
言語モデルのチューニング結果を大幅に改善させるNEFTuneの論文を読む

言語モデルのチューニング後の性能を大幅に向上させるというNeftuneの論文を読みます

まずはclaude.aiで概要を確認します
この論文は、大規模言語モデル(LLM)の教示学習を改善するためのシンプルな方法を提案しています。
キー ポイントは以下の通りです:
- 教示データの埋め込みベクトルに学習時にランダムなノイズを加えることで、LLMの教示学習が大幅に改善されることが示されています。
- LLaMA-2-7BをAlpacaで教示学習するとAlpacaEvalで29.79%の性能だが、埋め込みにノイズを加えることで64.69%まで大幅に向上した。
- Evol-Instructでの教示学習では10%、ShareGPTで8%、OpenPlatypusで8%の改善が見られた。
- RLHFでさらに改善されたLLaMA-2-Chatでさえ、この手法で追加の教示学習をすることで会話品質が向上した。
- 埋め込みへのノイズ追加は過学習を抑え、教示データの形式や言い回しに囚われることなく、事前学習モデルの知識と振る舞いを取り入れた応答ができるようになると考えられる。
- このシンプルな手法は、LLMの教示学習において大きな改善をもたらす「フリーランチ」となりうる。
この論文は、ランダムなノイズを埋め込みに加えることで、LLMの教示学習を劇的に改善できることを示した興味深い研究です。シンプル但し効果的な手法であると言えそうです。
Summarized by claude.ai
はじめに
本論文では、ファインチューニングのフォワードパス中にトレーニングデータの埋め込みベクトルにランダムノイズを加えるという技術です。
このシンプルな方法で、追加の計算やデータのオーバーヘッドなしで、ファインチューニングの結果を向上させることができます。
このNoisy Embedding Instruction Fine Tuning(NEFTune)でLLaMA-2-7Bをチューニングですると、AlpacaEvalでのパフォーマンスは29.8%から64.7%に向上します(図1)

機能のキモと応用に関する私見
🪄この手法のキモと、期待できる効果として以下のようにまとめられると思います
ランダムなノイズを加える
Instruction finetuningで発生しうる過学習を予防
事前学習の機能を維持しつつより良質な回答を得る
この時、より良い出力を得るのに追加の計算リソースを必要としていないということが重要です。
パッと思いつく応用事例
NEFTuneでは、アウトプットの文が長くなる傾向にあるので、シンプルな回答が必要な場合は向かないと思います。
過学習傾向で、回答が単調、あっさりしすぎで、面白味がない場合、もう少し丁寧に回答して欲しい場合にNEFTuneを使うと、より人間ウケがよい返答が期待されます。
簡単な使い方
実装方法は以下のようにneftune_noise_alphaを1行追加します。
from datasets import load_ dataset
from trl import SFTTrainer
dataset = load _dataset ("imdb", split="train")
trainer = SFTTrainer (
model_name,
train_dataset=dataset,
dataset_text_field="text" ,
max_seq_length=512,
neftune_noise_alpha=5,
)
trainer.train( )2023/11/3追記
トランスフォーマー 4.35.0 がリリースされました。NEFTune はトランスフォーマーのトレーナー API に拡張されました。
TrainingArguments に `neftune_noise_alpha=xxx` を渡すだけで完了です。
方法
NEFTUNE:Noisy Embedding Instruction Fine Tuning
指示モデルは、指示と応答のペアから成るデータセット上でトレーニングされます。NEFTuneの各ステップは、データセットから指示をサンプリングし、そのトークンを埋め込みベクトルに変換することから始まります。次に、NEFTuneは、埋め込みにランダムなノイズベクトルを追加することで、標準的なトレーニングから逸脱します。このノイズは、範囲[−1, 1]内のiid一様エントリをサンプリングして生成され、次に、全体のノイズベクトルをα/√Ldのファクターでスケーリングします。ここで、Lはシーケンスの長さ、dは埋め込みの次元、αは調整可能なパラメーターです。
このスケーリングルールは、敵対的なML文献(Zhu et al., 2019; Kong et al., 2022)から借用され、おおよそα/√3のユークリッド大きさを持つランダムベクトルを期待しています。アルゴリズム1は、私たちの方法を詳しく説明しています。
実験設定
モデル
私たちの実験の大部分は、7BパラメータのLLMを使用して行います。特に、LLaMA-1、LLaMA-2、およびOPT-6.7B(Touvron et al., 2023a; b; Zhang et al., 2022)を使用します。これらの同じ形状のトランスフォーマーは、トレーニング中に見られるトークンで主に異なります。OPT、LLaMA-1、およびLLaMA-2は、それぞれ180B、1T、および2Tのトークンを使用してトレーニングされました。この違いは、MMLUのような標準的なベンチマークでのモデルのパフォーマンスに反映されるもので、LLaMA-2が最も優れており、OPTが最も劣っています。13Bおよび70Bパラメータモデルのために、私たちはLLaMA-2をトレーニングします。さらに、高度に洗練されたLLaMA-2-Chat(7B)モデルをファインチューニングすることで、RLHFモデルを改善します。

