
【論文瞬間】データサイエンスの新しい味方!LLMベースのエージェント「Data Interpreter」

こんにちは!株式会社AI Nestです。
今日は、データサイエンスの世界に革新をもたらす新しい技術について紹介したいと思います。それが、LLMベースのエージェント「Data Interpreter」です。
タイトル:DATA INTERPRETER: AN LLM AGENT FOR DATA SCIENCE
URL:https://arxiv.org/abs/2402.18679
所属:DeepWisdom, Universit ́e de Montr ́eal & Mila, Fudan University, Renmin University of China, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, AI Initiative, King Abdullah University of Science and Technology, University of Notre Dame, The University of Hong Kong, Yale University, Xiamen University, East China Normal University, Beijing University of Technology, The Chinese University of Hong Kong, Shenzhen, Hohai University
著者:Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, Li Zhang, Lingyao Zhang, Min Yang, Mingchen Zhuge, Taicheng Guo, Tuo Zhou, Wei Tao, Wenyi Wang, Xiangru Tang, Xiangtao Lu, Xiawu Zheng, Xinbing Liang, Yaying Fei, Yuheng Cheng, Zongze Xu, Chenglin Wu
Data Interpreterとは?
Data Interpreterは、データサイエンスのタスクに特化したLLMベースのエージェントです。LLMとは、大規模言語モデル(Large Language Model)のことで、自然言語処理の分野で大きな注目を集めています。Data Interpreterは、このLLMの力を借りて、データサイエンスの問題解決を支援します。
具体的には、動的な計画立案、ツールの統合と進化、自動化された信頼度ベースの検証といった機能を備えています。これらの機能により、データサイエンスに内在する課題、例えばデータ依存性の強さ、洗練されたドメイン知識、厳密な論理要件などに対処することができるのです。
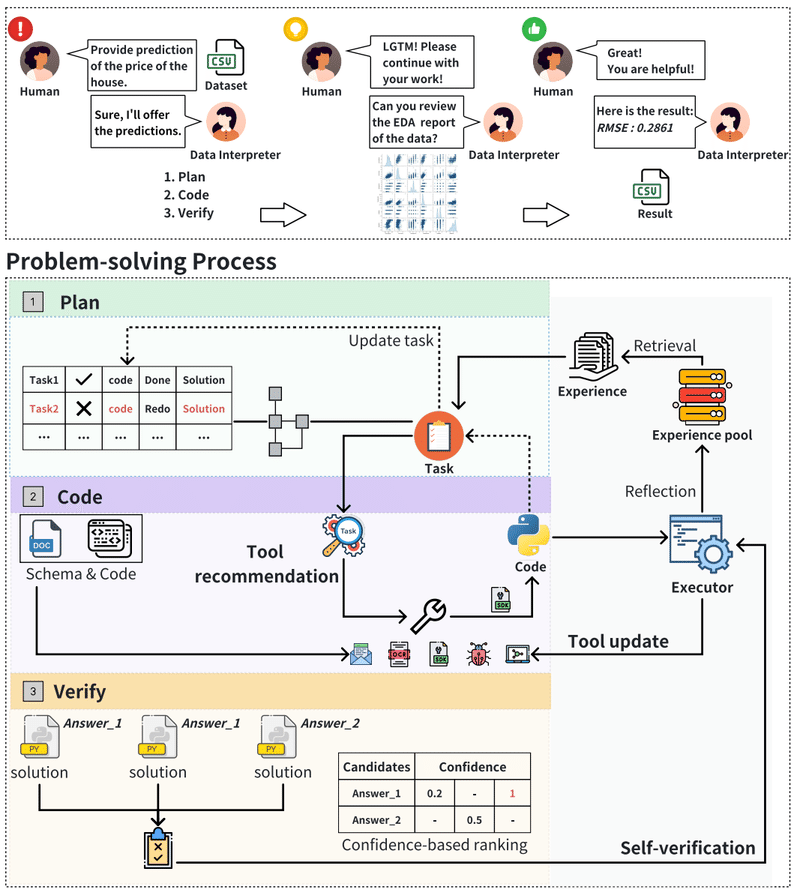
Data Interpreterの全体的な設計は、上図のようになっています。動的な計画グラフと管理、ツールの活用と進化、自動化された信頼度ベースの検証という3つのステージから構成されています。この設計により、データサイエンスの問題に対して包括的なアプローチが可能になります。
どのように機能するの?
