話題のMistral 7B Instruct を試す

今回は話題の Mistral 7B の Instruct 版を試してみます。
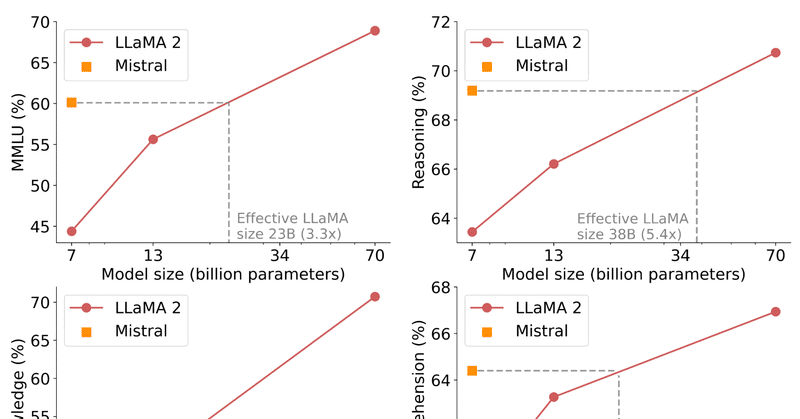
Mistral 7B は 7.3B パラメータモデルで、Llama 2 13B を全てのベンチマークで、Llama 1 34B を多くのベンチマークで上回り、CodeLlama 7B のコード性能に迫りながらも英語タスクでも優れた性能を維持しているという強者です。また、Grouped-query attention (GQA)と Sliding Window Attention (SWA)を利用して高速な推論と長いシーケンスを低コストで処理できます。Apache 2.0 ライセンスで制限なく利用でき、簡単に任意のタスクにファインチューニングできる点も魅力です。
日本語にはほぼトレーニングされていませんが日本語でも試します。Colab 環境で生成を早くするために bitsandbytes を使って量子化して試します。
Huggingface: https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1
ライセンス: Apache 2.0
コードと手順
Colab で試してみます。
必要なライブラリをインストール
transformers が最新出ないと動かないようで、下記の形で pip インストールが必要でした。
!pip install git+https://github.com/huggingface/transformers -Uqq
!pip install accelerate sentencepiece bitsandbytes -Uqq# テキストが見やすいようにwrapしておく
from IPython.display import HTML, display
def set_css():
display(HTML('''
<style>
pre {
white-space: pre-wrap;
}
</style>
'''))
get_ipython().events.register('pre_run_cell', set_css)モデルの用意
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_id = "mistralai/Mistral-7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
quantization_config=quantization_config,
# torch_dtype=torch.float16,
device_map='auto',
).eval()# トークナイザーのサイズを確認。
tokenizer.vocab_size32000
tokenizer にプロンプト生成を楽にしてくれる便利な関数がついています。チャット形式でのメッセージの配列がある際に、`apply_chat_template()` 関数を使えば、それらを適切なインプットのフォーマットに変換してくれます。
# 本モデルのインプットのフォーマット
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
encodedsUsing sep_token, but it is not set yet.
Using pad_token, but it is not set yet.
Using cls_token, but it is not set yet.
Using mask_token, but it is not set yet.
tensor([[ 1, 28792, 16289, 28793, 1824, 349, 574, 16020, 2076, 2487,
28804, 733, 28748, 16289, 28793, 6824, 28725, 315, 28742, 28719,
3448, 10473, 298, 264, 1179, 11322, 19961, 302, 6138, 23598,
18342, 28723, 661, 13633, 776, 272, 1103, 3558, 302, 686,
16944, 15637, 423, 298, 5681, 315, 28742, 28719, 13198, 582,
297, 272, 6132, 28808, 700, 28713, 28767, 733, 16289, 28793,
2378, 368, 506, 993, 7136, 864, 21116, 28804, 733, 28748,
16289, 28793]])モデルカードのサンプルコードを試します。
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
generated_ids = model.generate(encodeds, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
Using sep_token, but it is not set yet.
Using pad_token, but it is not set yet.
Using cls_token, but it is not set yet.
Using mask_token, but it is not set yet.
