
劇場・音楽堂!Webサイトから文化施設の情報をスクレイピング

協会概要
「公益社団法人 全国公立文化施設協会」(略称 全国公文協)は、従前の任意団体「全国公立文化施設協議会」を母体として、平成7年6月26日に文部大臣の認可を得て発足し、平成25年4月1日内閣府の認定を受け、公益法人に移行しました。日本全国の国公立文化施設の連携の下、地域文化の振興とわが国の文化芸術の発展に寄与することを目的に各種事業を行っています。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
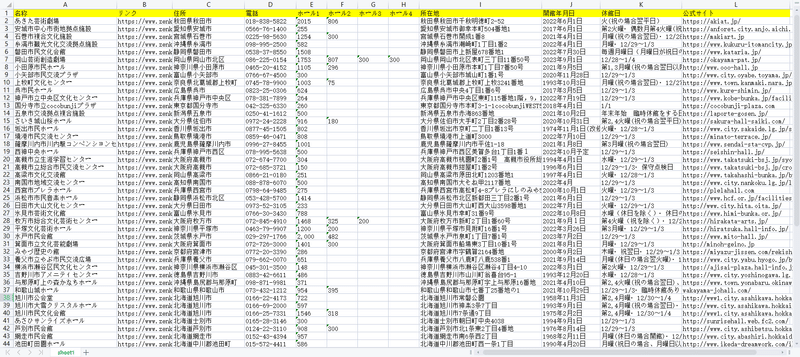
抽出されたデータは下記のようにご覧ください。
1.タスクを新規作成する
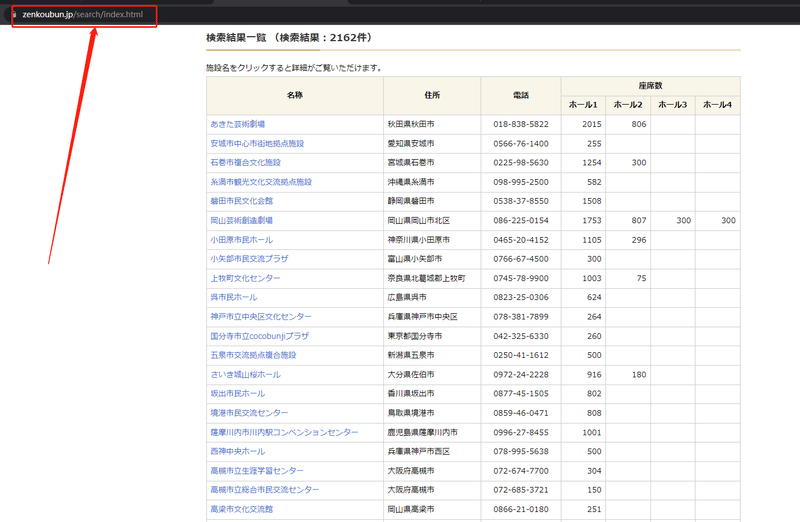
(1)URLをコピーする
今回は全国公立文化施設検索の検索結果一覧ページを例として、スクレイピング方法を紹介します。まず、URLをコピーしてください。
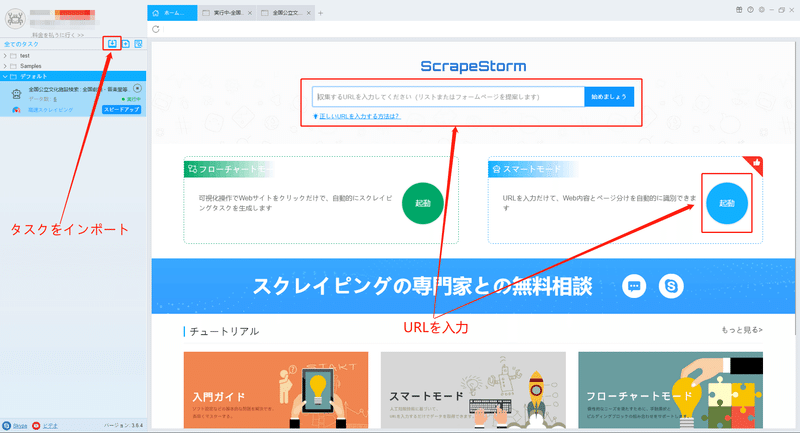
(2)スマートモードタスクを新規作成する