Data Interpreterは、階層的なグラフ構造を用いて、データサイエンスのタスクを動的に計画します。これにより、各ステップ間の複雑な相互作用やリアルタイムの変更にも柔軟に対応できます。
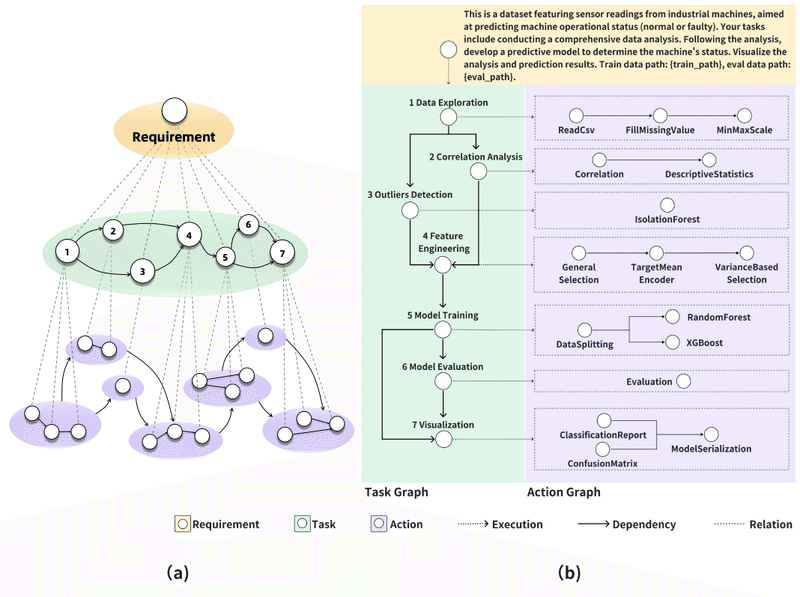
上図は、機械学習プロジェクトにおけるタスクとアクションのグラフの例です。このような階層構造を用いることで、プロジェクトの目標達成に必要なタスクの依存関係とアクションの順序を明確に表現できます。
また、ツールの推奨・生成機能を通じて、コーディング能力を向上させます。データサイエンティストの専門知識やコーディング方法は、現在のLLMではアクセスが困難ですが、Data Interpreterはこの課題を解決します。
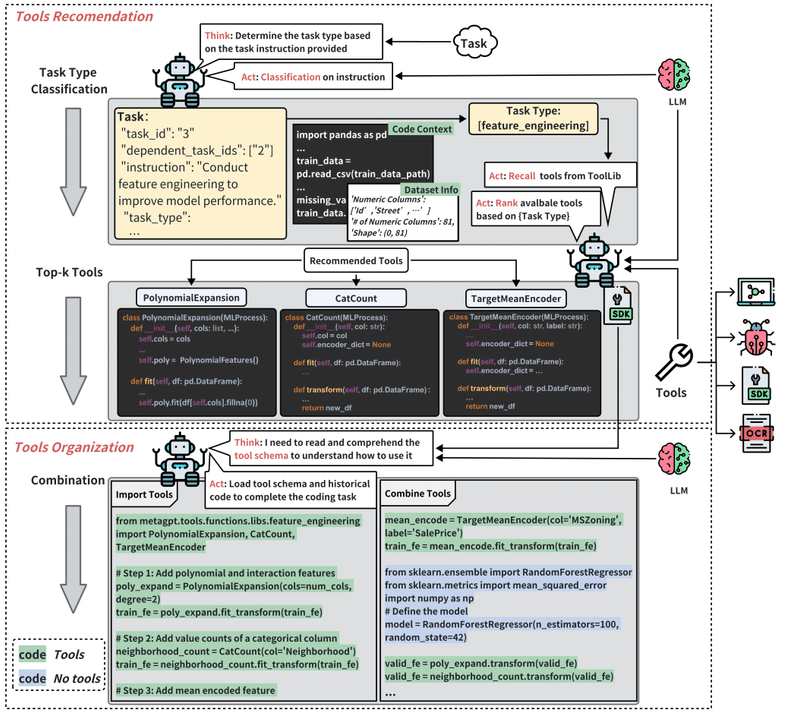
