ChatGPT + Embeddings で蜜源・花粉源に詳しいチャットボットをつくる 中編

すぐにチャットボットに触りたい方はこちら。
前編でembeddingの説明しています。
以下の図に全体のしくみをまとめました。順に説明します。
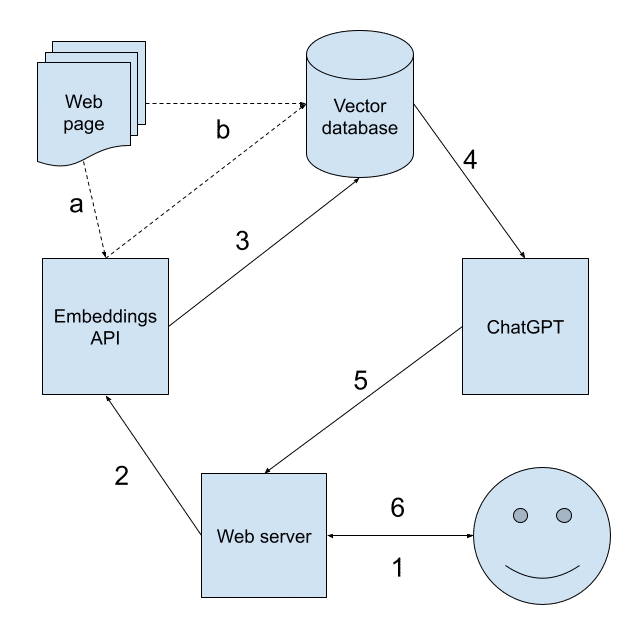
a: データベースのembedding
蜜源・花粉源 データベースは植物ごとに1ページになっています。
WordPressで作られているのでエクスポート機能でデータをxmlにエクスポート。その後、1アイテム(1ページ)ごと処理してcsv形式で保存。コードはPythonで書いています。
このデータベースはもう更新していないのでxmlにエクスポートして処理しましたが、更新がある場合はWordPressのプラグインなどにして更新ごとに処理する仕組みが必要です。(そのうち作るかも、要望あればください)
(以下のコード中、findの前後に空白が入っていますが、入れないと保存できないという謎現象のためです)
import xml.etree.ElementTree as ET
import re
# XMLファイルをパースしてElementTreeオブジェクトを取得する
tree = ET.parse('honeybeedb.wordpress.xml')
ns = {
'wp': 'http://wordpress.org/export/1.2/',
'excerpt': "http://wordpress.org/export/1.2/excerpt/",
'content': "http://purl.org/rss/1.0/modules/content/",
}
# ルート要素を取得する
root = tree.getroot()
channel = root.find ('channel')
title = channel.find ('title').text
siteurl = channel.find ('link').text
items = channel.findall('item',ns)
lines = []
#1植物ごと処理
for item in items:
postType = item.find ('wp:post_type',ns).text
status = item.find ('wp:status',ns).text
if(postType != 'page' or status != 'publish'):
continue
title = item. find('title').text
url = item. find('link').text
description = item. find('description').text
content = item. find('content:encoded',ns).text
excerpt = item. find('excerpt:encoded',ns).text
body = f"name:{title}\n"
postmetas = item.findall('wp:postmeta',ns)
for postmeta in postmetas:
key = postmeta.find ('wp:meta_key',ns).text
value = postmeta.find ('wp:meta_value',ns).text.replace("\n",'')
if(re.search(r'^[_]',key)):
continue
body += f"{key}:{value}\n"
line = {
'title': title,
'url': url,
'body': body
}
lines.append(line)
#csvファイルに保存
import pandas as pd
csvfile = 'honeybeedb.csv'
df = pd.DataFrame(lines)
df.to_csv(csvfile, index=False)処理のしかたは様々考えられると思います。今回の場合は、特にpost_metaの処理に工夫の余地がありそうですが、とりあえず適当に {meta_key}:{meta_value}としました。
いよいよここから embedding。OpenAIのEmbeddingsを使います。1アイテムごと1つのjsonファイルに書き出します。処理には多少時間がかかります。途中で失敗することもあったので、1ファイルごとに保存することにしました。
import openai
EMBEDDING_MODEL = "text-embedding-ada-002"
openai.api_key = OPENAI_API_KEY
openai.organization = OPENAI_ORGANIZATION
def embedding(query):
query_embedding_response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=query,
)
query_embedding = query_embedding_response["data"][0]["embedding"]
