
【VBA】OneNote操作(画像からテキスト抽出)

VBAでOneNoteを操作するコードサンプルです。
OneNoteのOCR(文字認識)機能を使って画像データからテキスト抽出する例と、OneNote上に画像データをアップロードする例を紹介します。
先に言ってきますが、OCR機能の精度(文字認識精度)はOneNoteに依存します。
※OneNoteは、Microsoft Office365に付いてくるメモアプリです。
OCR機能とは
画像データ(手書きや印刷文字の画像データ)内の文字を判別し、テキストを取得する機能です。光学式文字認識(Optical Character Reader)の略。
OneNoteでは、このOCR機能が標準搭載されています。
OneNoteに貼付けられた画像データは瞬時にスキャンされて、OCRテキスト情報としてOneNote内部に保存されます。通常は画像を右クリック>画像からテキストをコピー、で確認可能。
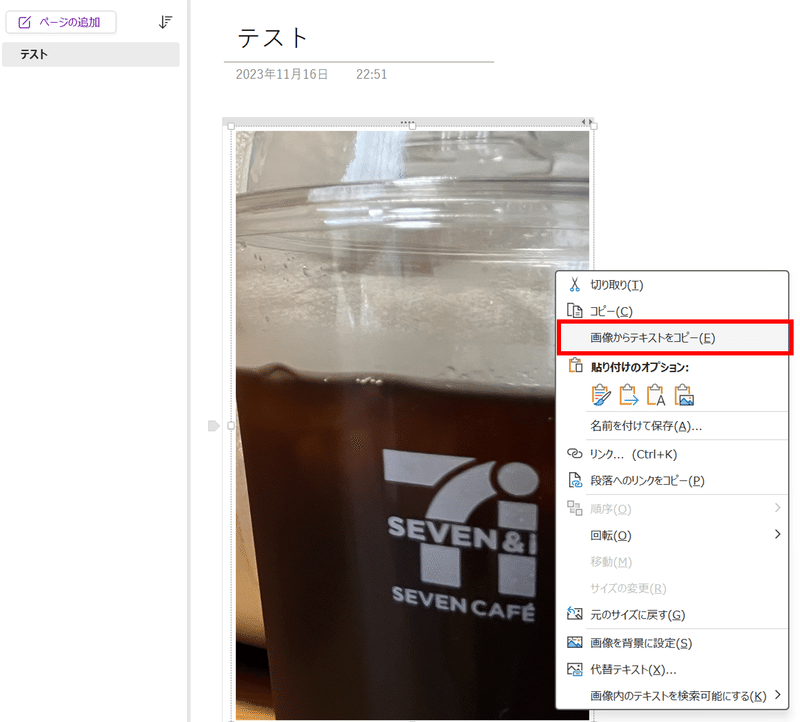
(この例だと、「SEVEN&i SEVENCAFÉ」とテキスト抽出できる)
このOCR機能(文字認識)を何かに活用できないかなーと思い、VBAで操作するサンプルを作りました。
OCRテキストを取得
OneNoteのOCRテキストを取得するコードがこちら。
Private Declare PtrSafe Sub Sleep Lib "kernel32" (ByVal dwmilliseconds As LongPtr)
'参照設定
'Microsoft OneNote 15.0 Object Library
'Microsoft OneNote 15.0 Extended Type Library
Private Sub OneNote_OCR()
'OneNote起動
Dim exec As Object
Set exec = CreateObject("Wscript.shell").exec("onenote.exe")
Sleep 1000
Dim app As OneNote.Application
Set app = New OneNote.Application
Sleep 3000
'OneNote全体のXMLを取得
Dim XML As String
Dim Doc As Object 'MSXML2.DOMDocument60
app.GetHierarchy vbNullString, hsPages, XML
Set Doc = CreateObject("MSXML2.DOMDocument.6.0")
Doc.LoadXML XML 'XML文字列をパース
Doc.SetProperty "SelectionLanguage", "XPath"
Doc.SetProperty "SelectionNamespaces", "xmlns:one='http://schemas.microsoft.com/office/onenote/2013/onenote'" '「one」の名前空間の指定
'ページタイトルから対象ページを特定
Dim node As Object 'MSXML2.IXMLDOMNode
Dim PageName As String
Dim pageID As String
For Each node In Doc.SelectNodes("//one:Page")
PageName = node.Attributes.getNamedItem("name").Text
If PageName = "テスト" Then
pageID = node.Attributes.getNamedItem("ID").Text 'pageIDをゲット
End If
Next
Set Doc = Nothing
If pageID = "" Then
Debug.Print "対象ページが見つかりませんでした"
Exit Sub
End If
'ページ内の全コンテンツを取得
Dim pageXML As String
app.GetPageContent pageID, pageXML
'OCRテキストを抽出
Dim nStart As Long
Dim nEnd As Long
Dim temp As String
Dim Cnt As Integer
Dim OCRs() As String
ReDim OCRs(0)
Do
nStart = InStr(nStart + 1, pageXML, "<one:OCRText>")
If nStart = 0 Then
Exit Do
Else
nEnd = InStr(nEnd + 1, pageXML, "</one:OCRText>")
temp = Mid(pageXML, nStart + 22, nEnd - nStart - 25)
Cnt = Cnt + 1
ReDim Preserve OCRs(Cnt)
OCRs(Cnt) = temp
End If
Loop
If UBound(OCRs) = 0 Then
Debug.Print "OCRデータが見つかりませんでした"
Exit Sub
End If
'OCRテキストを加工
Dim arr() As String
Dim i As Long
Dim j As Long
For i = 1 To UBound(OCRs) '画像ごとに処理
Debug.Print "画像 " & i & "個目"
arr = Split(OCRs(i), vbCrLf)
For j = 1 To UBound(arr) '改行毎に処理
Debug.Print j & ": " & arr(j)
Next
Next
'OneNote終了
exec.Terminate
Set app = Nothing
Set exec = Nothing