ScrapeStormのホムページ画面にスマートモードタスクを新規作成します。また、持っているタスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
スマートモードタスクの新規作成方法
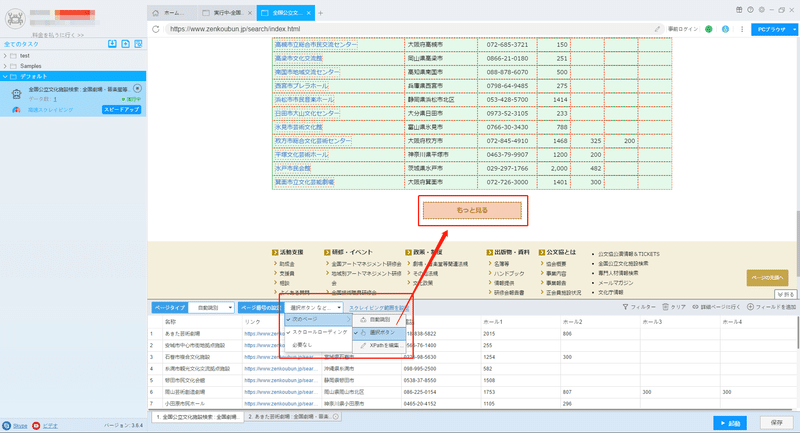
2.タスクを構成する
(1)ページボタン
ScrapeStormは自動的にリスト要素とページボタンを識別できます。もし識別誤差が発生する時、手動でページボタンを選択してください。下記のチュートリアルも参照してください。
ページ分けの設定方法
(2)詳細ページに行く
所在地、開館年月日、休館日などの詳細情報は詳細ページに付いていますから、ソフトウェアの「詳細ページに行く」機能を利用して、データを抽出します。
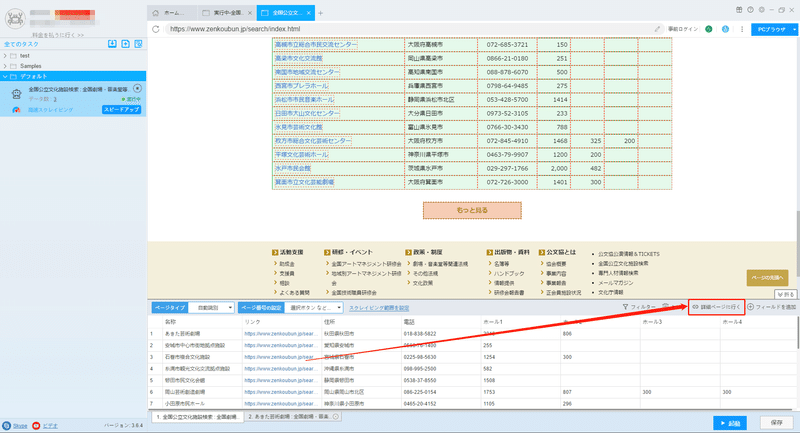
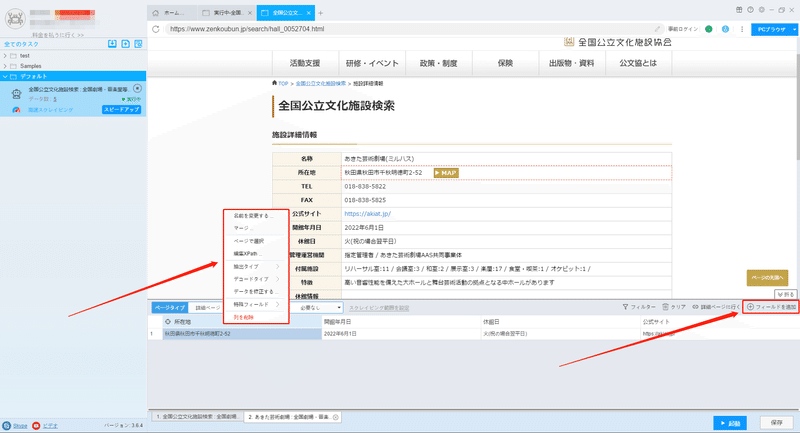
(3)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法
