
『退屈なことはPythonにやらせよう』9章 ファイルの読み書きのらくがき帳📝

こんにちは。aliceです。
暑い日が続きますね。ざるそばを見かけると食べたくなります。

今回は『退屈なことはPythonにやらせよう』9章 ファイルの読み書きのらくがき帳です。
もりもりだと思ったら40ページでした。
なので、このnoteももりもりになってしまいました。

前回のらくがき帳📝
では、以下らくがきです。
9章 英語版🔤
GitHub💖
9.1.8 ファイルパスの一部を取得する
pathlibモジュールのPathオブジェクトの属性。
覚えられないやつ。
pathlibモジュール推しです💖
import os
from pathlib import Path
p = Path('09files/9_1_08_get_file_path.py')
print(p.anchor) # ファイルシステムのルート WindowsならC:\
print(p.parent) # 親ディレクトリ 09files
print(p.name) # ファイルやディレクトリ名 9_1_08_get_file_path.py
print(p.suffix) # 拡張子 .py
print(p.stem) # 拡張子を除いたファイル名 9_1_08_get_file_path
print(p.drive) # ドライブ名 WindowsならC:
p = Path.cwd()
print(p.parents[0]) # 親ディレクトリ C:\python\boring_stuff_with_python
print(p.parents[1]) # 親の親ディレクトリ C:\python
print(p.parents[2]) # 親の親の親ディレクトリ C:\
calc_file_path = r'C:\Windows\System32\calc.exe'
os.path.split(calc_file_path) # ('C:\\Windows\\System32', 'calc.exe')
calc_file_path.split(os.sep) # ['C:', 'Windows', 'System32', 'calc.exe']
# pathlibバージョン
path = Path(calc_file_path)
parent_dir, file_name = path.parent, path.name # 最後の要素を取り出す
print(parent_dir, file_name) # C:\Windows\System32 calc.exe
components = list(path.parts)
print(components) # ['C:\\', 'Windows', 'System32', 'calc.exe']9.1.9 ファイルサイズとディレクトリ内容を調べる
os.pathモジュールバージョン
import os
folder_size = os.path.getsize('folder_path\09files')
print(folder_size) # 1007
folder_list = os.listdir(folder_path\09files')
print(folder_list) # ['9_1_08_get_file_path.py', '9_1_09_file_size.py']pathlibバージョン
from pathlib import Path
# pathlibバージョン
file_path = Path('folder_path\09files')
folder_size = file_path.stat().st_size
print(folder_size) # 1007
folder_list = [item.name for item in file_path.iterdir()]
print(folder_list) # ['9_1_08_get_file_path.py', '9_1_09_file_size.py']iterdir関数のif name in {'.', '..'}らへんがすごい!
言われてみればそうだなーと思うけど、これを思いつくには何を何回くらいやったらよいのでしょう?
def iterdir(self):
"""Iterate over the files in this directory. Does not yield any
result for the special paths '.' and '..'.
"""
for name in self._accessor.listdir(self):
if name in {'.', '..'}:
# Yielding a path object for these makes little sense
continue
yield self._make_child_relpath(name)

