
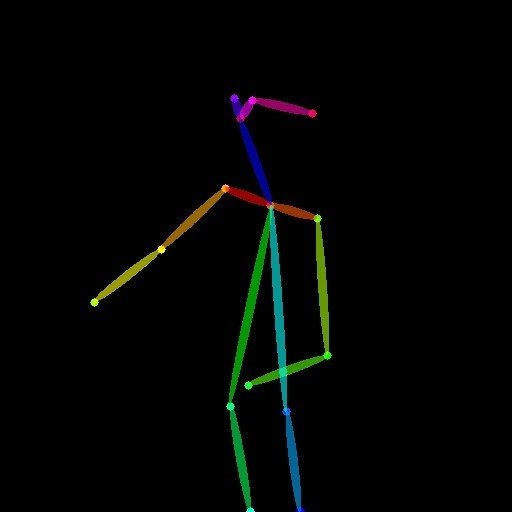

一度生成したあとは、出力された色棒人間の画像を入力にして、「Preprocessor」を「None」にすれば、事前処理なしで、そのポーズの画像を生成してくれます。
cannyの生成例
「canny」は入力画像から中間画像として線画を作り、その線画に沿った画像を生成します。「Preprocessor」を「canny」にして、「Model」を「control_canny-fp16」にします。
入力画像には注意が必要です。入力画像にモデル人形の縦線や横線が入っていると、その線を線画に含めてしまうことがあります。その際は出力画像にも線が反映され、体の中央に太い線が入った画像が生成されます。
たとえば『CLIP STUDIO PAINT』では、ポーズ人形に縦線や横線が入っています。特に頭から股までに入っている線は色が異なるために、線画に取り込まれやすいです。こうした現象を避けるには、ポーズ人形の設定で、「環境」の「レンダリング設定」を開き、「テクスチャを使用する」のチェックを外すとよいです。
また「openpose」と違い、「canny」ではグレースケールの画像できちんとポーズを認識してくれました。
「canny」で困るところは、ポーズ人形を入力にすると、その頭と体の形をそのままなぞろうとしてしまうことです。髪型は、ヘルメットを脱いだ直後のような形になり、体も裸になったり体型にぴったりな服になったりします。「Guidance strength」を低くするか、最初から服を書き込むなどした方がよいです。
以下、生成に使った呪文です。「Negative prompt」は「openpose」と同じです。
「(long wavy hear:1.8), (dress costume:1.9),」として、かなり強い重みで髪や服を足しています。しかし、その効果は薄いです。
masterpiece, best quality, concept art, extremely detailed,
(watercolor:1.2), (oil painting:1.1),
one fantasy girl, young little girl,
(long wavy hear:1.8), (dress costume:1.9),
beautiful perfect symmetrical face,
small nose and mouth, aesthetic eyes,
sharp focus, realism, 8k,
(style of granblue fantasy:1.1),
(style of genshin impact:0.9),
(style of renaissance:0.7),
(style of gothic:0.6),
(style of high fantasy:0.5),
artstation, deviantart, pixiv ranking 1st,以下、入力画像、中間画像、出力画像です。手が忠実に反映されているのは非常によい点です。出力画像は、数多く出力したうちの1枚です。裸の画像が多く、服を着たものを得るために何度も出力しました。


「canny」では、一度生成した時の中間画像を入力にして「Preprocessor」を「None」にした場合は、きちんと認識してくれませんでした。ものすごくまれに成功することもありますが、抽象的な画像が生成されることが多かったです。
depthの生成例
「depth」は深度マップを作り、画像を生成します。「Preprocessor」を「depth」にして、「Model」を「control_depth-fp16」にします。
デッサン人形を使い「depth」で画像を生成する際には気を付けないといけないことがあります。そのままデッサン人形の画像を使うと、顔が後頭部と認識されて、頭部だけ後ろ向きのホラーな画像が生成されます。これは、デッサン人形には目鼻の凹凸がほとんどないために顔の正面と認識されないためです。
デッサン人形を使う場合は、目と口の位置を書き込むとよいです。そうすれば、そこに顔の正面があると認識してくれます。
生成に使った呪文は「canny」と同じです。以下、入力画像、中間画像、出力画像です。こちらも「canny」と同様、モデル人形の輪郭に強く引きずられます。



「depth」では、一度生成した中間画像を入力にして、「Preprocessor」を「None」にすれば、事前処理なしで、そのポーズの画像を生成してくれます。
scribbleの生成例
「scribble」は落書きをもとに、いい感じに画像を生成します。「Preprocessor」を「scribble」にして、「Model」を「control_scribble-fp16」にします。
「scribble」は、「canny」の高精度に、多様性をプラスしたような感じです。かなり優秀な結果が出ます。
生成に使った呪文は「canny」と同じです。
以下、入力画像、中間画像、出力画像です。大枠は従いながら、呪文の指示に柔軟に従ってくれます。



「scribble」も、一度生成した中間画像を入力にして、「Preprocessor」を「None」にすれば、事前処理なしで生成してくれました。
(続く)
全体目次
第1章 環境構築
第2章 基礎知識
第3章 呪文理論
第4章 背景画像の生成
第5章 キャラクター画像の生成
★★★第6章 キャラにポーズを付ける★★★【今ここ】
第7章 キャラを学習させる
第8章 武器や道具の生成
第9章 絵地図の生成
第10章 UI部品のテクスチャの生成
※ 草稿をまとめて大幅増補したものを電子書籍で出しました。VRAMがなくても、Google Colabでも大丈夫なように対応しています。『Kindle Unlimited』ユーザーの方は無料で読めます。是非読んでください。
この記事が気に入ったらサポートをしてみませんか?