End SubOneNoteはXML形式で記述されているので、アプリケーション>ノートブック>セクショングループ>セクション>ページ>ページコンテンツと階層を辿っていけば、目的の画像にたどり着きます。
まずはgetHierarchyメソッドを使って、OneNoteの階層構造を取得します。
第一引数にnullを渡すとルート以下全てのノード(全ノートブック、セクション)が取得されます。第二引数は取得する範囲の下限値を定数で指定。第三引数がOutパラメーターで、ここに処理結果(XML出力)が格納されます。
次に、XMLドキュメントの中から、<one:Page>タグを1つづつ検索していきます。タグ内のname属性値から対象ページを特定し、pageIDを取得。
pageIDが取得できたら、GetPageContentメソッドを使って、ページ内の全てのコンテンツを同じくXML形式で取得します。
欲しい情報であるOCRテキストは、<one:OCRText>タグ内のinnerTextを参照すれば手に入ります。1つの画像につき1つの<one:PCRText>タグがあるので、画像の数だけinnerTextを取得すればOK。
ちなみに余談ですが、ページ内のコンテンツを操作したい場合は、こんな感じでXMLドキュメントからコンテンツを特定(Nodeや属性の特定)すればコンテンツ操作が可能です。
'貼り付けられた画像を左に寄せる
Set pageDoc = CreateObject("MSXML2.DOMDocument.6.0")
pageDoc.LoadXML (pageXML)
pageDoc.SetProperty "SelectionLanguage", "XPath"
pageDoc.SetProperty "SelectionNamespaces", "xmlns:one='http://schemas.microsoft.com/office/onenote/2013/onenote'"
Dim paneNode As Object 'MSXML2.IXMLDOMNode
Set pageNode = pageDoc.SelectSingleNode("one:Page//one:Position ")
Set PositionX = pageNode.Attributes.getNamedItem("x")
PositionX.Value = "72.0"もしくは、
Dim PositionX As Object 'MSXML2.IXMLDOMAttribute
Set PositionX = pageDoc.SelectSingleNode("one:Page//one:Position/@x ")
PositionX.Value = "72.0"のように書いてもOK。
後者の方は、階層ごとにダブルスラッシュで区切ってNodeを指定し、シングルスラッシュと@でタグ内属性を指定しています。
自分の書きやすい方で良いと思います。
画像をアップロード
続いてOneNoteにアップロードするサンプルです。
'待機用PAI
Private Declare PtrSafe Sub Sleep Lib "kernel32" (ByVal dwmilliseconds As LongPtr)
'Windows GDI+用API(画像サイズ取得用)
Private Declare PtrSafe Function GdiplusStartup Lib "gdiplus" (ByRef token As LongPtr, ByRef inputBuf As GdiplusStartupInput, ByVal outputBuf As Long) As Long
Private Declare PtrSafe Sub GdiplusShutdown Lib "gdiplus" (ByVal token As LongPtr)
Private Declare PtrSafe Function GdipLoadImageFromFile Lib "gdiplus" (ByVal FileName As LongPtr, ByRef image As LongPtr) As Long
Private Declare PtrSafe Function GdipDisposeImage Lib "gdiplus" (ByVal image As LongPtr) As Long
Private Declare PtrSafe Function GdipGetImageWidth Lib "gdiplus" (ByVal image As LongPtr, ByRef width As Long) As Long
Private Declare PtrSafe Function GdipGetImageHeight Lib "gdiplus" (ByVal image As LongPtr, ByRef height As Long) As Long
Private Type GdiplusStartupInput
GdiplusVersion As Long
DebugEventCallback As LongPtr
SuppressBackgroundThread As Long
SuppressExternalCodecs As Long
End Type
'参照設定
'Microsoft OneNote 15.0 Object Library
'Microsoft OneNote 15.0 Extended Type Library
Private Sub OneNote_OCR()
'OneNote起動
Dim exec As Object
Set exec = CreateObject("Wscript.shell").exec("onenote.exe")
Sleep 1000
Dim app As OneNote.Application
Set app = New OneNote.Application