9.1.10 globパターンでファイルリストを扱う
glob()メソッド、使いこなせるようになりたいメソッド✨
glob()メソッドを使うとlistdir()よりも簡単にファイルを扱えます。
Pathオブジェクトのglob()メソッドは、globパターンを使ってディレクトリ中身一覧を取得します。
glob()メソッドはジェネレーターオブジェクトを返す
from pathlib import Path
file_path = 'folder_path\09files'
p = Path(file_path)
print(list(p.glob('*'))) # すべてのファイルとディレクトリ
print(list(p.glob('*.py'))) # すべての.pyファイル
print(list(p.glob('9_1_0[8-9]*.py'))) # 9_1_08.pyと9_1_09.py
print(type(p.glob('*.py'))) # <class 'generator'>
for python_file in p.glob('*.py'):
print(python_file.name)
9.2.2 ファイルの内容を読み込む
read()メソッド
ファイルを全体を1つの文字列の値として読み込む
obu_file = open('folder_path\obu.txt', encoding='utf-8')
obu_content = obu_file.read() # ファイルの内容を読み込む
print(obu_content)お文具さん
プリンさん
なもさん
ねこさん
ゼリーさんreadline()メソッド
1行ずつの文字列のリストとしてファイルを読み込む
obu_file = open('folder_path\obu.txt', encoding='utf-8')
obu_content = obu_file.readlines() # 1行ずつ読み込んでリストに格納
print(obu_content) #['お文具さん\n', 'プリンさん\n', 'なもさん\n', 'ねこさん\n', 'ゼリーさん']9.2.3 ファイルを書き込む
w:書き込みモード
a:追記モード
# ファイルを書き込みモードで開く
# ファイルが存在する場合は上書き、存在しない場合は新規作成
minion_file = open('folder_path\minion.txt', 'w')
minion_file.write('Bello!\n')
minion_file.close()
# ファイルを追記モードで開く
minion_file = open('folder_path\minion.txt', 'a')
minion_file.write('Tank yu\n')
minion_file.close()
minion_file = open('folder_path\minion.txt')
content = minion_file.read()
inion_file.close()
print(content)書き込み&追記できた🖊

9.3 Shelveモジュールを用いて変数を保持する
Shelveってなんですか??
公式ドキュメント
"シェルフ (shelf, 棚)" は辞書に似た永続性を持つオブジェクトです。 "dbm" データベースとの違いは、シェルフの値 (キーではありません!) は実質上どんな Python オブジェクトにも --- pickle モジュールが扱えるなら何でも --- できるということです。これにはほとんどのクラスインスタンス、再帰的なデータ型、沢山の共有されたサブオブジェクトを含むオブジェクトが含まれます。キーは通常の文字列です。
shelveは動詞でshelfは名詞なんですね。
勉強になりました。