評価
主に単一ターンのデータを使用してトレーニングを行うため、AlpacaEvalを使用してモデルの会話能力を評価します。また、OpenLLMリーダーボードのタスクも評価して、NEFTuneの拡張が標準的な複数選択タスクのパフォーマンスにどれだけの損失をもたらすかを判断します。
AlpacaEval. Dubois et al.(2023)によってリリースされたAlpacaEvalデータセットは、生成物の全体的な品質を評価するために使用されます。AlpacaEvalは、Text-Davinci-003の生成物とモデルの生成物を805の指示で比較する自動モデルベースの評価です。Win Rateは、モデル評価者(GPT-4)によって決定されるText-Davinci-003を好むモデルの割合です。805のテストプロンプトは、Vicuna、koala、Anthropicのhh-rlhf、およびその他のソースから取得されており、非常に包括的で多様なテストとなっています。さらに、AlpacaEvalは、人間との高い合意を持っています(Dubois et al., 2023)(20Kの注釈で検証済み)。7Bおよび13Bのスケールで、この評価はまだかなり妥当であり、GPT-4とChatGPTの両方を評価者として使用します。GPT-4で評価するモデルを決定する前のテストとしてChatGPTを使用します。これは、GPT-4のコストとAPIの制限のためです。
結果の概要
NEFTuneによるテキスト品質の向上:Table 1から、すべてのデータセットで7Bスケールにおいて平均で15.1%の増加が見られることがわかります。これは、NEFTとのトレーニングがAlpacaEvalを介して測定された会話能力と回答の質を大幅に向上させることを示しています。
Table 2から、Evol-Instructでトレーニングされた70BパラメータモデルにNEFTuneを追加すると、Win Rateが75.03%から88.81%(+13.78%)に上昇することがわかります。

NEFTuneはチャットモデルを向上させることができる:Table 2から、Evol-InstructでLLaMA-2 Chat(7B)のさらなる指示のファインチューニングを行うと、LLaMA-2-Chatのパフォーマンスが3%向上することがわかります。

機能への影響:OpenLLM Leaderboardタスクで評価し、LMEval Harness(Gao et al., 2021)のMMLU、ARC、HellaSwag、TruthfulQAの実装を使用します。これらのベンチマークは、モデルの知識、推論、真実性を示してくれます。Figure 3は、スコアが安定していること、およびNEFTuneがモデルの能力を維持していることを示しています。