Sleep 3000
'OneNote全体のXMLを取得
Dim XML As String
Dim Doc As Object 'MSXML2.DOMDocument60
app.GetHierarchy vbNullString, hsPages, XML
Set Doc = CreateObject("MSXML2.DOMDocument.6.0")
Doc.LoadXML XML 'XML文字列をパース
Doc.SetProperty "SelectionLanguage", "XPath"
Doc.SetProperty "SelectionNamespaces", "xmlns:one='http://schemas.microsoft.com/office/onenote/2013/onenote'" '「one」の名前空間の指定
'ページタイトルから対象ページを特定
Dim node As Object 'MSXML2.IXMLDOMNode
Dim PageName As String
Dim pageID As String
For Each node In Doc.SelectNodes("//one:Page")
PageName = node.Attributes.getNamedItem("name").text
If PageName = "画像解析テスト" Then
pageID = node.Attributes.getNamedItem("ID").text 'pageIDをゲット
End If
Next
Set Doc = Nothing
If pageID = "" Then
Debug.Print "対象ページが見つかりませんでした"
Exit Sub
End If
'ページ内の全コンテンツを取得
Dim pageXML As String
app.GetPageContent pageID, pageXML
'対象ページのXML記述を取得
Dim pageDoc As Object 'MSXML2.DOMDocument60
Set pageDoc = CreateObject("MSXML2.DOMDocument.6.0")
pageDoc.LoadXML pageXML
pageDoc.SetProperty "SelectionLanguage", "XPath"
pageDoc.SetProperty "SelectionNamespaces", "xmlns:one='http://schemas.microsoft.com/office/onenote/2013/onenote'" '「one」の名前空間の指定
'画像データを指定
Dim FilePath As String
FilePath = "C:\Users\****\Downloads\****.PNG"
'<one:Page>の子階層に、<one:Image>タグを新規作成
Dim pageNode As Object 'MSXML2.IXMLDOMNode
Dim newElm As Object 'MSXML2.IXMLDOMElement
Dim imgNode As Object 'MSXML2.IXMLDOMNode
Dim newAtt As Object 'MSXML2.IXMLDOMAttribute
Set pageNode = pageDoc.SelectSingleNode("one:Page ")
Set newElm = pageDoc.createElement("one:Image")
Set imgNode = pageNode.appendChild(newElm)
Set newAtt = pageDoc.createAttribute("format")
newAtt.Value = "png"
imgNode.Attributes.setNamedItem newAtt
'<one:Image>の子階層に、<one:Position>タグを新規作成
Dim newNode As Object 'MSXML2.IXMLDOMNode
Set newElm = pageDoc.createElement("one:Position")
Set newNode = imgNode.appendChild(newElm)
Set newAtt = pageDoc.createAttribute("x")
newAtt.Value = "72.0"
newNode.Attributes.setNamedItem newAtt
Set newAtt = pageDoc.createAttribute("y")
newAtt.Value = "50.0"
newNode.Attributes.setNamedItem newAtt
Set newAtt = pageDoc.createAttribute("z")
newAtt.Value = "1"
newNode.Attributes.setNamedItem newAtt
'<one:Image>の子階層に、<one:Size>タグを新規作成
Set newElm = pageDoc.createElement("one:Size")
Set newNode = imgNode.appendChild(newElm)
Set newAtt = pageDoc.createAttribute("width")
newAtt.Value = "400.0"
newNode.Attributes.setNamedItem newAtt
Set newAtt = pageDoc.createAttribute("height")
newAtt.Value = 400 * getAspect(FilePath)
newNode.Attributes.setNamedItem newAtt
'<one:Image>の子階層に、<one:Date>タグを新規作成