import shelve
minion_greeting = {'Hello': 'Bello',
'Thank you': 'Tank yu',
'Goodbye': 'Poopaye',
}
greeting = shelve.open('my_data') # dbmファイル名で開く
greeting['minion'] = minion_greeting # キーにデータを保存(既存のキーの場合は古いデータを上書き)
print(greeting['minion']) # {'Hello': 'Bello', 'Thank you': 'Tank yu', 'Goodbye': 'Poopaye'}
print(greeting['minion']['Hello']) # Bello
greeting.close()カレントディレクトリにキーと値を持つ辞書のような形式で保存できるということかな?
使いこなせたら便利そう。
9.5 プロジェクト:ランダムな問題集ファイルを作成する
せっかくなのでミニオン語クイズを作りました🍌
選択肢の作り方が「ほぉぉー」となりました。
言われてみればそうだなーと思うけど、これを思いつくには何を何回くらいやったらよいのでしょう?(2回目)
import random
greetings = {
'Hello': 'Bello',
'Thank you': 'Tank yu',
'Goodbye': 'Poopaye',
'I am hungry': 'Me want banana',
'I am sorry': 'Bi do',
}
def create_quiz(question_num):
"""
クイズを作成する
:param question_num: クイズ番号
"""
quiz_filename = f'minion_quiz{question_num}.txt'
answer_filename = f'minion_answer{question_num}.txt'
with open(quiz_filename, 'w') as quiz_file, open(answer_filename, 'w') as answer_file:
quiz_file.write('ミニオンクイズ\n\n')
prefectures = list(greetings.keys())
random.shuffle(prefectures)
for idx, question in enumerate(prefectures):
correct_answer = greetings[question]
wrong_answers = list(greetings.values())
wrong_answers.remove(correct_answer)
wrong_choices = random.sample(wrong_answers, 3)
answer_options = wrong_choices + [correct_answer]
random.shuffle(answer_options)
quiz_file.write(f'{idx + 1}. {question}をミニオン語で言うと?\n')
for i, option in enumerate(answer_options):
quiz_file.write(f" {'ABCD'[i]}. {option}\n")
quiz_file.write('\n')
answer_file.write(f"{idx + 1}. {'ABCD'[answer_options.index(correct_answer)]}\n")
def main():
num_quizzes = 3
for quiz_num in range(1, num_quizzes + 1):
create_quiz(quiz_num)
if __name__ == '__main__':
main()こんな感じのクイズができました。
ミニオンの動画を見るのが楽しくなりますね🍌
よく聞くと、このようなことを言っています。
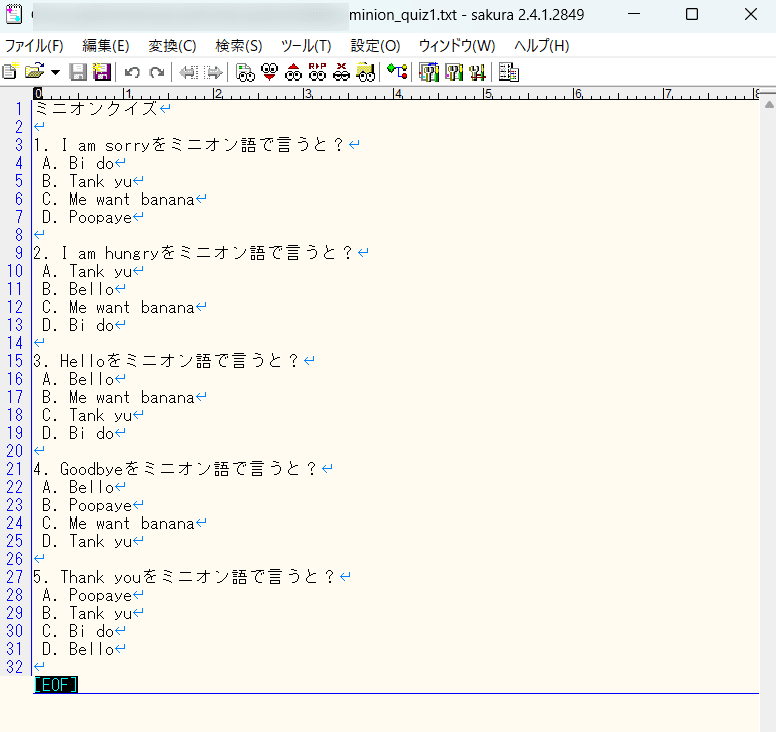
辞書を作るのが面倒なのでExcelから問題になるデータを取得してみました。
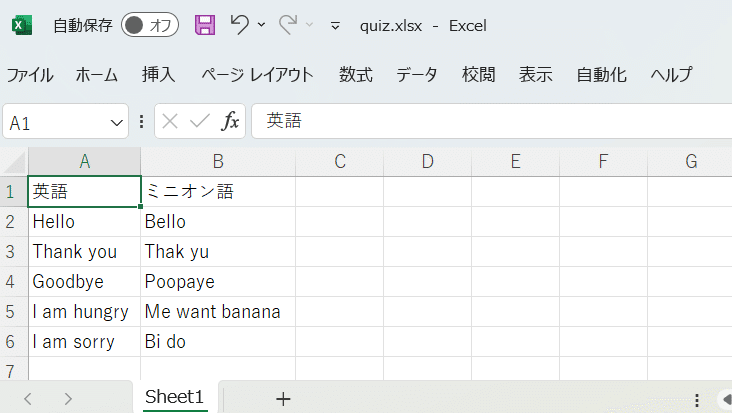
同一ディレクトリのquiz.xlsxのSheet1にデータを入れます。
import random
from openpyxl import load_workbook
def load_greetings_from_excel(file_path):
"""
Excelからデータを読み込む
:param file_path: Excelファイルのパス
:return: データ
"""
workbook = load_workbook(file_path)
sheet = workbook['Sheet1']
greetings = {}
for row in sheet.iter_rows(min_row=2, values_only=True):
key, value = row
greetings[key] = value
return greetings
def create_quiz_files(greetings, num_quizzes):
"""
クイズファイルを作成する
:param greetings:クイズのデータ
:param num_quizzes:クイズの数
:return:
"""
for quiz_num in range(num_quizzes):
with open(f'minion_quiz{quiz_num + 1}.txt', 'w') as quiz_file, \
open(f'minion_answer{quiz_num + 1}.txt', 'w') as answer_file:
quiz_file.write('ミニオンクイズ\n\n')
prefectures = list(greetings.keys())
random.shuffle(prefectures)
for question_num in range(len(prefectures)):
correct_answer = greetings[prefectures[question_num]]
wrong_answers = list(greetings.values())
del wrong_answers[wrong_answers.index(correct_answer)]
wrong_answers = random.sample(wrong_answers, 3)
answer_options = wrong_answers + [correct_answer]
random.shuffle(answer_options)