💡ここで説明を追加します
主要な懸念: 論文はNEFTuneが会話能力を向上させる一方で、他の古典的なスキルを犠牲にしているのではないかという潜在的な懸念を取り上げています。
OpenLLM Leaderboardのタスクでの評価: 著者らは、モデルの知識、推論能力、真実性を評価するためにOpenLLM Leaderboardのタスクを使用しています。これは、モデルがNEFTuneを使用した後もこれらの能力を維持しているかどうかをチェックするためのものです。
グラフの結果: Figure 3のグラフは、NEFTuneを使用した場合と使用しない場合のモデルのスコアを示しています。グラフから、スコアが安定しており、NEFTuneがモデルの能力を維持していることが読み取れます。
したがって、総合的な解釈としては、NEFTuneは会話能力を向上させる一方で、他の重要なモデルの能力を犠牲にしているわけではなく、その能力を維持しているということです。このため、NEFTuneを使用しても、モデルは知識、推論、真実性などの面でのパフォーマンスを維持していると言えます。
NEFTuneとQLORAの結果の概要
NEFTuneとQLORAの組み合わせ:NEFTuneは、Quantized Low Rank Adapters (QLORA) という手法との組み合わせでも、パフォーマンスを向上させることができます。
実装とハイパーパラメータ:Dettmers et al. (2023)からの実装を使用し、すべてのモデルの重みに対してデフォルトのトレーニングハイパーパラメータを使用しています。トレーニングは1エポックだけ行います。30Bの場合、有効バッチサイズを2倍にし、学習率を半分にしています。
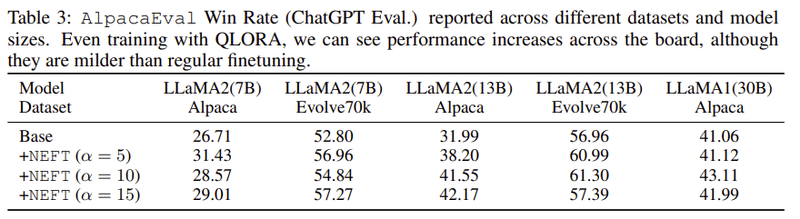
QLORAでのトレーニングの結果:Table 3によれば、QLORAでのトレーニングにより、調査されたすべてのモデルサイズとデータセットでAlpacaEvalのパフォーマンスが向上しています。
ただし、完全スケールのファインチューニングで見られるようなパフォーマンスの向上は見られません。これは、異なるハイパーパラメータ(例:ファインチューニングのエポック数)が必要であるため、または、強く4ビットに量子化しているためかもしれません。
NEFTuneチューニングの効果の詳細な分析、考察は以下に載せておきます
詳細は原文をご覧ください。
分析の概要仮説の提出:トレーニング時に埋め込みにノイズを追加することで、モデルがインストラクションチューニングのデータセットの特定の要素、例えばフォーマットの詳細、正確な言葉遣い、テキストの長さなど、に過度に適合することが減少します。その結果、モデルは正確な指示の分布に依存するのではなく、事前トレーニングされた基本モデルの知識と振る舞いを取り入れた回答を提供する能力が高まります。
観察される顕著な副作用:この方法の直接的な影響として、モデルがより一貫性のある、長い補完を形成していることがすぐに観察されます。ほとんどのデータセットで、長くて詳細な補完は人間の評価者と機械の評価者の双方に好まれます(Dubois et al., 2023)。しかし、我々は、増加した冗長性がインストラクションの分布への過度の適合の減少から生じる最も目に見える副作用であるだけでなく、増加した冗長性だけでは、パフォーマンスの向上を説明することはできないと結論付けています。

過学習についての概要
分析の焦点: この分析では、NEFTuneの有無でAlpacaデータセットでトレーニングされたLLaMA-2-7Bモデルに焦点を当てます。Alpacaデータセットでの両モデルのトレーニングロスとEvol-Instructデータセットでの「テスト」ロスを調査します。Figure 4を参照すると、NEFTuneモデルは、NEFTuneなしでトレーニングされた基本モデルと比較して、かなり高いトレーニングロスを持ちながら、わずかに低いテストロスを示しています。これは、NEFTuneが使用された場合、過学習が少なく、より良い一般化が行われることを示唆しています。
過学習仮説のさらなるテスト:また、過学習の仮説をさらにテストするために、これらのモデルを使用して、トレーニングプロンプトに対して貪欲なデコーディングを使用してレスポンスを生成します。データセットで提供されている正解のレスポンスと生成されたレスポンスを比較し、Figure 5で結果を報告します。レスポンス間の類似性を測定するために、ROUGE-L (Lin, 2004) とBLEU (n-gram order 4まで) (Papineni et al., 2002) を使用します。Figure 5では、NEFTuneでトレーニングされたモデルによって生成されたレスポンスが、ROUGE-LおよびBLEUのスコアがかなり低いことが示されています。
結論:これらの観察結果を総合すると、最大のパフォーマンスを目指して調整された標準のファインチューニングのレシピは、インストラクションデータセットに大きく過学習しており、一部のレスポンスの正確な再現を引き起こしています。一方、NEFTuneモデルはテストセットでのパフォーマンスの低下なしに過学習が少なく、インストラクションデータの正確なワーディングに「固定」しない、とROUGE-Lの指標で見られるようになります。