3.タスクの設定と起動
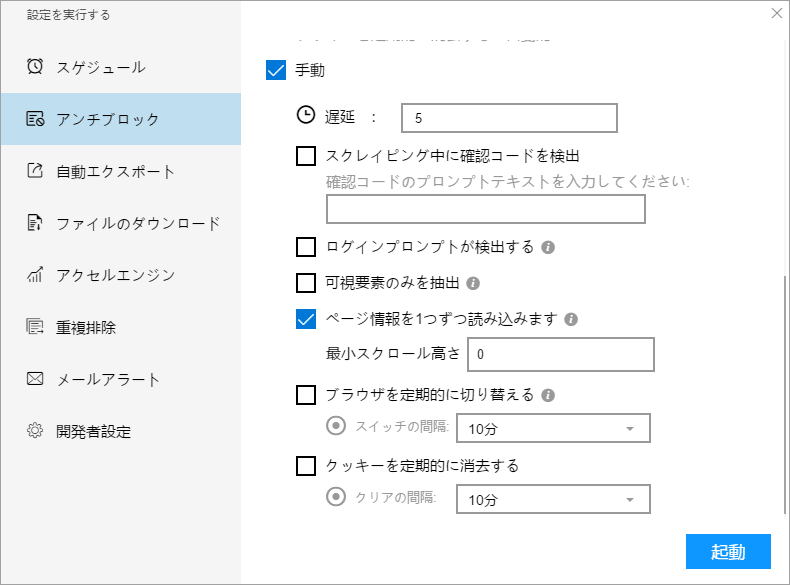
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。サーバーに負荷しないように、遅延時間を設定してください。5秒以上を推薦します。スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法
(2)しばらくすると、データがスクレイピングされる。
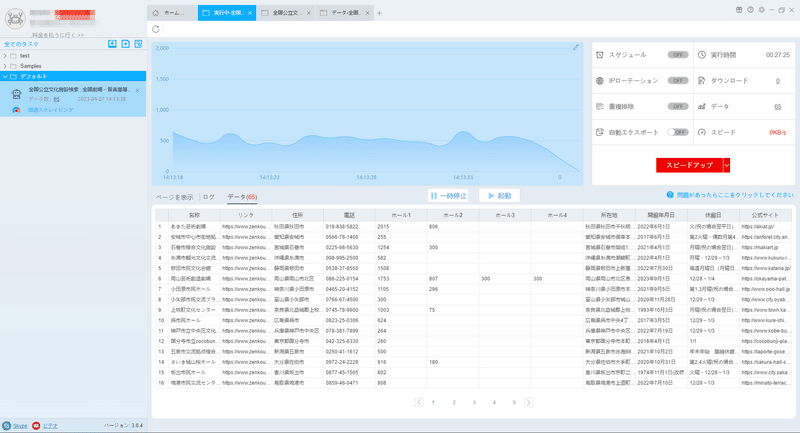
4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする
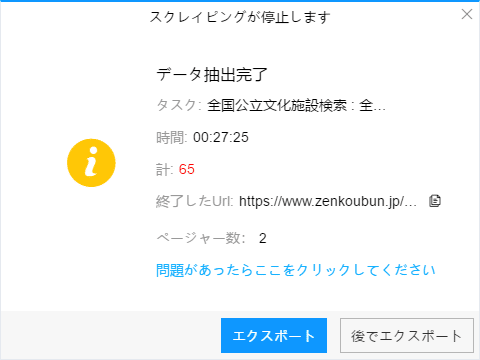
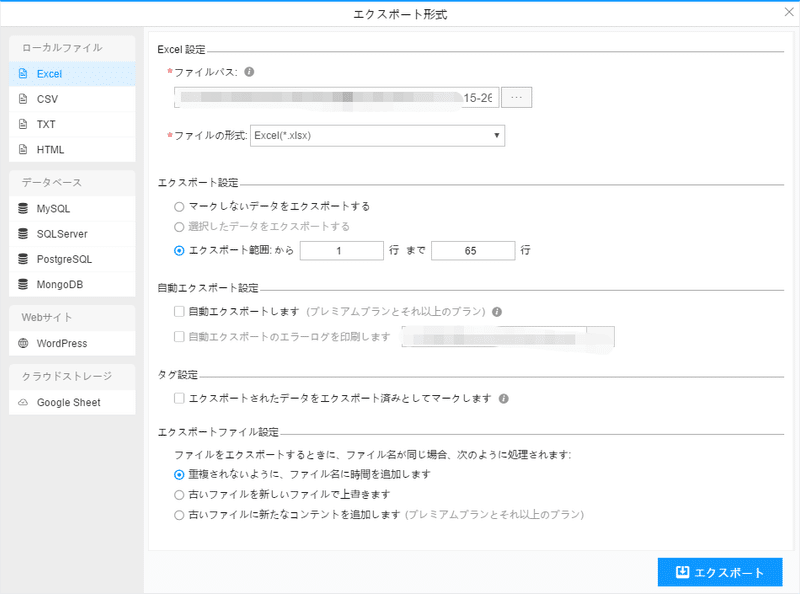
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法
注意:法律違反しないため、抽出されたデータを悪用禁止です!
この記事が気に入ったらサポートをしてみませんか?