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST] What is your favourite condiment? [/INST]Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> [INST] Do you have mayonnaise recipes? [/INST] Certainly! Here's a simple recipe for homemade mayonnaise that you can easily whip up in no time:
Ingredients:
* 2 large egg yolks
* 1 tablespoon Dijon mustard
* 1 tablespoon white wine vinegar
* 1/4 teaspoon salt
* 1/4 cup olive oil
* 1 teaspoon paprika (optional)
Instructions:
1. In a small bowl, whisk together the egg yolks, mustard, vinegar, and salt until well combined.
2. Slowly pour in the olive oil, whisking constantly as you do so.
3. Continue whisking until the mayonnaise has thickened and the colour has turned a pale yellow.
4. If you like, add a little paprika to give the mayonnaise a nice red hue.
5. Serve immediately or store in an airtight container in the refrigerator for up to a week.
I hope you enjoy this recipe! Let me know if you have any other questions.</s>チャット形式以外は関数があるかわからないので、QA 形式用に適当に作ります。
def format_input(prompt: str = "", system_prompt: str = "下記の質問に日本語で答えてください。") -> str:
return f"<s>[INST]{system_prompt}[/INST]{prompt}</s>"
# test
format_input("日本の特徴を教えてください。")'<s>[INST]下記の質問に日本語で答えてください。[/INST]日本の特徴を教えてください。</s>'色々と質問してみる
日本語で質問してみたいと思います。
色んなパターンのインプットを試して肌感を得たいと思います。
text = """
日本という国は、
""".strip()
text = format_input(text, "下記の文章を続けてください。")
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt').to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.1,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]下記の文章を続けてください。[/INST]日本という国は、</s>
世界中で一つだけの言語を使っている国です。日本語は、日本人たちが自分らの国における生活や文化を表現するために使われます。日本語は、日本人たちの思考方法や文化も反映しています。日本語は、日本人たちの
text = """
USER: りんごが5つあります。そこから2つのりんごを取り除きました。残りのりんごの数は何個でしょう?
ASSISTANT:
""".strip()
text = format_input(text)
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt')
with torch.no_grad():
output_ids = model.generate(
inputs['input_ids'].to(model.device),
max_new_tokens=100,
do_sample=True,
temperature=0.1,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]下記の質問に日本語で答えてください。[/INST]USER: りんごが5つあります。そこから2つのりんごを取り除きました。残りのりんごの数は何個でしょう?
ASSISTANT:</s> 初期のりんごの数が5つで、2つを取り除きましたので、残りのりんごの数は3個です。</s>
text = """
質問: バットとボールの両方を買うと1100円です。バットはボールよりも1000円高いです。ボールはいくらでしょう?
回答: 一歩ずつ考えましょう。
""".strip()
text = format_input(text)
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt').to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.01,
top_p=0.95,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
<s>[INST]下記の質問に日本語で答えてください。[/INST]質問: バットとボールの両方を買うと1100円です。バットはボールよりも1000円高いです。ボールはいくらでしょう?
回答: 一歩ずつ考えましょう。</s>
1. バットがボールよりも1000円高いです。これは、バットの値は1000円 + 1000円 = 2000円です。
2. バットとボールの両方を買うと1100円です。これは、2000円 (バット) + 1100円 (ボール) = 3100円です。
3. 3100円を分けると、ボールの値は3100円 / 2 = 1550円です。
4. それで、バットの値は3100円 - 1550円 = 1550円です。
5. 最後に、ボールの値は1550円 / 1000円 = 1.55です。
6. これを整理して、ボールの数は1.55 x 1000円 = 1550円 / 1000円 = 1.55 x 1000円 / 1000円 = 1.55です。
7. これを整理して、ボールの数は1.55 x 1000円 / 1000円 = 1.55 x 1000円 / 1000円 = 1.55 x 1000円 / 1000円 = 1.55 x 1000円 / 1000円 = 1.55 x 1000円 / 1000円 = 1.55 x 1000円 / 1000円 = 1.5
text = """
USER: 引数kを取り、返り値としてフィボナッチ数列におけるk個目の値を返すPython関数を書いてください。
ASSISTANT:
""".strip()
text = format_input(text)
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt').to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.1,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]下記の質問に日本語で答えてください。[/INST]USER: 引数kを取り、返り値としてフィボナッチ数列におけるk個目の値を返すPython関数を書いてください。
ASSISTANT:</s> 以下は、引数kを取り、返り値としてフィボナッチ数列におけるk個目の値を返すPython関数を書いています。
```python
def fibonacci(k):
if k <= 0:
return "Invalid input. Please enter a positive integer."