quiz_file.write(f'{question_num + 1}. {prefectures[question_num]}をミニオン語で言うと?\n')
for i in range(len(answer_options)):
quiz_file.write(f" {'ABCD'[i]}. {answer_options[i]}\n")
quiz_file.write('\n')
answer_file.write(f"{question_num + 1}. {'ABCD'[answer_options.index(correct_answer)]}\n")
def main():
greetings = load_greetings_from_excel('quiz.xlsx')
num_quizzes = 3
create_quiz_files(greetings, num_quizzes)
if __name__ == '__main__':
main()
9.6 プロジェクト:更新可能なマルチクリップボード
サンプルコードをそのまま貼るのもどうかと思ったのでChatGPTにリファクタリングしてもらったら、クラスを使ってくださいました。
import shelve
import sys
import pyperclip
class ClipboardManager:
def __init__(self, db_filename):
self.db_filename = db_filename
self.mcb_shelf = shelve.open(db_filename)
def save_to_clipboard(self, key):
"""クリップボードの内容を保存する"""
self.mcb_shelf[key] = pyperclip.paste()
def load_from_clipboard(self, key):
"""クリップボードの内容を読み込む"""
if key in self.mcb_shelf:
pyperclip.copy(self.mcb_shelf[key])
def list_keys(self):
"""キーの一覧をクリップボードにコピーする"""
key_list = list(self.mcb_shelf.keys())
pyperclip.copy(str(key_list))
def close(self):
"""データベースを閉じる"""
self.mcb_shelf.close()
def main():
if len(sys.argv) < 2:
print("Usage: python script.py <command> [arguments]")
return
command = sys.argv[1].lower()
db_filename = 'mcb.db'
manager = ClipboardManager(db_filename)
if command == 'save' and len(sys.argv) == 3:
manager.save_to_clipboard(sys.argv[2])
elif command == 'list':
manager.list_keys()
elif len(sys.argv) == 2:
manager.load_from_clipboard(sys.argv[1])
manager.close()
if __name__ == "__main__":
main()
9.9.1 マルチクリップボードを拡張する
上の「更新可能なマルチクリップボード」を拡張してdeleteキーワードを指定するとシェルフからキーワードを削除するように変更しましょう。
今回はargparseモジュールで。
import argparse
import pprint
import shelve
import pyperclip
def save_clipboard(mcb_shelf, key):
mcb_shelf[key] = pyperclip.paste()
print(f"クリップボードの内容をキー '{key}' として保存しました。")
def delete_clipboard(mcb_shelf, key):
if key in mcb_shelf:
del mcb_shelf[key]
print(f"キー '{key}' に対応するクリップボードの内容を削除しました。")
else:
print(f"キー '{key}' に対応するクリップボードの内容は存在しません。")
def list_keys(mcb_shelf):
keys = list(mcb_shelf.keys())
values = list(mcb_shelf.values())
values_first_10_chars = [value[:20] for value in values] #20文字まで表示
list_keys_dict = dict(zip(keys, values_first_10_chars))
pprint.pprint(list_keys_dict)
def load_clipboard(mcb_shelf, key):
if key in mcb_shelf:
pyperclip.copy(mcb_shelf[key])
print(f"キー '{key}' に対応するクリップボードの内容を読み込みました。")
else:
print(f"キー '{key}' に対応するクリップボードの内容は存在しません。")
def main():
mcb_shelf = shelve.open('mcb')
parser = argparse.ArgumentParser(description="テキストの断片をクリップボードに保存したり読み込んだりするプログラム")
parser.add_argument('action', help="アクションを指定します。'save': 保存, 'delete': 削除, 'list': 一覧表示")
parser.add_argument('key', nargs='?', help="保存・削除・読み込みするキー(名前)")
args = parser.parse_args()
if args.action == 'save':
save_clipboard(mcb_shelf, args.key)
elif args.action == 'delete':
delete_clipboard(mcb_shelf, args.key)
elif args.action == 'list':
list_keys(mcb_shelf)
else:
load_clipboard(mcb_shelf, args.action)
mcb_shelf.close()
if __name__ == '__main__':
main()
「'Hello': 'Bello'」をコピー(クリップボードに貼り付け)します。
保存します。

