pythonで機械学習「kaggle TPS May vol.1」

前回のTPSは全く歯が立たなかった。700位くらい。RNNを使えるようにならなきゃ。でも焦らず、NNの基礎から確認したい。
今回も2値分類で、評価指標はAUC。データ数多いし、ニューラルネットワークでリベンジだ。
内容は、
For this challenge, you are given (simulated) manufacturing control data and are tasked to predict whether the machine is in state 0 or state 1. The data has various feature interactions that may be important in determining the machine state.
製造用機械がある。31種のコントロールデータから、この機械の状態が0であるか1であるかを予測せよ。

train 90万行に対し、test 70万行。

id、target以外の特徴量は、31種類。
floatが16種。intが14種。objectが1種。

target見てみると、ちょとだけ0が多いが、ほぼ半々。
特徴量をちょっと深掘り。
まず、気になるobjectのf_27。
なにやら10桁のアルファベット。
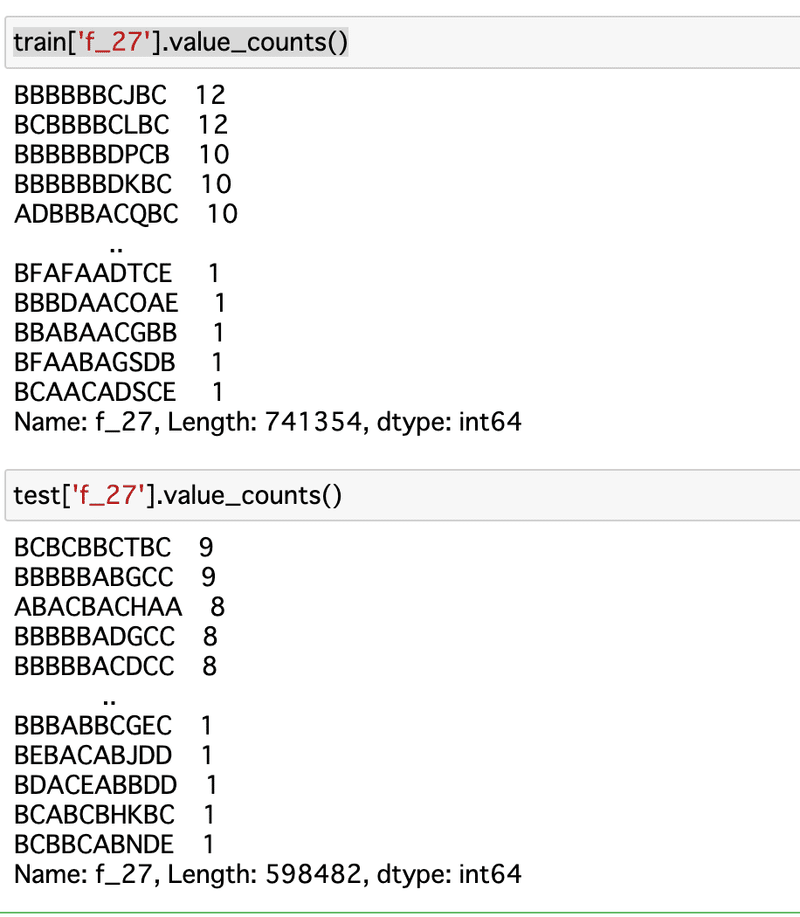
ほとんどは一回か二回だけど、何回も登場するものもあるようだ。

ベースライン確認するために、一回モデルを作り、予測する。
f-27は一旦除外する。
その他の特徴量はStandardScalerで標準化する。
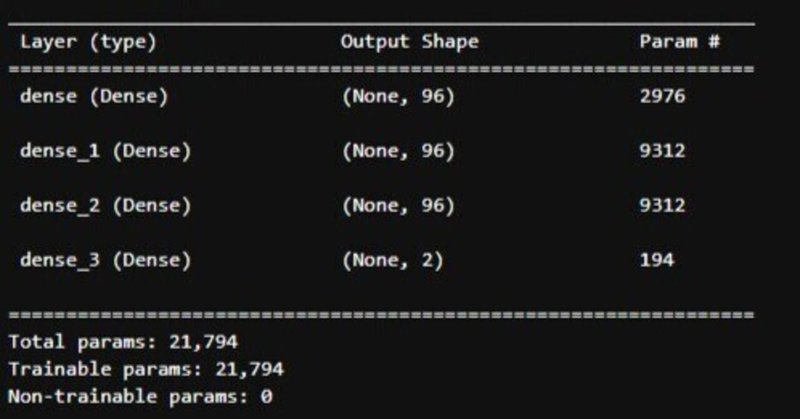
モデルの構造は以下の通り。

学習率0.01でコンパイルし、エポック数20で学習。

予測して、Kaggleに投稿してみると点数がやばいことになった。

ようするに、完全に逆の答えを予測している。なにか設定間違えたと思ったけど、ただの凡ミス。これ出力、2列じゃん。0、である確率を投稿してしまっている。修正すると、

うん、こんなもんか。
今回は0.99台に行かないといけないな。
次回は、この記事参考にしながら進めようか。
この記事が気に入ったらサポートをしてみませんか?