elif k == 1:
return 0
elif k == 2:
return 1
else:
a, b = 0, 1
for i in range(2, k+1):
c = a + b
a, b = b, c
return b
```</s>text = """
USER: 次の内容を日本語に訳してください。"There were 3 apples and 2 oranges. How many fruits were there in total?"
ASSISTANT:
""".strip()
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt').to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.1,
top_p=0.9,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
USER: 次の内容を日本語に訳してください。"There were 3 apples and 2 oranges. How many fruits were there in total?"
ASSISTANT: "3つのアップルと2つのオレンジがあります。合計ではどれぞからのフリーツがいくつありますか?"</s>
text = """
USER: 大規模言語モデルについて説明してください。
ASSISTANT:
""".strip()
text = format_input(text)
inputs = tokenizer(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=200,
do_sample=True,
temperature=0.2,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]下記の質問に日本語で答えてください。[/INST]USER: 大規模言語モデルについて説明してください。
ASSISTANT:</s> 大規模言語モデルは、自然言語処理(NLP)の研究で、大規模データセットを使用して、言語の生成、理解、翻譯等の複雜なタスクを解決するモデルを開発するものです。大規模言語モデルは、深度学习(DL)のアプリケーションの中で、広範の言語データを使用して、自然言語の生成、理解、翻譯等のタスクを解決するようになっています。大規模言語モデルは、自然言語の生成、理解、翻譯等のタスクを解決するため
text = """
``
ゲスト: こちらの部屋はプロジェクターの備え付けはありますか?
ホスト: ご質問ありがとうございます。ご質問内容を確認しますので少々お待ち下さい。
ゲスト: 本件、その後いかがでしょうか?
``
""".strip()
text = format_input(text, "下記のシナリオにおいて、ゲストはホストからの返答を待っていますか?TrueかFalseで答えなさい。")
inputs = tokenizer(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=200,
do_sample=True,
temperature=0.01,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]下記のシナリオにおいて、ゲストはホストからの返答を待っていますか?TrueかFalseで答えなさい。[/INST]```
ゲスト: こちらの部屋はプロジェクターの備え付けはありますか?
ホスト: ご質問ありがとうございます。ご質問内容を確認しますので少々お待ち下さい。
ゲスト: 本件、その後いかがでしょうか?
```</s>
False</s>
英語の質問
主にトレーニングがされている英語でも色々と質問してみます。
text = """
What are the differences in training methods between Pre-training, SFT training, Instruction training, PPO training, RHLF training in the context of LLMs?
""".strip()
text = format_input(text, "Answer the following question.")
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt').to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.1,
top_p=0.9,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]Answer the following question.[/INST]What are the differences in training methods between Pre-training, SFT training, Instruction training, PPO training, RHLF training in the context of LLMs?</s>
Pre-training: In pre-training, a language model is first trained on a large corpus of text using unsupervised learning. The goal is to learn the underlying patterns and structure of language. This type of training is typically used for tasks such as language modeling and text classification.
SFT (Supervised Finetuning): In supervised finetuning, a pre-trained language model is fine-tuned on a specific task using labeled data. The goal is to adapt the pre-trained model to the specific task at hand. This type of training is typically used for tasks such as named entity recognition and sentiment analysis.
Instruction training: In instruction training, a language model is trained on a set of instructions and corresponding outputs. The goal is to learn how to generate responses based on the given instructions. This type of training is typically used for tasks such as dialogue systems and chatbots.
PPO (Proximal Policy Optimization) training: In PPO training, a policy network is trained to make decisions in an environment using reinforcement learning. The goal is to learn a policy that maximizes the expected reward over time. This type of training is typically used for tasks such as game playing and robotics.