長さ対トークンの多様性についての概要背景:AlpacaEvalタスクでの長さの増加とパフォーマンスの間の強い相関関係(私たちの実験および公開リーダーボードへの提出において)のため、NEFTuneで観察される長さの増加がテキストの多様性の低下としてコストがかかる可能性があるかどうか気になりました。
調査方法:これを調査するために、NEFT2の有無で異なるファインチューニングデータセットでトレーニングされたLLaMA-2のn-gram繰り返し率を計算します。n-gramは長い文章でより頻繁に再発生するため、文章の長さを制御する必要があります。私たちは、各サンプルの先頭にある固定長のチャンクに対して繰り返しと多様性のスコアを計算します。Kirchenbauer et al. (2023)およびLi et al. (2022)で説明されている2-, 3-, 4-gram繰り返し率の要約測定値であるログダイバーシティを計算します。
結果:Table 4およびTable 6で、NEFTモデルは対応するモデルよりも長い出力を生成することがわかります。しかし、NEFTを使用してトレーニングされたモデルとそうでないモデルの2-gram繰り返し率やトークンのログダイバーシティ全体がほぼ同一であることもわかります。これは、より長いレスポンスが繰り返しの犠牲としてではなく、追加の詳細を提供するものであることを示す証拠となります。
長さが全てである(あるいはそうではない)目的:長さとリーダーボードの相関をさらに詳しく検討するため、単にモデルがより長い出力を生成するように促すだけで、NEFTでトレーニングされたモデルのパフォーマンスの向上を回復するかどうかをテストしました。
実験1:まず、モデルにより長い回答を与えるように明示的に促します。興味深いことに、これによりAlpaceEvalのスコアが16%向上します。
実験2:[EOS]トークンをブロックして長さが250トークンに達するまで、つまり、標準モデルがNEFTと同じ長さの回答を生成するように強制することで、長い完成を強制することもできます。これは、標準的なファインチューニングに比べてわずかな改善をもたらします。
実験3:NEFTアルゴリズムの一様ノイズとガウスノイズの使用を省略し、ガウスノイズがさらに長い出力を引き起こすこと、しかし、パフォーマンスの向上は伴わないことを発見します。Table 6を参照してください。より長い生成はより良いスコアを出す一方で、生成時の戦略はNEFTuneモデルのパフォーマンスには近づかないことがわかりました。


人間による研究背景:主な結果はAlpacaEvalベンチマークに基づいており、これは大規模な言語モデルによってスコアリングされているため、我々もこの研究の著者の中で小規模な人間による研究を行いました。
手法:AlpacaEvalからの140の命令のサブサンプルについて、注釈者にNEFTを使用してAlpacaデータでファインチューニングされたLLaMA-2モデルによって生成された1つの応答と、NEFTなしで訓練されたモデルからのもう1つの応答をランダムな順序で提示しました。
結果1:人間の注釈者は、88の事例でNEFTを好み、22の事例は引き分けでした。これは、AlpacaEvalの式を使用したNEFTの74.6%の勝率に対応しています(88/(140 − 22))。
結果2:次に、評価者(GPT-4)に我々のモデルの出力やText-Davinci-003の間で選択するように頼む代わりに、標準のファインチューニングモデルと同じモデルのNEFTバージョンからの同じ応答のペアを提示するAlpacaEvalの変更されたランを実行しました。そこでは、勝率が92.80%であることを観察しました。
結論:NEFTuneの成功は、大規模言語モデル(LLM)のトレーニングにおいてアルゴリズムや正則化の重要性を強調しています。
コンピュータビジョン分野では正則化の研究が進んでいるのに対し、LLMの研究ではデータセットの大きさやモデルの規模に焦点が当てられがちです。
NEFTuneの利益と、小さいデータセットに対する過学習の傾向を見ると、正則化の重要性が再評価されるべきであることが示唆されます。
制約:研究の主要な評価指標であるAlpacaEvalは、GPT-4という一つのモデルの判断に基づいています。
限られた計算リソースのため、NEFTuneの効果をより大きなモデルや多くのデータセットで検証することができませんでした。
NEFTuneがどうして効果的なのかの深い理解はまだ得られていません。
簡単に言えば、NEFTuneはLLMのトレーニングにおけるアルゴリズムや正則化の重要性を示していますが、その効果や理由についての完全な理解はまだ得られていません。
この記事が気に入ったらサポートをしてみませんか?