
時系列予測の性能を大幅に向上させる新アーキテクチャ、iTransformerの論文を読む

論文の核心:
Transformerモデルは、言語モデルや画像分析など様々なタスクで高いパフォーマンスを示していますが、時系列予測においては一部の問題点が指摘されています。
この論文では、Transformerの一部の役割を反転させることで、これらの問題点を克服し、より効果的な時系列予測を行うiTransformerという新しいモデルを提案しています。
この論文の新規性は、Transformerの構造そのものを時系列に特化させる点にあります。単純な構造変更で大幅な性能向上を実現できること。時系列予測におけるTransformer利用の在り方を提言しています。
まずclaudeで要約してみます。
要約
第1段落: Transformerが自然言語処理やコンピュータビジョンで成功している一方、時系列予測では性能が線形モデル以下であることを指摘。時系列の特性上、Transformerの構造が不適切だと考えられる。
第2段落: Transformerベースの時系列予測モデルは大きく4つに分類できる。(1) アテンション機構などのコンポーネントを改良 (2) 時系列処理を拡張 (3) 多変量相関をモデル化 (4) 提案手法のようにアーキテクチャそのものを修正。
第3段落: 提案手法の概要説明。時系列をトークンとして埋め込み、アテンションで多変量相関を、フィードフォワードで時系列表現を学習する構造を提案。
第4段落: Transformerの各コンポーネントの提案手法における役割の説明。レイヤーノーマライゼーションは変量間の差異を抑制、フィードフォワードは時系列の表現を抽出、アテンションは多変量相関をモデル化。
第5段落: 実験の設定説明。6つの実世界のデータセットを用いて評価。
第6段落: 予測実験の結果。提案手法が最先端手法に対して一貫した性能向上を達成した。
第7段落: 提案フレームワークの汎用性の検証。既存のTransformerに適用することで性能向上が見られた。
第8段落: モデルの詳細な分析。アブレーションスタディや注意メカニズムの可視化などを通じて提案手法の有効性を確認。
以上が要約です。提案手法はTransformerの構造を時系列の性質に適した形に修正することで、時系列予測課題における性能を大きく向上させています。
claudeは、PDFのままアップロードして要約できるので便利です。
しかしこの要約だけではさっぱり理解できません。。
では、GTP-4Vを使って論文内容と図の解説を作成します。
はじめに:
Transformerというモデルは、自然言語処理やコンピュータビジョンの分野で大きな成功を収めています。このモデルの強力な能力に触発され、時系列予測の分野でもTransformerの利用が増えてきました。
しかしながら、最近の研究では、Transformerベースの予測モデルの有効性に疑問が持たれています。特に、時系列データの各タイムスタンプの変数を1つのトークンとして扱うアプローチに問題があると考えられています。
問題点:
伝統的なTransformerの構造は、多変量の時系列データにおいて、同じタイムスタンプの異なる変数を1つのトークンとして組み込むため、変数間の相関関係が失われる恐れがあります。
さらに、時系列データの順序が非常に重要であるにも関わらず、Transformerはこの順序を正確に捉えることが難しいとの指摘がある。
iTransformerの提案:
この論文では、上述の問題点を解決するために、時系列データの取り扱い方を逆転させるiTransformerを提案しています。
具体的には、各変数の全タイムスタンプのデータを1つのトークンとして組み込むアプローチを取り入れています。これにより、変数間の相関を正確に捉えることが可能となります。
さらに、iTransformerは時系列データのエンコーディングのために前向きネットワークを使用しています。
