Stable Diffusion web UIのクラウド版みたいなやつ「Akuma.ai」ベータ版開始!

はじめまして!Akuma.ai公式noteを開設しました。
「Akuma.ai」は誰でも簡単に好きな画像生成モデルを使って生成することができるクラウドAIサービスです。
そんなAkumaですが、ようやくベータ版が始動しました!またベータ版を使ってくれるやさしい方を募集しています。
サービスの利用はこちらから:
https://akuma.ai/
Akumaベータ版について
お一人画像の生成を2000枚と、お好きなStable Diffusionモデルのアップロードを50回まで無料で行えます。上限に達したけどもっと生成したいという方は、こちらのTwitter DMからお問い合わせください。
ベータ版で生成した画像、プロンプト、アップロードしたモデル等のデータは、公開後の正式版Akuma.aiには引き継がれません。予めご了承ください。
ご不明点やご要望などありましたら、こちらのTwitter DMからお気軽にお知らせください!
Akumaのはじめかた
1) https://akuma.ai/ にアクセスしたら、「無料で始める」または「登録」をクリック。

2) 無料アカウント作成が必要なので、「Googleで続行」をクリックします。

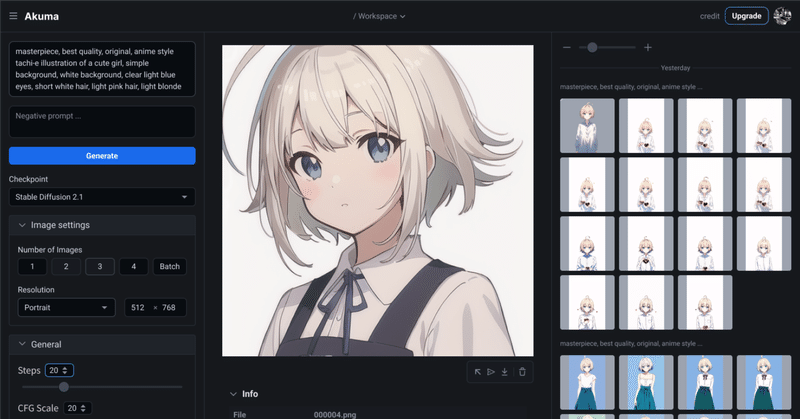
Akumaの画像生成(text-to-image)画面が表示されます。画像を生成したい場合は、プロンプトを記入して「生成」ボタンをクリックします。

自分が持っているモデル一覧を見るには、左のメニューから「Models」にアクセスします。新たにモデルを追加したい場合は、右上の「モデルをアップロード」をクリックします。
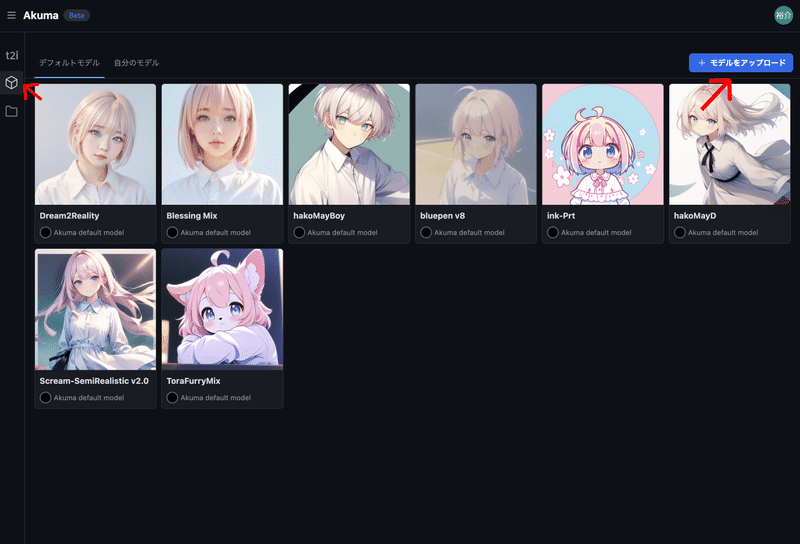
モデルの名前とモデルのファイルを選択し、「アップロードを開始」ボタンをクリックします。モデルのファイルは .safetensors または .ckpt 形式のファイルのみ、最大6GBになります。SDXLモデルはアップロードできません。

アップロードが成功したら、「Models」のモデル一覧に追加されます。アップロード直後のモデルはまだ処理中の場合があり、1分ほどお待ちいただく場合があります。

生成した画像アセットを見るには、左のメニューから「Assets」にアクセスします。

今後の開発ロードマップ
直近ではimage-to-image、ControlNet、LoRAなどの技術を使った出力のコントロールが簡単に行えるようにがんばっています。
以上、はじめてのお知らせでした。
今後はこのnoteとTwitter(https://twitter.com/AkumaAI_JP)で随時アップデートを発信していきます。これからよろしくお願いします🤗
ウェブサイト:
https://akuma.ai/
Twitter:
https://twitter.com/AkumaAI_JP
この記事が気に入ったらサポートをしてみませんか?