Set newElm = pageDoc.createElement("one:Data")
Set newNode = imgNode.appendChild(newElm)
newNode.text = EncodeBase64(FilePath)
'OneNoteページを更新
app.UpdatePageContent pageDoc.XML
'OneNote終了
exec.Terminate
Set app = Nothing
Set exec = Nothing
End Sub
'画像データをBase-64形式に変換する
Private Function EncodeBase64(ByVal FilePath As String) As String
Dim elm As Object
Dim temp As String
On Error Resume Next
Set elm = CreateObject("MSXML2.DOMDocument").createElement("base64")
With CreateObject("ADODB.Stream")
.Type = 1 'adTypeBinary
.Open
.LoadFromFile FilePath
elm.DataType = "bin.base64"
elm.nodeTypedValue = .Read(-1) '.Read(adReadAll)
temp = elm.text
.Close
End With
On Error GoTo 0
EncodeBase64 = temp
End Function
'画像ファイルの縦横サイズを取得し、縦横比を返す
Private Function getAspect(ByVal FilePath As String) As Long
Dim uGdiStartupInput As GdiplusStartupInput
Dim nGdiToken As LongPtr
Dim hImage As LongPtr
Dim width As Long
Dim height As Long
uGdiStartupInput.GdiplusVersion = 1 'GDI+のバージョン指定
If GdiplusStartup(nGdiToken, uGdiStartupInput, 0&) = 0 Then 'GDI+を初期化
If GdipLoadImageFromFile(ByVal StrPtr(FilePath), hImage) = 0 Then '画像読み込み
GdipGetImageWidth hImage, width '幅取得
GdipGetImageHeight hImage, height '高さ取得
End If
End If
GdipDisposeImage hImage 'メモリ開放
GdiplusShutdown nGdiToken 'リソースをクリーンアップ
getAspect = height / width
End FunctionOneNoteのページを更新するには、UpdatePageContentメソッドを使います。引数として、ページに対して行う変更を含むXML文字列を渡します。
つまり画像をアップロードしたいときは、
①現在のOneNoteページのXML記述を取得
②画像データを文字列(Base64形式)にエンコード
③上記①と②をドッキング
(①のXML記述に対し人為的にタグとデータ本体(②)を加筆)
④ドッキングしたXML記述を、UpdataPageContentメソッドで上書き
すれば良いということ。
XML記述で考えるなら、以下の選択部を意図的に追記してやれば良い。
画像データを扱うために必要なタグや属性を用意し、画像データをBase-64形式に変換して記述します。レファレンスによると、バイナリデータ(画像など)はBase-64形式で扱われているとあったので、エンコードしてから記述します。

これで画像がアップロードできます。
なおサンプルコード内に出てくるWin API関数は、画像データの縦横サイズ比を取得したいがために使用したものです。OneNote操作においてはWin APIを使用しません。
※サブルーチンgetAspect()ファンクション部分でWin API使用。
備忘
OneNoteアプリケーションは事前バインディングしてください。
参照設定
・Microsoft OneNote 15.0 Object Library
・Microsoft OneNote 15.0 Extended Type Library
なおXML記述の編集時は「Microsoft XML v6.0」を使っていますが、開発時はこれも参照設定しておくと入力補完が使えるので捗ります。
OneNoteのOCR機能がどういう内部処理をしているのか詳しく知りませんが、画像が小さい場合は誤認識がチラホラ発生します。
OCR機能に特化したアプリ等と比べると、やっぱり読み取り精度は見劣りするかなーという印象。
ただしOffice365のライセンスさえあれば誰でも無料で手軽に使えるのが魅力です。誤認識が気になる場合は、抽出後のテキストを何らかのスキーム(AIとかパターンとか)で補正してやる必要があるかもしれません。
最後に、話が変わりますがOCR関連でいうと、Excelのパワークエリを使って画像からテキスト抽出する機能も中々使い勝手が良かったので、書き留めておきます。あとはPowerAutomateのAI Builderを使ってOCR+AI補正したテキスト抽出も中々高精度でした。
どちらもライセンスに依って機能が制限されている点が残念ですが、使える環境にある場合は選択肢の一つに挙がってくるでしょう。
OCRのような便利機能がどんどん普及して、OneNote以外の色々なアプリにも標準装備される時代が早く来てほしいです…。
この記事が気に入ったらサポートをしてみませんか?