実験結果:
実験の結果、提案されたiTransformerは、実際の予測ベンチマークで最先端のパフォーマンスを達成しました。
この結果は、Transformerが時系列予測に不適切ではないことを示唆しており、その使用方法が鍵であることを示しています。
図1:iTransformerの性能
異なるタスクやデータセット(ETT, PE/MS, ECL, Solar, Traffic, Weather)での平均二乗誤差(MSE)をラダーチャートで表示しています。数字が小さいほど、そのモデルの性能が良いことを示しています。
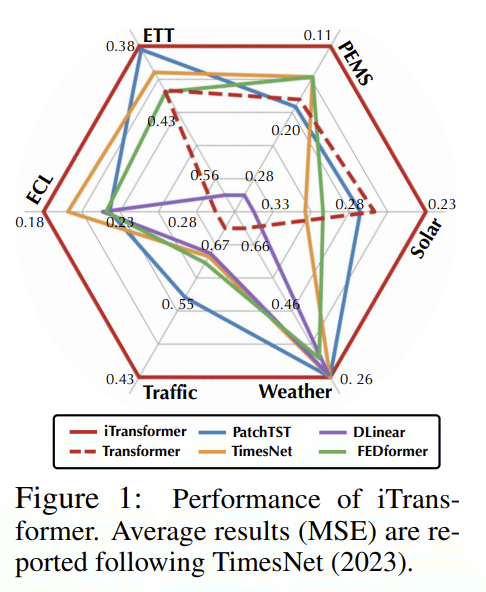
図2:通常のTransformerとiTransformerの違い
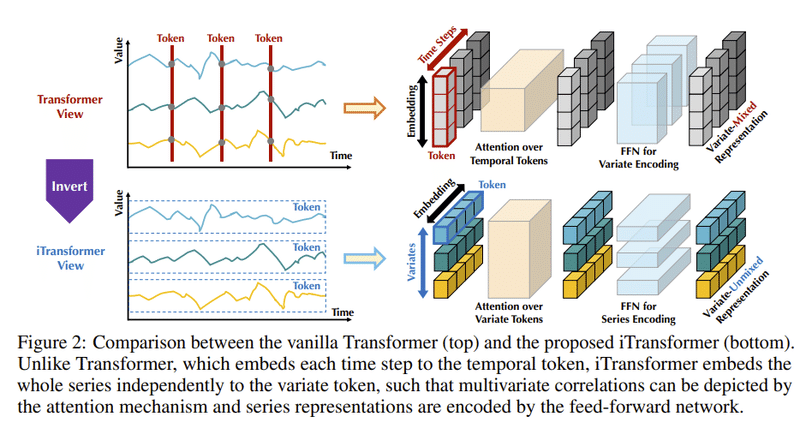
以下に、図2の内容と関連する文章の情報を基にした解説を示します。
通常のTransformer (上部):
時系列の各時刻を個別のトークンとして埋め込む方法を示しています。
同じ時刻の異なる変数(物理的意味を持つ異なるデータポイント)が、多変量の相関を失う形で1つのトークンに組み込まれます。
このトークンは、過度に局所的な受容野と実世界の多変量のタイムスタンプの不整合のために、有益な情報を明らかにするのが難しいです。
結果として、Transformerは、多変量の相関をキャッチし、多様な時系列データにおける必要な系列の表現を描写する能力が弱まっています。
iTransformer (下部):
時系列の各変数全体を独立してトークンとして埋め込む逆の方法を示しています。これは、局所的な受容野を拡大するPatchingの極端なケースとみなすことができます。
この埋め込みにより、トークンは系列のグローバルな表現を集約し、多変量の相関のための注意メカニズムでより効果的に利用されます。
同時に、フィードフォワードネットワークは、任意のルックバック系列からの異なる変数の符号化と、未来の系列の予測のための復号化に対して、一般化可能な表現を学習するのに十分な能力を持っています。
結論: この比較から、時系列予測にTransformerが非効果的であるわけではなく、適切に使用されていないだけであることが明らかになりました。iTransformerは、多変量の相関をキャッチするために独立した時系列をトークンとして見る新しいアプローチを提案しています。この構造は、実世界の予測ベンチマークでの最先端の性能を達成すると同時に、Transformerベースの予測ツールの問題点を解決することができます。
☝️ここで、iTransformerの違いについて、初学者でも理解しやすいように説明します。
通常のTransformer:
イメージとしては、時系列データの各時刻ごとに、複数のデータポイントが「箱」に詰められているような形です。この「箱」をトークンと呼びます。しかし、この方法では、各時刻におけるデータポイント間の関連性や特徴が失われてしまうことがあるのです。
たとえば、天気と気温という2つのデータがあるとき、10時の天気と10時の気温は同じ「箱」に詰められますが、それぞれのデータの関連性や特徴は考慮されにくい状態になります。
このため、通常のTransformerは、時系列データの中の多変量の関連性をうまく捉えることが難しくなっています。
iTransformer:
これは、通常のTransformerの「箱」の詰め方とは逆のアプローチをとります。各変数、例えば「天気」や「気温」ごとに、その時系列全体を1つの「箱」(トークン)として扱います。これにより、各変数の時間的な変動や特徴をしっかりと捉えることができます。
例を使うと、天気の時系列データ全体が1つの「箱」に、気温の時系列データ全体が別の「箱」に詰められるイメージです。そして、これらの「箱」同士の関連性や影響を、注意メカニズムでうまく分析します。
