
音声合成を使った音声認識のためのデータ作成とその結果

こんにちは、メディア研究開発センターの山野です。最近よく聞くポッドキャストはダブルヒガシさんの「はちくちダブルヒガシ」です。
動機
音声認識のモデル構築は一般的に音声とその書き起こしのペアデータセットを必要とします。そのようなデータセットを一から構築することは、大変コストがかかる作業になります。
今回は音声合成を使った人手を介さない(≒コストのかからない)データセットの構築と実験をしたので、その結果を共有しようと思います。
データセット
入力文
JNCデータセットからランダムサンプリングしたものを入力文として音声を生成します。JNCデータセットのサンプルは以下の通りです。
…
"kiji": ["2006年度の朝日賞を6氏に贈ります。", "各界からの推薦をもとに、朝日新聞文化財団と朝日新聞社の選考委員会(委員長=秋山耿太郎同財団理事長・朝日新聞社長)が審議し、決定しました。", "今月29日に東京・日比谷の帝国ホテルで贈呈式を行い、正賞のブロンズ像と副賞(1件500万円)を贈ります。"]
…
"kiji"を入力文としたいところですが、音声合成は長文の生成が難しいことが事前の実験で判明しました。今回の実験では、65文字以内に収まるように句点で分割し複数の文章に展開します。
結果として、4219文を音声合成処理を行う対象文としました。
id,text
1,最終日の23日には「世界核被害者人権憲章」を採択して、「核なき世界」へ向けた国際ネットワークづくりをめざす。
2,違法な看板などを規制する屋外広告物法が昨年改正されたが、街の美化だけでなく、安全対策に結びつける条例化の動きが出ている。
3,1月の市長選では、候補者7人のうち4人が18階建てなどを問題視し、建設計画見直しを訴えていた。
...
4219,利根川上流域の8月の降水量は14ミリで、平年の7%にとどまっている。音声合成
VALL-E-X (OSS実装) と Bark、2つの手法を用いてテキストから音声を生成します。特にBarkは話者を指定したり、プロンプトによってはため息や笑い声などを生成することができます。
最終日の23日には「世界核被害者人権憲章」を採択して、「核なき世界」へ向けた国際ネットワークづくりをめざす。
上記の文に対してVALL-E-XとBark、それぞれで生成された音声は以下の通りです。
ここで、生成時のパラメータはデフォルト値としています。
このようにして構築したデータセットを以後、「clean_vallex_dataset」、「clean_bark_dataset」とします。
ひと工夫
上記の2例から分かる通り、音声の品質はとても良いことがわかります。しかし、音声認識のためのデータという観点ではもう少し工夫したいところです。今回は以下のようなノイズ重畳パイプラインを作り、より実運用に近いノイジーなデータを作ります。
入力文を分かち書き
分かち書きした文を予め指定した数にまとめ上げる
2で分割した各文を入力として音声合成
3で合成したものに各音声に対してノイズ重畳
4の音声の速度を0.9-1.25の範囲でタイムストレッチ
分割した各音声を連結
ここで、分かち書きは SudachiのMode Cを、ノイズは独自で収集した背景雑音データセットを使いました。
後処理パイプラインによってできた音声は以下の通りです。
ノイズ重畳パイプラインをもっと作り込めることもできそうですが、少なくともデフォルトの音声合成データよりはノイジーなデータとなっていることがわかります。
このようにして構築したデータセットを以後、「noisy_vallex_dataset」、「noisy_bark_dataset」とします。
実験
OpenAI/WhisperのmediumモデルをFine-tuningすることを前提とし、各実験結果を見ていただければと思います。
評価データセットは、約10時間分の朝日新聞評価データセットと、1.5時間分のJTubeSpeechで収集したYoutube動画になります。詳しくはこちらの記事をご覧ください。
実験1: 音声合成の有効性
まず音声合成が有効かどうかを検証してみました。
baselineがOpenAI/Whisperのミディアムモデルで、Fine-Tunedは「clean_vallex_dataset」でFine-Tuningしたモデルです。

ここで、CER/WERはそれぞれ文字誤り率、単語誤り率を表しています。
朝日新聞評価データセットに対しては、CER/WER共に性能向上しました。一方で、JTubeSpeech評価データセットに対してはCER/WER共に性能が低下しました。
この実験から音声合成を使ったデータセット構築は一長一短であることがうかがえます。音響的/言語的なドメインが一致/不一致している可能性や、OpenAI WhisperがYouTubeデータを多く学習している可能性などが考えられます。
実験2: 音声合成モデルの違いによる性能差
次に「clean_vallex_dataset」と「clean_bark_dataset」で構築したモデルの性能差をみます。

VALL-E-Xで構築したモデルの方が性能が良いことがわかりました。以後、VALL-E-Xのみで実験結果を観察することにします。
実験3: ノイズ重畳パイプラインの有効性
次にノイズ重畳パイプラインが有効かどうかをみます。
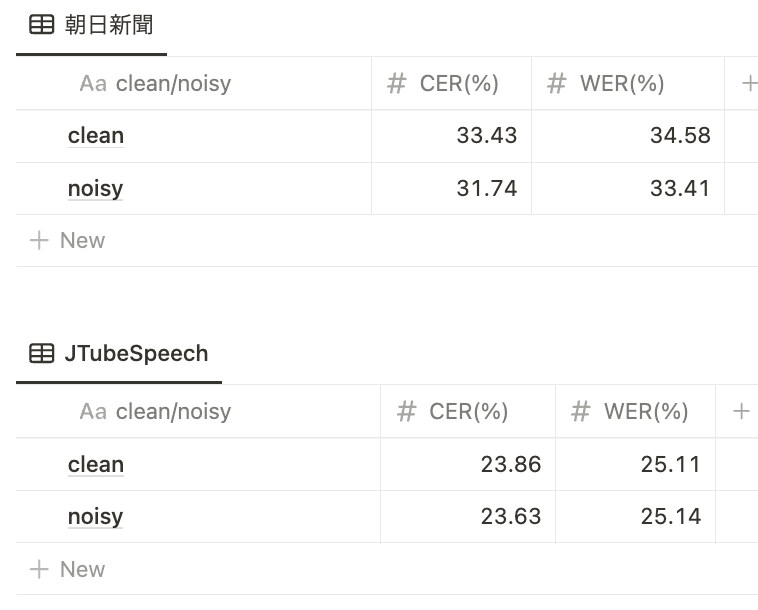
少なくとも朝日新聞評価データセットに対しては有効であることがわかりました。朝日新聞評価データセットは話者が頻繁に交代したり、ノイジーな音声が多く含まれているため、似たような分布になっているのかもしれません。
まとめ
今回は音声合成を使って音声認識のデータセット構築とその実験結果を共有させていただきました。
簡易な検証ではありましたが実験結果から以下のように結論づけることができそうです。
実験1、3より、音声認識対象となる音声のドメインがマッチしていれば音声合成によるデータ拡張は有効である。
実験2より、データ拡張時の音声合成の手法とそれによる音声認識モデルの性能には相関がある。
今後はより詳細に音声合成を使ったデータ拡張について検討していければと思います。
最後まで読んでいただきありがとうございました。
(メディア研究開発センター・山野陽祐)