Data Interpreterでは、上図のようなツール使用のパイプラインを採用しています。まず、タスクの分類に基づいてツールを選択し、次に複数のツールを必要に応じて組み合わせてタスクを達成します。このプロセスにより、効率的かつ柔軟なツールの活用が可能になります。
さらに、自動化された信頼度ベースの検証と経験の活用により、推論能力を高めます。実行エラーがないだけでは不十分で、曖昧で不規則な要件への対応が必要ですが、Data Interpreterはこれを可能にします。
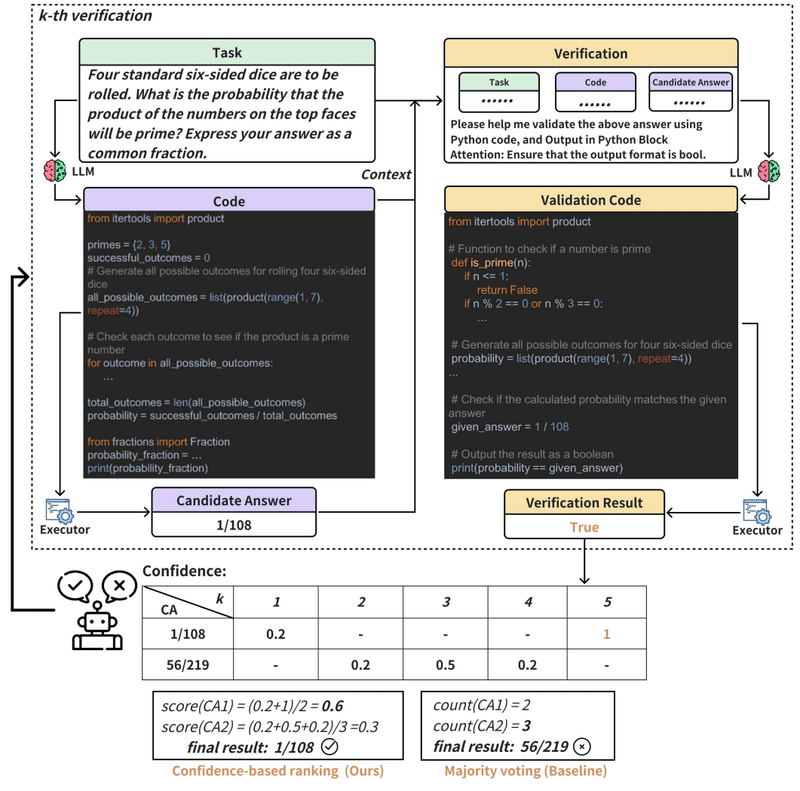
上図は、自動化された信頼度ベースの検証の例です。コードの実行結果と検証コードの実行結果を比較し、複数の試行を通じて論理エラーを減らすことができます。この検証プロセスにより、解の信頼性が向上します。
実証実験の結果は?