このようにiTransformerは、各変数の特性や変動を網羅的に捉え、さらに変数間の関連性も考慮するため、より正確な時系列予測が可能になります。
結論:
通常のTransformerとiTransformerの大きな違いは、「箱」の詰め方と、その「箱」をどのように分析するかにあります。iTransformerは、時系列データの特性や多変量の関連性をより適切に捉える新しい方法を提案しており、これにより、時系列予測の精度と効率が大幅に向上しています。
図3:コンポーネントと全体のアーキテクチャの変更に基づいてカテゴリ化

この図は、トランスフォーマーベースの予測モデルを、そのコンポーネントと全体のアーキテクチャの変更に基づいてカテゴリ化しています。ローマ数字のIからIVまでの各カテゴリは、トランスフォーマーアーキテクチャを変更または利用する異なるアプローチを示しています:
(I) Autoformer、Informer など:
これらのモデルは、コンポーネントの適応に焦点を当てています。
主な変更点は、時間依存性のモデリングを強化するための注意機構です。
長いシーケンスの処理の最適化も重視されています。
(II) PatchTST、NSTransformer など:
これらのモデルは、トランスフォーマーの核心的な強みを活用しています。
Stationarization、Channel Independence、Patchingなどの新しい技術を導入して、時系列データの処理を行います。
予測性能の一貫した向上を目指しています。
(III) Crossformer など:
このカテゴリは、トランスフォーマーのコンポーネントと全体のアーキテクチャの両方の面で改良しています。
異なる時間帯や複数の変数間の依存関係をキャッチする新しいアプローチを採用しています。
これは新設計の注意機構とアーキテクチャの変更を通じて実現されています。
(IV) iTransformer (提案モデル):
他のカテゴリとは異なり、このモデルはトランスフォーマーのネイティブなコンポーネントを変更しません。
代わりに、コンポーネントの役割を完全に反転させるユニークなアプローチを採用しています。
元のトランスフォーマーモジュールは、さまざまな領域での効果が既に証明されているため、時系列予測のためのアーキテクチャが最適に利用されていないという考えに基づいています。
要するに、この図とテキストは、時系列予測のためのトランスフォーマーアーキテクチャがどのようにカスタマイズされ、調整されてきたかを示しており、この分野の革新と変化を強調しています。
☝️コンポーネント:これはトランスフォーマー内の各部品を指します。例えば、注意機構やフィードフォワードネットワークなど、トランスフォーマーを構成する基本的な部分を指します。
アーキテクチャ:これは、各コンポーネントがどのように組み合わさって全体のモデルが形成されるかを指す設計や構造を指します。
次に、説明された新しい技術について説明します。Stationarization:「定常化」とも呼ばれるこの技術は、時系列データのトレンドや季節性を取り除き、データの変動を安定させるためのものです。これにより、トランスフォーマーがデータの特性をより効果的に学習することができます。
Channel Independence:これは、多変量の時系列データにおいて、各変数(チャネル)が独立して処理されることを意味します。これにより、各変数の特性を維持しながら、変数間の関連性も考慮することができます。
Patching:これは、大きな時系列データを小さな「パッチ」やセグメントに分割する技術です。これにより、トランスフォーマーは大きなデータセットをより効果的に処理することができます。画像処理における「パッチ」と同様の概念ですが、時系列データに適用されています。
