「ももたろう」でテキストマイニングを勉強してみよう!

以前、テキストマイニングにチャレンジしてみました。
自分であそんでみるだけや、なんちゃって資料をつくるだけならココまでで十分かもしれませんが、実際マトモに利用するためにはもうちょっと勉強が必要かなと思いました。理解を深めてみましょう。
テキストマイニング入門
新しく良い本がみつかりましたので購入しました。
わたしの一押し、オーム社さんのマンガです!はじめてテキストマイニングに触れるにはとっつきやすいです。ありがとうございます。
そもそもなぜテキストマイニングなのか。私は本書籍を読んで、こう理解しました。

定量データ(数字)と定性データ(文章)はどちらが優れているというものではなくどちらもバランスよく利用するのが大事。
定量データについては以前よりグラフや表にしたりと分析方法が色々あってExcelをはじめ便利なツールも豊富。反面、定性データを分析するのは難しく、やろうと思ったら力業でキーワードを拾ったりするか、高価なテキストマイニングツールが必要でした。
要するに今までの分析手法は定量データに偏っていた!
それが今では「KH Coder」のようなフリーソフトウェアも利用できるようになり、ついに定性データも定量データと同じように気軽に分析できるようになったのです!!
「ももたろう」をテキストマイニング
今回は、みんなが知ってる「ももたろう」を題材にテキストマイニングをやってみます。青空文庫からダウンロード。いつもありがとうございます。
次にダウンロードファイルを展開して、不要部分を削除して分析しやすいようにテキストデータに少し手を加えます。
ここでは青空文庫から20作品をダウンロードして、以下のようなクリーニングを行いました。ファイルの冒頭と末尾に付いている説明・日付を削除しましたが、冒頭の作品タイトルと著者名は残しました。そして、テキストエディタ「秀丸」の正規表現を用いた置換機能で、以下の正規表現を空の文字列に置換しました。ルビ・注釈に加えて、見出しをインデントするための全角スペースを削除しています。
《.+?》|||[#.+?]|^ {2,}
その後、「〔」を検索してアクセントの除去を個別に行いました。またアルファベット([a-z,\.])と日本語文字([^\x01-\x7E])の間に挿入されている半角スペースについても除去しました。以上でクリーニングは完了です。
私が普段利用しているエディタも「秀丸」なので、上記を参考にクリーニングします。秀丸の正規表現での置換の仕方はこんなかんじ。
事前に検索で置換(除去)箇所を黄色くハイライトしてみました。

プロジェクトを新規作成し、KH Coder にとりこみます。
形態素解析エンジンは「MeCab」にしました。
前処理
テキストのチェック
前処理
前処理の実行

総抽出語数(使用):3,394(1,134)
異なり語数(使用):645(490)
集計単位:ケース数
文:262
段落:155
抽出語リストを確認すると、大事なアイテム「きびだんご」がうまく抽出できてません。又、「犬」「猿」はいるのに「きじ」がいませんね。あれれ?

そこで「きびだんご」を強制抽出することにします。

前処理の実行

総抽出語数(使用):3,402(1,128)
異なり語数(使用):641(487)
集計単位:ケース数
文:262
段落:155
「きびだんご」が抽出されました。