return query_embedding
df = pd.read_csv(csvfile)
import json
import os
#1ページごとembeddingしてjsonファイルに保存
vectordir = '/vector/'
for(index, title) in enumerate(df['title']):
filename = vectordir + str(index) + '.json'
if(os.path.exists(filename)):
print(filename, 'exists')
else:
print(filename,'notfound')
vector = embedding(df['body'][index])
with open(filename, 'w') as f:
json.dump(vector, f)
print(filename,'create')b: embeddingをベクトルデータベースに格納
embeddingしたファイルは全部で400個、12メガバイトあります。この程度の量でもデータベースに収めないと取り回しがわるいです。
ベクトルデータベースという便利なものがあるんですね。今回は Pinecone を使ってみます。
あらかじめ、PineconeのコンソールでIndex を作っておきます(API使って作ることもできます)。名前は適当に test 。Dimensionsはmodelに合わせて1536、Metricはcosine。
そしてデータベースに1件づつ格納します。namespaceはなくてもOKですが、他のデータとも使い回すならつけておいたほうが無難。
import ast
import pandas
import pinecone
pinecone_api_key = PINECONE_API_KEY
pinecone_environment = PINECONE_ENVIRONMENT
# Initialize Pinecone
pinecone.init(api_key=pinecone_api_key, environment=pinecone_environment)
# Connect to the index
pinecone_index = pinecone.Index("test")
df = pd.read_csv(csvfile)
import json
import os
for(index, title) in enumerate(df['title']):
filename = vectordir + str(index) + '.json'
if(os.path.exists(filename)):
print(filename, 'exists')
with open(filename, 'r') as file:
data = json.load(file)
v = (f"id_{index}",data,{"body": df['body'][index],"url": df['url'][index],"title": df['title'][index]})
pinecone_index.upsert(vectors = [v], namespace='beehappy-db')
else:
print(filename,'notfound')これでデータベースに格納できました。ここまでの作業はデータが更新されない限り一度だけ行えば良い作業です。
長くなってしまったのでこの先は別記事にしたいと思います。
Embeddingsの活用はこのcookbookを参考にしました。面白いのでぜひ読んでみてください。
2022北京オリンピックに関するwikipediaの記事を与えてそれについて答えるチャットボットを作っています。embedding済みのデータも配布されているのでちょっと試してみるのに良い教材になっています。
冒頭の日本語訳を載せておきます。GPT4で翻訳しました。Embeddingsを使って情報を与える方法を短期記憶と例えているのが興味深いです。
なぜ検索がファインチューニングより優れているのか
GPTは2つの方法で知識を学習することができます。
・モデルの重みを介して(つまり、トレーニングセットでモデルをファインチューニングすることによって)
・モデルへの入力を介して(つまり、知識を入力メッセージに挿入することによって)
ファインチューニングはより自然な選択肢のように感じるかもしれませんが、データを使ってトレーニングすることは、GPTが他のすべての知識を学習した方法です。しかし、一般的にはモデルに知識を教える方法としてはお勧めしません。ファインチューニングは特定のタスクやスタイルを教えるのに適しており、事実の記憶には信頼性が低いです。たとえば、モデルの重みは長期記憶のようなものです。モデルをファインチューニングすると、1週間後の試験の勉強のようなものです。試験が来ると、モデルは詳細を忘れたり、読んだことのない事実を誤って思い出すことがあります。
一方、メッセージの入力は短期記憶のようなものです。知識をメッセージに挿入すると、オープンノートで試験を受けるようなものです。ノートを手に入れると、モデルは正しい答えにたどり着く可能性が高くなります。
後編に続く。
この記事が気に入ったらサポートをしてみませんか?