以上の技術は、トランスフォーマーを時系列予測に適用する際の課題を解決するために導入されたものです。これらの技術を組み合わせることで、トランスフォーマーのアーキテクチャは時系列データの特性をより効果的に学習し、高い予測精度を達成することが期待されます。
図4:iTransformerの全体的な構造
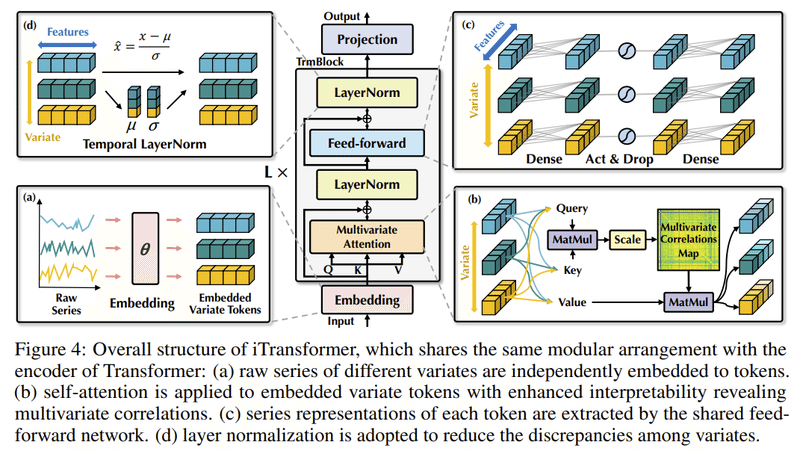
iTransformerの全体的な構造を示しています。この構造は、通常のTransformerのエンコーダと似たモジュール構成を持っています。以下、各部分の詳細を説明します:
埋め込み (a)
生の時系列データ(Raw Series)が埋め込み層を通過し、埋め込まれた変数トークン(Embedded Variate Tokens)に変換されます。
多変量注意機構 (b)
これは、変数間の関連性や依存性を捉えるためのセルフアテンションメカニズムです。Query, Key, Valueの3つの部分から成り、MatMulやScaleの操作を経て、多変量の相関マップ(Multivariate Correlations Map)を生成します。
フィードフォワードネットワーク (c)
トークンのシリーズ表現は共有フィードフォワードネットワークによって抽出されます。このセクションには、密な層(Dense)、アクティベーションとドロップアウト(Act & Drop)、そしてもう一つの密な層が含まれています。
レイヤーノーマリゼーション (d)
これは、異なる変数間の不均一性やばらつきを減少させるために採用されるレイヤーノーマリゼーションの手法です。このセクションでは、特徴から平均(μ)と標準偏差(σ)を取り出して、正規化された出力を生成します。
その後、これらのプロセスを経て、最終的な出力がProjectionによって生成されます。
生の時系列データは埋め込まれ、多変量の相関を捉えるためのセルフアテンションメカニズムを経て、最終的な時系列予測が生成されます。
レイヤー正規化:
元々の目的: ディープネットワークの収束を高め、訓練の安定性を向上させるために使用される。
典型的なトランスフォーマベースの予測モデルでの問題: 時間ポイントが整列されていない場合、正規化は非因果または遅延したプロセス間の相互作用にノイズを導入する可能性がある。
逆転版での解決策: 正規化は各変数の時系列データに適用される。この方法は、非定常問題に対してより効果的であり、また、測定の不一致による差異も減少させる。
フィードフォワードネットワーク:
使用方法: トークンの表現をエンコードするための基本的なビルディングブロックとして使用され、各トークンに同一の方式で適用される。
ヴァニラトランスフォーマでの問題: 多変数の表現が誤って配置される可能性があり、局所的なトークン情報は予測のための情報が十分でない場合がある。
逆転版での解決策: フィードフォワードネットワークは変数トークンのチャンネルに適用され、時系列の複雑な表現を抽出することが可能。
セルフアテンション:
以前の予測モデルでの役割: 時間的な依存関係をモデル化するためにアテンションメカニズムが使用されていた。
逆転モデルでの役割: 一つの変数の全系列を個別のプロセスとして扱う。
メカニズム: 各時系列の包括的な表現を抽出した後、アテンションメカニズムのためのクエリ、キー、値を取得するための線形射影が使用される。
要約すると、「反転トランスフォーマーのコンポーネント」は、予測における従来のトランスフォーマーが直面する課題に取り組むことを目的としています。正規化プロセスを反転させ、フィードフォワードネットワークを異なる方法で活用し、新しい方法でセルフアテンションを使用することで、このアプローチは多変量時系列データに対してより正確で安定した結果を提供するようです。
結果

予測結果 このセクションでは、提案したモデルの予測パフォーマンスを先進的なベースラインとともに詳細に評価します。