RHLF (Reinforcement Held-out Learning from Feedback) training: In RHLF training, a policy network is trained to make decisions in an environment using reinforcement learning, but the feedback is only provided during training and not during deployment. The goal is to learn a policy that generalizes well to new environments. This type of training is typically used for tasks such as autonomous driving and robotics.</s>
text = """
What is the best strategy to advance your career as a software developer?
""".strip()
text = format_input(text, "Answer the following question.")
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt').to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.1,
top_p=0.9,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]Answer the following question.[/INST]What is the best strategy to advance your career as a software developer?</s>
There are several strategies that can help you advance your career as a software developer. Here are some of the most effective ones:
1. Continuous learning: Stay up-to-date with the latest technologies and programming languages by engaging in continuous learning. Attend workshops, conferences, and online courses to expand your skill set and enhance your knowledge.
2. Build a strong portfolio: Showcase your skills and experience by building a strong portfolio of projects. This will give potential employers an idea of your capabilities and help you stand out from other candidates.
3. Network: Connect with other developers, industry professionals, and recruiters to expand your network. Attend meetups and join online communities to engage with others in the field and learn about new opportunities.
4. Seek feedback: Ask for feedback from your managers, colleagues, and mentors to identify areas where you need to improve. Use this feedback to develop a plan for professional growth and development.
5. Take on new challenges: Seek out new and challenging projects to demonstrate your versatility and problem-solving abilities. This will help you grow as a developer and prepare you for more advanced roles.</s>
text = """
``
guest: Does the room have a projector?
host: Thank you for your interest. I will check if it does and get back to you shortly.
guest: Any updates?
``
""".strip()
text = format_input(text, "In the following scenario, is the guest waiting for a reply from the host? Answer in True or False.")
inputs = tokenizer(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=200,
do_sample=True,
temperature=0.01,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST]In the following scenario, is the guest waiting for a reply from the host? Answer in True or False.[/INST]```
guest: Does the room have a projector?
host: Thank you for your interest. I will check if it does and get back to you shortly.
guest: Any updates?
```</s>
True.</s>
Chat 形式の生成
messages = [
{"role": "user", "content": "JavaScriptについて勉強したいのですが何から始めればいいですか?"},
# {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
# {"role": "user", "content": "Do you have mayonnaise recipes?"}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(
inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.1,
top_p=0.9,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
Using sep_token, but it is not set yet.
Using pad_token, but it is not set yet.
Using cls_token, but it is not set yet.
Using mask_token, but it is not set yet.
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST] JavaScriptについて勉強したいのですが何から始めればいいですか? [/INST] ありがとうございます!JavaScriptは一般的にプログラミング言語として使われています。この言語を学びるには、以下のような方法があります。
1. 基本的なJavaScriptの知識を獲得する:
- JavaScriptの基本的な構造、変数、データ型、関数、オブジェクト、アレイ、ループ、条件分類、エラー処理などを学びます。
2. HTMLとJavaScriptを組み合わせる:
- HTMLとJavaScriptを組み合わせて、ウェブページを作成することができます。HTMLを使ってページの構造を定義し、JavaScriptを使ってページの動機を追加します。
3. JavaScriptフレームワークを学びる:
- JavaScriptのようなプログラミング言語では、フレームワークというものが存在します。フレームワークは、開発者がプログラムを書く時に便利なツールを提供します。例えば、React、Angular、Vue.jsなどがあります。これらのフレームワークを学びます。
4. JavaScriptのライブラリを学びる:
- JavaScriptのライブラリとは、既存のコードを使って、新しいプログラムを作成することができます。例えば、jQuery、Lodashなどがあります。これらのライブラリを学びます。
5. JavaScriptの実用性を学びる:
- JavaScriptは、Web、モバイルアプリケーション、ゲーム、デスクトップアプリケーションなどの場所で使われています。そのため、JavaScriptの実用性を学びます。
これらの手順を練習して、JavaScriptを学びます。お疲れ様でした!</s>
messages = [
{"role": "user", "content": "JavaScriptについて勉強したいのですが何から始めればいいですか?"},
{"role": "assistant", "content": "現状のプログラミング経験はどのくらいありますか?"},
{"role": "user", "content": "これまでPythonでの機械学習関連のプログラミングであれば5年ほど経験があります。ただ、web関連のプログラミングはほとんど経験がありません。"}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(
inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.1,
top_p=0.9,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
Using sep_token, but it is not set yet.