「きじ」を抽出語リストで調べると「名詞B」となっていました。
ひらがなの名詞は「名詞B」となるようです。

抽出語リスト・フィルタ設定の名詞Bにチェック

「きじ」があらわれました。おじいさんとおばあさんも出てきましたね。

ひらがなは、わかち書きが難しいところがあるのか、ちょっと注意しておいた方がよいかもしれませんね。
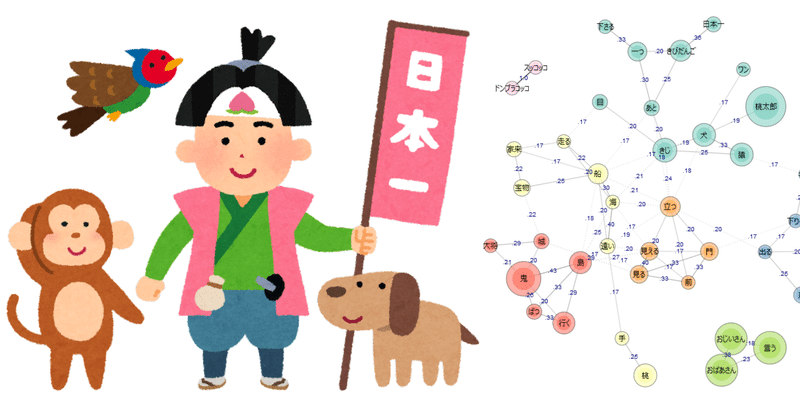
それではお楽しみ「共起ネットワーク」を描いてみましょう。
ツール
抽出語
共起ネットワーク
以下のように設定。
とくに名詞Bにチェックがあること確認してください。

共起ネットワーク!

おおお。仮に「ももたろう」のお話を知らなくても、なんとなくメインの登場人物やそれらの関係性がざっくり把握できるのがわかりますね。
では例として、「犬」「猿」「きじ」の関係性をみてみましょう。

「犬」「猿」「きじ」をつなぐ線の数字は「Jaccard係数」といいます。
Jaccard係数とは、「ある語」と「ある語」の関連性(類似性・共起性)の程度を表す指標です。
犬と猿のJaccard係数は、0.33
猿ときじのJaccard係数は、0.25
犬ときじのJaccard係数は、0.19
と表示されています。目安ですが、
「0.1」→「関連がある」
「0.2」→「強い関連がある」
「0.3」→「とても強い関連がある」
というのがひとつの基準です。
さらに関連語検索で確認してみます。
ツール
抽出語
関連語検索
「犬」に対する「猿」と「きじ」

「猿」に対する「犬」と「きじ」

「きじ」に対する「猿」と「犬」

犬と猿のJaccard係数は、0.3333
猿ときじのJaccard係数は、0.2500
犬ときじのJaccard係数は、0.1905
Jaccard係数の計算方法
冒頭紹介の「テキストマイニング入門」の付録(P212)に、わかりやすい説明があって自分なりにまとめようと思ったのですが、うまくまとめきれませんでした😅。ご興味ある方はぜひ書籍にてご確認ください。
で、こちらもわかりやすい統計ER様のリンクを紹介します。統計ER様ありがとうございます。
上記を参考に、ももたろうの「犬」と「猿」について書いてみると、
「犬」が12の段落に登場し「猿」が12の段落に登場している。
「犬」と「猿」が一緒に、6の段落に登場している。
この場合 Jaccard 係数は以下のように計算される。
ということになります。つまり

犬と猿のJaccard係数は、0.3333
お!計算は合ったっぽい!!
Excelで検証してみよう!
Excelを使って「犬」「猿」「きじ」それぞれでも検証してみます。

結果がこれ。
じゃん!

おおっ!ちゃんとKH Coderの結果と一致しました。やったー!
なるほどー。Jaccardの計算の仕方が自分でもちょっとわかりました。😆
どっか違ってたら教えてください。^^;
最後に
「テキストマイニング入門」のあとがきを引用します。
ツールを扱うことは、自転車に乗ることや料理を作ることと同じ「スキル」です。手順を踏めば誰でも習得可能な技術です。しかも、文章の分析に正解はありません。このテキストマイニングのスキルを自由に駆使して、想像力と洞察力を働かせながら、さまざまな文章の分析にチャレンジしてみてください。
末吉美喜先生ありがとうございます。大変勇気づけられます。
私の大好きなITツール「kintone」にも通じる部分があるなあと思いました。
テキストマイニングって最初はよくわからなかったけどチャレンジしてみて前より少しはわかってきたような気がします!
この記事が気に入ったらサポートをしてみませんか?