ベースライン 10の有名な予測モデルをベンチマークとして選択しました。これには、(1) トランスフォーマーベースの方法:Informer、Autoformer、FEDformer、Stationary、Crossformer、PatchTST;(2) リニアベースの方法:DLinear、TiDE;そして(3) TCNベースの方法:SCINet、TimesNetが含まれます。
主要な結果 Table 1に総合的な予測結果が示されています。最良の結果は赤で、2番目の結果は下線が引かれています。MSE/MAEが低いほど、予測結果が正確です。提案したiTransformerは、一貫して最先端のパフォーマンスを達成しています。特に、ElectricityとWeatherデータセットで以前の最良のモデルであったPatchTSTは、PEMSの多くのケースで失敗しています。これは、データセットの極端な変動に起因するもので、PatchTSTのパッチングメカニズムは急速な変動を処理するための特定の局所性に焦点を失う可能性があります。対照的に、提案された方法は、シリーズの全体的な変動を集約することでこの状況により適切に対処できます。さらに、多変量の相関を明示的に捉える代表として、CrossformerのパフォーマンスはiTransformerに劣っています。これは、異なる多変量からの時間未整列のパッチの相互作用が、予測のための不要なノイズをもたらすことを示しています。したがって、ネイティブなトランスフォーマーコンポーネントは、時間のモデリングと多変量の相関のために有能であり、提案された反転したアーキテクチャは、実世界の時系列予測シナリオを効果的に処理できます。
表2: 逆転フレームワークによるパフォーマンスの向上

この表は、標準のTransformerおよびその変種に対して提案された「逆転」フレームワークを適用した場合のパフォーマンスの向上を示しています。FlashformerはFlashAttentionを備えたTransformerを意味しています。
各行の内容:
Original: 各モデルのオリジナルのパフォーマンス(MSEおよびMAE)を示しています。
+Inverted: 逆転フレームワークを適用した後のパフォーマンスを示しています。
Promotion: パフォーマンスの向上率を示しています。これは、オリジナルと逆転を比較してどれだけパフォーマンスが向上したかを示すパーセンテージです。
データセット別の詳細:
Electricity:
MSEの平均的な向上率は、Transformerで35.6%、Reformerで38.4%、Informerで30.5%、Flowformerで21.3%、Flashformerで27.8%です。
Traffic:
MSEの平均的な向上率は、Transformerで35.6%、Reformerで12.7%、Informerで13.3%、Flowformerで30.1%、Flashformerで25.2%です。
Weather:
MSEの平均的な向上率は、Transformerで60.2%、Reformerで69.2%、Informerで57.3%、Flowformerで7.2%、Flashformerで60.2%です。
総括:
この表から、逆転フレームワークが一貫してさまざまなTransformerモデルのパフォーマンスを向上させていることが明らかになっています。
この向上の背後には、逆転フレームワークが変数の次元に注意メカニズムを適用することで、時系列の予測におけるTransformerアーキテクチャの不適切な使用を改善していることが示唆されています。
効率的な注意メカニズムの導入により、リアルタイムのアプリケーションで一般的に見られる多数の変数に起因する効率の問題が実質的に解決されています。
この逆転のアイディアは、急速に増えている効率的な注意メカニズムの利点を活用するために、Transformerベースの予測機に広く実践されることが期待されます。