研究チームは、Data Interpreterの有効性を機械学習タスク、数学的問題、オープンエンドタスクで評価しました。その結果、提案手法の網羅性と整合性の高さが示されました。
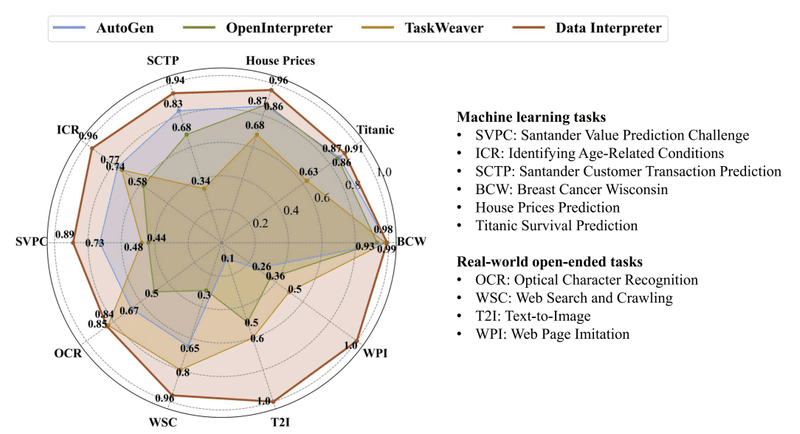
Figure1. 機械学習タスクと実世界のオープンエンドタスクにおける様々なオープンソースフレームワークとの比較。
上図は、機械学習タスクと実世界のオープンエンドタスクにおける、各種オープンソースフレームワークとData Interpreterの性能比較です。Data Interpreterは、すべてのタスクにおいて優れた性能を示しています。
特に、機械学習タスクでは、既存の手法と比較して10.3%の性能向上が見られました。
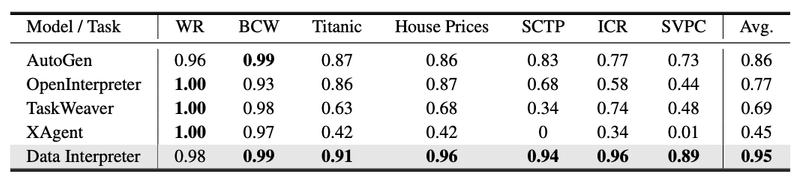
上表は、ML-Benchmarkにおける各手法の性能比較です。Data Interpreterは、すべてのタスクにおいて最高の包括スコアを達成しています。
また、オープンエンドタスクでは、Data Interpreterの完了率は97%に達し、AutoGenと比べて112%の相対的な改善が見られました。

上表は、オープンエンドタスクベンチマークにおける各手法の完了率の比較です。Data Interpreterは、平均で97%の完了率を達成し、他の手法を大きく上回っています。AutoGenの完了率は46%であったため、Data Interpreterは112%の相対的な改善を示したことになります。
これらの結果は、Data Interpreterの実践的な有用性を裏付けるものです。
今後の展望は?
Data Interpreterは、データサイエンスの主要な課題に対して包括的なアプローチを提案し、その有効性を実証実験で示しています。特に、動的計画立案やツールの統合といった手法は、データサイエンスの実践において重要な役割を果たすと考えられます。
ただし、理論的な解析や大規模な実世界のタスクへの適用可能性については、さらなる検証が必要でしょう。また、Data Interpreterの基盤となっている言語モデルの性能や特性が、提案手法の有効性にどのような影響を与えるのかについても、興味深い研究課題だと思います。
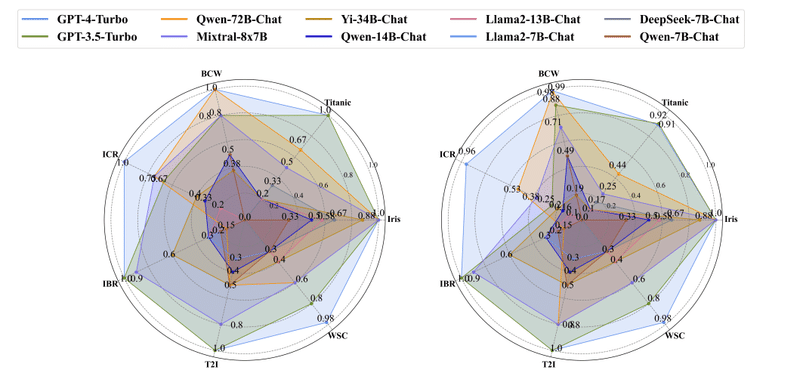
上図は、異なるLLMを用いたML-Benchmarkでの評価結果です。GPT-4-Turboと同等の性能を示すLLMもありますが、より小さなLLMでは性能の低下が見られます。使用するLLMの選択は、Data Interpreterの性能に大きな影響を与える可能性があります。
今後、データサイエンスにおけるLLMベースのエージェントの活用が進むことで、より効率的で高度なデータ分析が可能になることを期待しています。Data Interpreterは、その先駆けとなる技術であり、データサイエンスの未来を切り拓く存在になるかもしれません。
みなさんも、ぜひData Interpreterに注目してみてください!データサイエンスの新しい可能性を感じていただけるはずです。
以上、「Data Interpreter」についての紹介でした。それでは、また次の記事でお会いしましょう!