リリースされたばかりの Gemini Pro API を試してみる

Gemini Pro の API を試してみたいと思います。
API キーはこちらから取得 → https://ai.google.dev/
セットアップ
!pip install -q -U google-generativeaiimport pathlib
import textwrap
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from IPython.display import display
from IPython.display import Markdown
def to_markdown(text):
text = text.replace('•', ' *')
return Markdown(textwrap.indent(text, '> ', predicate=lambda _: True))# Or use `os.getenv('GOOGLE_API_KEY')` to fetch an environment variable.
GEMINI_API_KEY=userdata.get('GEMINI_API_KEY')
genai.configure(api_key=GEMINI_API_KEY)提供されているモデルのリスト。
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)models/gemini-pro
models/gemini-pro-vision
Gemini Pro を試す
model = genai.GenerativeModel('gemini-pro')response = model.generate_content("ワンピースのチョッパーになりきって、長めの自己紹介をしてください。", stream=True)
for chunk in response:
print(chunk.text)
print("_"*80)こんにちは、僕はチョッパーです! 僕は、元々はドラム島に住んでいた トナカイでした。ある日、海賊であるヒルルクに拾われて、人間として育てられました。ヒルルクは、僕に医者になる夢を与 えてくれました。でも、ヒルルクは、僕を捨てていなくなりました。 僕は、ヒルルクの死後、医者になるために修行を始めました。そして、海賊王になることを目指すモンキー・D・ルフィの仲間になりました。 僕は、ルフィの仲間になってから、いろんな 冒険をしてきました。そして、医者として、仲間たちを助けてきました。 僕は、医者として、誰かの命を救うことが大好きです。そして、ルフィの仲間として、海賊王になる夢を叶えたいと思っています。 僕は、チョッパーです! 僕は、トナカイの医者です。 僕は、ルフィの仲間です。 僕は、海賊王になる夢を持っています。 僕は、 doctor であることを誇りに思っています。 僕は、 doctor であることを幸せに思っています。
Gemini Pro Vision を試す
次に画像モデルを試してみたいと思います。
model = genai.GenerativeModel('gemini-pro-vision')適当な画像をロードします。たまたま別タブで開いていた Microsoft の Medprompt の記事にあった画像を使いましょう。
!curl -o image.jpg https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.pngfrom PIL import Image
img = Image.open('image.jpg')
img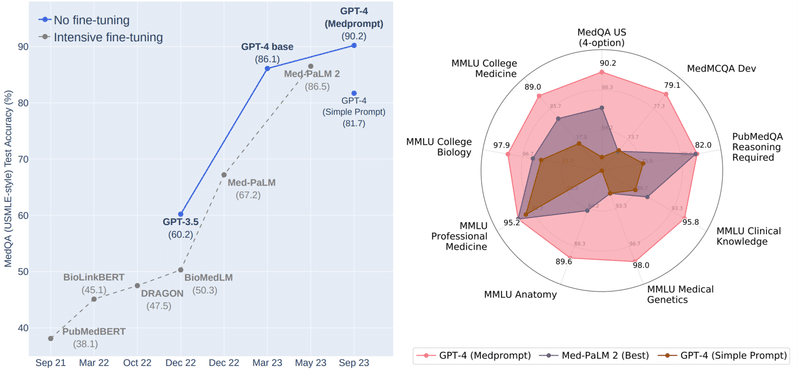
画像だけを送ると、英語の説明が返ってくる
response = model.generate_content(img)
to_markdown(response.text)The left graph shows the performance of different fine-tuning methods on the MedQA dataset. The x-axis is the date of the experiment, and the y-axis is the accuracy on the MedQA test set. The lines show the performance of different methods. The legend at the top right corner of the graph shows the names of the methods. The right graph shows the performance of different models on the MedMCQA 2023 leaderboard. The models are listed on the x-axis, and the y-axis shows the accuracy on the MedMCQA test set. The points on the graph show the performance of each model. The legend at the bottom right corner of the graph shows the names of the models.
# プロンプトと画像セットで送ると説明が返ってくる
prompt = "Write a summary of what you can learning from the image. Be detailed as much as possible. Also mention which method was the best."
response = model.generate_content([prompt, img])
to_markdown(response.text)> The image shows a comparison of different fine-tuning methods for the MedQA task. The methods are:
>
> - No fine-tuning
> - Intensive fine-tuning
> - Simple Prompt
>
> The best method is intensive fine-tuning, which achieves an accuracy of 90.2% on the MedQA test set. This method is followed by simple prompt tuning, which achieves an accuracy of 81.7%, and no fine-tuning, which achieves an accuracy of 67.2%.
>
> The image also shows that the best method for each individual dataset varies. For example, on the MedMCQA Dev dataset, intensive fine-tuning achieves the best accuracy, while on the PubMedBERT dataset, simple prompt tuning achieves the best accuracy. This suggests that the best fine-tuning method for a particular dataset depends on the specific characteristics of the dataset.
わりと間違った回答が返ってきますが、流石にサクッと試すにはちょっと難易度高すぎたかも知れません。
prompt = "画像から得られる知見を日本語で詳細にまとめてください。"
response = model.generate_content([prompt, img])
to_markdown(response.text)> 画像に示すのは、異なる事前学習済み言語モデルを用いて、医学文献の理解度を評価した結果です。縦軸は正解率、横軸は年月を示しています。
>
> モデルは、大きく分けて 3 つのグループに分けられます。1 つ目は、事前学習済み言語モデルをそのまま使用した場合です。このグループには、BERT、RoBERTa、XLNet が含まれます。2 つ目は、事前学習済み言語モデルを微調整した場合です。このグループには、BioBERT、ClinicalBERT、PubMedBERT が含まれます。3 つ目は、事前学習済み言語モデルを大規模なデータセットで微調整した場合です。このグループには、Med-BERT、SciBERT、BiomedicalBERT が含まれます。
>
> 結果は、事前学習済み言語モデルを大規模なデータセットで微調整した場合が最も良い性能を示すことを示しています。また、事前学習済み言語モデルを微調整した場合も、そのまま使用した場合よりも良い性能を示しています。これは、事前学習済み言語モデルが医学文献の理解に有効であることを示唆しています。
>
> さらに、事前学習済み言語モデルを大規模なデータセットで微調整した場合、異なるデータセット間で性能に差があることが示されています。これは、事前学習済み言語モデルが特定のデータセットに依存することを示唆しています。そのため、事前学習済み言語モデルを使用する際には、目的のデータセットに適したモデルを選択することが重要です。
おわりに
以上、お読みいただきありがとうございます。少しでも参考になればと思います。
もし似たようなコンテンツに興味があれば、フォローしていただけると嬉しいです:
リリースされたばかりの Gemini Pro API を試してみました↓
— alex @ GPU不足🥹 (@alexweberk) December 15, 2023
記事: https://t.co/G1OfeXjEXi #note #LLMs #Gemini
今回使った Colab:
この記事が気に入ったらサポートをしてみませんか?