図5: 未知の変数に対する性能の一般化

この図は、iTransformersと通常のTransformers、およびChannel Independent(CI)手法を用いたTransformersの一般化性能を示しています。特に、未知の変数にどれだけ効果的に適応できるかを評価しています。
バーグラフの色と意味:
青色: 通常のTransformers。これは100%の変数で学習されています。
緑色: CI-Transformers(Channel Independent)。これは100%の変数で学習されています。
灰色: iTransformers。これは20%の変数で学習され、その後未知の変数に対して評価されています。
結果の解釈:
iTransformers(灰色のバー)は、未知の変数に対しても非常に低いエラーで予測することができることが示されています。
一方、CI-Transformers(緑色のバー)は、未知の変数に対して大幅なエラー増加を示しています。
一般的な考察:
iTransformersは、一般化の能力において他の手法よりも優れていることが示されています。
これは、iTransformersが独立した変数トークンに対して同一のフィードフォワードネットワークを適用するため、未知の変数に対しても適応することができるからです。
一方、CI-Transformersは、すべての変数のパターンを学習するために1つの共有Transformerを採用するため、未知の変数に対する一般化が難しくなっています。
総じて、図5はiTransformersが未知の変数に対して高い一般化性能を持っていることを示しています。この性能は、独立した変数トークンに対してフィードフォワードネットワークを適用することで達成されています。一方、CI-Transformersは未知の変数に対して大きなエラーを示しており、これは変数間の一般化が難しいことを示しています。
図6: ルックバックの長さによる予測の性能

この図は、異なるルックバック長さ(T)での予測モデルの性能を示しています。特に、ルックバックの長さが増えると、予測性能がどのように変わるのかを示しています。
グラフの色と記号:
赤色の丸: iTransformer
緑色の三角: iFlowformer
茶色の四角: iInformer
青色の丸: 通常のTransformer
青色の逆三角: Flowformer
青色の矢じり: Informer
結果の解釈:
一般的に、ルックバックの長さが増えると、通常のTransformerの予測性能は必ずしも向上しないことが示されています。
しかし、iTransformerとそのバリアント(iFlowformer, iInformer)は、ルックバックの長さが増えると性能が向上する傾向があります。
一般的な考察:
これまでの研究では、ルックバックの長さが増えるとTransformerの予測性能が向上しないという現象が観察されてきました。これは、入力が増えることで注意が散漫になるためと考えられています。
しかし、線形の予測では、過去の情報を多く利用することで性能が向上することが一般的に期待されています。
iTransformerは、注意とフィードフォワードネットワークの役割を逆転させることで、ルックバックの長さが増えた場合でも性能が向上することが示されています。
総じて、図6は、ルックバックの長さが増えるとiTransformerとそのバリアントが性能を向上させることができる一方、通常のTransformerは必ずしもそうではないことを示しています。これは、時系列の次元にMLPを活用することの合理性を裏付ける結果となっています。
表3: iTransformerのアブレーションスタディ
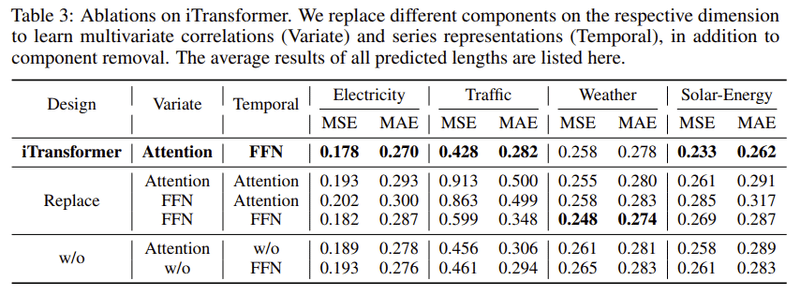
この表は、iTransformerの異なるコンポーネントを置き換えたり取り除いたりする実験の結果を示しています。