一覧を見てみます。

クリップボードに貼り付けます。


本を読んだだけだと何をやりたいかわからなかったのですが、実際に書いてみてようやくわかりました。
9.9.2 文章発生装置
テキストファイルを読み込み、ADJECTIV(形容詞)、NOUN(名詞)、VERB(動詞)、ADVERB(副詞)を書き換える文章発生装置を作りましょう。
自分で書いたのをChatGPTにリファクタリングしてもらったけど、main関数がすごいな。
言われてみればそうだなーと思うけど、これを思いつくには何を何回くらいやったらよいのでしょう?(3回目)
import pyinputplus as pyip
def change_text(adjective, noun, verb, adverb, file_path):
with open(file_path, 'r') as f:
content = f.read()
placeholders = {'ADJECTIVE': adjective, 'NOUN': noun, 'VERB': verb, 'ADVERB': adverb}
for placeholder, replacement in placeholders.items():
content = content.replace(placeholder, replacement)
with open(file_path, 'w') as f:
f.write(content)
def main():
file_path = 'file_name.txt'
prompts = {
'形容詞を入力してください: ': 'adjective',
'名詞を入力してください: ': 'noun',
'動詞を入力してください: ': 'verb',
'副詞を入力してください: ': 'adverb'
}
user_inputs = {key: pyip.inputStr(prompt) for prompt, key in prompts.items()}
change_text(**user_inputs, file_path=file_path)
if __name__ == '__main__':
main()このテキストの文章を変えます。

9.9.3 正規表現検索
ディレクトリの中のすべての.txtファイルを開いて、ユーザーが指定した正規表現にマッチする行を検索し、結果を画面に表示するプログラムを書きましょう。
import re
from pathlib import Path
import pyinputplus as pyip
def search_files_for_pattern(directory_path, pattern):
for filename in Path(directory_path).iterdir():
file_path = str(filename)
with open(file_path, encoding='utf-8') as file:
for line in file:
if re.search(pattern, line):
print(f'{filename.name}: - {line}')
def main():
dir_path = 'folder_path'
re_str = pyip.inputStr('正規表現を入力してください: ')
search_files_for_pattern(dir_path, re_str)
if __name__ == '__main__':
main()
これ、いろんなパターンで使えそうなので、PySimpleGUIバージョンで書き直してもらいました。
import re
from pathlib import Path
import PySimpleGUI as sg
def search_files_for_pattern(directory_path, pattern):
result_text = ""
for filename in Path(directory_path).iterdir():
if filename.is_file() and filename.suffix.lower() == '.txt':
file_path = str(filename)
with open(file_path, encoding='utf-8') as file:
for line in file:
if re.search(pattern, line):
result_text += f'{filename.name}: - {line}\n'
return result_text
def main():
sg.theme('DefaultNoMoreNagging') # テーマを設定
layout = [
[sg.Text('検索するディレクトリのパス: '), sg.InputText(key='dir_path'), sg.FolderBrowse()],
[sg.Text('正規表現を入力してください: '), sg.InputText(key='re_pattern')],
[sg.Button('検索'), sg.Button('終了')],
[sg.Text('検索結果:')],
[sg.Multiline('', key='result_text', size=(50, 10))]
]
window = sg.Window('ファイル検索ツール', layout)
while True:
event, values = window.read()
if event == sg.WINDOW_CLOSED or event == '終了':
break
elif event == '検索':
dir_path = values['dir_path']
re_pattern = values['re_pattern']
result_text = search_files_for_pattern(dir_path, re_pattern)
window['result_text'].update(result_text)
window.close()
if __name__ == '__main__':
main()
いい感じです。
ファイル名とかテキストファイル以外でもやりたい。

徐々に退屈ではなくなってきました。

この記事が気に入ったらサポートをしてみませんか?