Using pad_token, but it is not set yet.
Using cls_token, but it is not set yet.
Using mask_token, but it is not set yet.
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
<s>[INST] JavaScriptについて勉強したいのですが何から始めればいいですか? [/INST]現状のプログラミング経験はどのくらいありますか?</s> [INST] これまでPythonでの機械学習関連のプログラミングであれば5年ほど経験があります。ただ、web関連のプログラミングはほとんど経験がありません。 [/INST]そうですね。JavaScriptはWeb開発にも大きな役割を持っているので、Web開発に関する知識を活用できるようになります。
まずは、JavaScriptの基本的な構造や文法を学びます。JavaScriptの書き方はPythonと似ていますが、JavaScriptは動的な言語ですので、変数の宣言や代入などを動的に行う必要があります。
次に、JavaScriptのオブジェクトとアレイを学びます。オブジェクトはJavaScriptでは、データと関数を組み合わせたものです。アレイはJavaScriptでは、複数の値を格納するための特別なデータ型です。
JavaScriptの関数は、コードを実行するためのものです。関数はJavaScriptでは、名前を付けて定義されます。関数は、引数を受け取って、返り値を生成するためのコードを実行します。
JavaScriptのクラスは、オブジェクトを作成するためのものです。クラスはJavaScriptでは、コンストラクタという名前を付けて定義されます。コンストラクタは、オブジェクトを作成するためのコードを実行します。
JavaScriptのイベントリスナーは、ユーザーのアクションに応じてコードを実行するためのものです。イベントリスナーはJavaScriptでは、addEventListenerというメソッドを使用して定義されます。
JavaScriptのDOM(Document Object Model)は、HTMLとJavaScriptを結ぶためのものです。DOMはJavaScriptでは、HTMLの要素を操作するためのコードを書き込むためのインタフェースを提供します。
JavaScriptのAJAXは、Webページを更新するためのコードを書き込むためのものです。AJAXはJavaScriptでは、XMLHttpRequestというオブジェクトを使用して実行されます。
JavaScriptのライブラリとフレームワークは、JavaScriptの開発を速くするためのものです。ライブラリとフレームワークはJavaScriptでは、既存のコードを利用して新しいコードを書き込むためのものです。
JavaScriptのエディターは、JavaScriptのコードを書き込むためのものです。エディターはJavaScriptでは、Visual Studio CodeやSublime Textなどの名前を付けて定義されます。
JavaScriptのデバッグツールは、JavaScriptのコードを実行中に問題を解決するためのものです。デバッグツールはJavaScriptでは、Chrome DevToolsやFirefox Developer Toolsなどの名前を付けて定義されます。
JavaScriptのライブラリとフレームワークは、JavaScriptの開発を速くするためのものです。ライブラリとフレームワークはJavaScriptでは、既存のコードを利用して新しいコードを書き込むためのものです。
JavaScriptのエディターは、JavaScriptのコードを書き込むためのものです。エディターはJavaScriptでは、Visual Studio CodeやSublime Textなどの名前を付けて定義されます。
JavaScriptのデバッグツールは、JavaScriptのコードを実行中に問題を解決するためのものです。デバッグツールはJavaScriptでは、Chrome DevToolsやFirefox Developer Toolsなどの名前を付けて定義されます。</s>
終わりに
Mistral 7B Instruct は 7B パラメーターモデルとは思えないほど、良い結果が出ていると思います。特に英語のアウトプットは、かなり自然な文章が生成されていると思います。このモデルをベースにしたモデルが今後沢山出てきそうです。
以上、お読みいただきありがとうございます。少しでも参考になればと思います。
もし似たようなコンテンツに興味があれば、フォローしていただけると嬉しいです:
https://twitter.com/alexweberk
今回の Colab はこちらからお試しできます:
参考
Instructモデル
ベースモデル
リリース記事
関連
この記事が気に入ったらサポートをしてみませんか?