設計: iTransformerの4つのバージョンを示す。
オリジナルのiTransformer
Replace: AttentionとFFN(Feed Forward Network)の役割を交換する
w/o Attention: Attentionを取り除く
w/o FFN: FFNを取り除く
結果: オリジナルのiTransformerが一般的に最良の性能を持っており、特に多変量の次元での注意と時系列の次元でのフィードフォワードを利用するときに優れています。このことは、通常のTransformer(Replaceの行)がこれらの設計の中で最も性能が低いことからも確認できます。これは、時系列予測において従来のアーキテクチャを採用するときの責任の不一致を示しています。
Analysis of series representationsについて:
このセクションでは、フィードフォワードネットワークが時系列の表現を抽出するのに有利であるという主張をさらに検証しています。
CKA相似度: この分析では、中心化カーネル整列(CKA)相似度を使用しています。CKAが高いほど、表現がより似ていることを意味します。
結果: TransformerのバリアントとiTransformersの間でCKAを計算すると、iTransformersが次元を反転させることでより適切な時系列の表現を学習し、より正確な予測を達成していることが示されています。この結果は、予測の基盤としてのTransformerを反転させることが、根本的な改革に値することを支持しています。
総じて、これらの結果は、iTransformerとそのバリアントが時系列の表現をより効果的に学習し、時系列予測においてより優れた性能を達成していることを示しています。
図 7: 時系列の表現と多変量相関の分析

この図は、TransformerとiTransformerの間の表現のCKA(中心化カーネル整列)相似度とMSE(平均二乗誤差)の比較を示しています。
左側:
縦軸はMSEを、横軸はCKA相似度を示しています。
各点は、TransformerやiTransformerのバリエーションを示しており、CKA相似度が高いほど、その表現が正確な予測に有利であることを示しています。
iTransformerは他のモデルよりも高いCKA相似度と低いMSEを持っており、これはiTransformerが時系列の表現をより効果的に学習していることを示しています。
右側:
ソーラーエネルギーのデータセットからの時系列に基づく多変量相関のケースの視覚化を示しています。
「Lookback Correlations」と「Future Correlations」の2つのヒートマップが示されており、それぞれのセルは特定のタイムステップ間の相関を示しています。
Attentionの浅い層では、学習されたマップは生の入力系列の相関と多くの類似性を共有しています。
より深い層に進むと、学習されたマップは未来の系列の相関に徐々に似てきます。
総括: iTransformerの多変量相関の役割をattentionメカニズムに割り当てることにより、学習されたマップは解釈可能性が向上します。特に、浅いattention層での学習マップは、生の入力系列の相関に類似しており、深い層に進むと未来の系列の相関に似てきます。これは、過去のエンコーディングと未来のデコーディングのプロセスが、フィードフォワード中に本質的に連続した表現で行われていることを確認しています。
図8: 提案された訓練戦略の分析
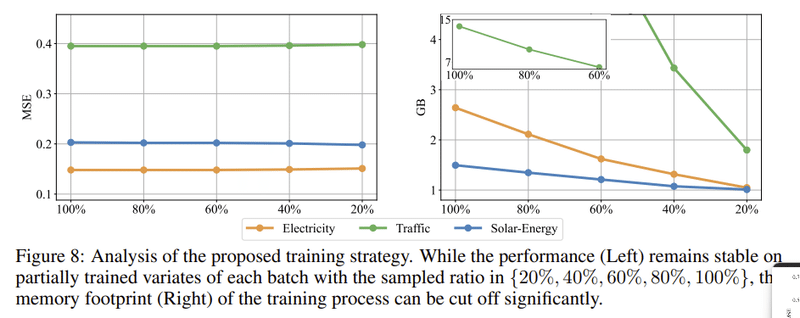
この図は、提案された訓練戦略の効果を示しています。
左側 (パフォーマンスの分析):
縦軸はMSE(平均二乗誤差)、横軸はサンプルされた変数の割合を示しています。
3つの異なる色のライン(Electricity, Traffic, Solar-Energy)は、それぞれのデータセットにおける訓練のパフォーマンスを示しています。
グラフは、変数のサンプリング割合が増えるにつれて、MSEが一定のままであることを示しています。これは、全変数での訓練と比較して、部分的な変数での訓練でも同様のパフォーマンスが得られることを示しています。
右側 (メモリ使用量の分析):
縦軸はGB単位のメモリ使用量、横軸はサンプルされた変数の割合を示しています。
サンプルされた変数の割合が減少するにつれて、訓練中のメモリ使用量も顕著に減少していることがわかります。
総括: 提案されたiTransformerでは、自己注意の二次的な複雑さのため、多数の変数での訓練は大変になる可能性があります。そこで、以前に示された変数生成能力を利用して、高次元の多変量系列のための新しい訓練戦略が提案されています。具体的には、各バッチで変数の一部をランダムに選択し、選択された変数だけでモデルを訓練します。この方法で、提案された戦略のパフォーマンスは、全変数訓練と同等でありながら、メモリの使用量を大幅に削減することが可能となっています。
結論と今後の取り組み
この研究では、通常のトランスフォーマーのアーキテクチャは時系列予測のための重要な系列の表現や多変量の相関を発見するのに適していないことを指摘しました。そのため、iTransformerが提案されました。これは時系列のために最小限に適応された基本的なバックボーンで、逆転した次元を自然に扱うコンポーネントを持っています。実験の結果、iTransformerは最先端のパフォーマンスを達成し、有望な分析によって非常に高い柔軟性を示しています。今後は、広範な時系列分析タスクのためのiTransformersをさらに探求する予定です。
論文の核心:
Transformerモデルは、言語モデルや画像分析など様々なタスクで高いパフォーマンスを示していますが、時系列予測においては一部の問題点が指摘されています。
この論文では、Transformerの一部の役割を反転させることで、これらの問題点を克服し、より効果的な時系列予測を行うiTransformerという新しいモデルを提案しています。
以下は時系列予測の応用に関する私見です。
時系列予測とは: 時系列データは、時間の経過とともに観測されるデータを指します。例としては、株価の動き、天気の変動、ウェブサイトの訪問者数などが挙げられます。時系列予測は、これらの過去のデータをもとに、未来のデータを予測する技術です。
論文の意義と議論:
問題点: 通常のTransformerは、多変量の時系列データに対して、各時間のデータを一つのトークンとして扱うため、異なる測定値やタイムスタンプを持つデータが混ざってしまう可能性があります。また、長い過去のデータを利用する際には、計算量が爆発的に増加する問題があります。
iTransformerの提案: この論文では、Transformerの構造を維持したまま、注意メカニズムと前向きネットワークの役割を反転させることで、上記の問題点を解決します。この新しいアーキテクチャは、多変量の相関を効果的に捉えることができ、さまざまな実世界のデータセットで高いパフォーマンスを達成しています。
時系列予測の具体的な利用例:
金融: 株価や為替レートの未来の動きを予測し、投資戦略を考える際に役立てることができます。
気象: 過去の気象データから未来の天気を予測し、災害警報の発令や農業の最適な作業時期を判断するのに役立ちます。
ウェブマーケティング: 過去のウェブサイトの訪問者数や売上データから、未来のトレンドを予測し、広告戦略や在庫管理に役立てることができます。
この論文は、時系列予測の分野でTransformerの有効性をさらに高めるための新しいアプローチを提案しており、その意義と可能性は非常に大きいと言えるでしょう。
この記事が気に入ったらサポートをしてみませんか?