
アノテーションツール「Label Studio」のご紹介【無料でどこまでできる?】

こんにちは。メディア研究開発センター(M研)の嘉田です。今回は私がよく使うアノテーションツール「Label Studio」についてのお話です。
機械学習におけるアノテーションとは、モデルを訓練するための教師データを作成する作業のことです。以前にM研の杉野さんからアノテーションツールprodigyについてのご紹介がありましたので、ぜひこちらの記事もご覧ください!
Label Studioとは
Label StudioはHeartexという会社が提供しているオープンソースのアノテーションツールです。様々な種類のデータ(音声・画像・テキスト・時系列データ…)、幅広いタスクに対応しています。
Label Studioは基本的に無料で使用できます。 機能拡張やサポートが受けられる有償版もあるようですが、個人で使う分には無料機能で十分な印象です。詳しくは下記ページなどをご参照ください。
なお、今回は他ツールとの比較などは行っていませんので悪しからず…。
というのも、筆者がアノテーションツールとしてLabel Studioを使い始めたのに、特別な理由などはありません。たまたまです。
とはいえ、環境構築が難しいツールも多い中(お恥ずかしいことに他のツールでうまくいかなかった経験あり)、これまで特に不自由なく利用できてきたので、これも何かの縁ということで今もお世話になっています。
何ができる?
Label Studioで行える代表的なアノテーションタスクは以下の通りです。Computer Visionに強い印象でしたが、改めて確認するとたくさんありますね。

下記ページからデモが試せます。セットアップ不要でアノテーションの雰囲気がつかめるので、ぜひ一度ご覧ください。
また、上記以外のタスクのテンプレートも用意されています。数えてみると、全部で56種類もありました!(2022/10/20時点)
直近(バージョン1.6.0)に追加されたテンプレートはVideo Object Detection and Trackingのようです。今後も増えていくのでしょうね。
下記ページから全てのテンプレートが確認できます。基本的なタスクは全てカバーしていそうです。無料なのに立派だなぁと思っています。
Label Studioの特徴
ずばりこれです(雑)。

中でも筆者の感じる素敵ポイントは下記です。
Flexible and configurable
先程テンプレートの豊富さをご紹介しましたが、豊富なだけではありません。カスタマイズが可能であり、テキストエリアなどを自由に追加できるため、
「ファイルパスを表示させたい!」
「見直すときのためにコメントを書けるところが欲しい!」
といった筆者の要望に応えてくれました。ML-assisted labeling
Label Studioは機械学習パイプラインとの統合によって、より効率的なアノテーションが行えます。具体的には下記が可能です。Pre-labeling:モデルの予測結果をもとに、アノテーターが手動で正確なアノテーションを行う。
Auto-labeling:学習済みモデルを使って自動でアノテーションを行う。
Online Learning:アノテーション結果を随時取り込んでモデルを再学習する。
Active Learning:モデルの予測精度を向上させるために有用なデータを選択し、アノテーターが手動でアノテーションを行う。
執筆に際し、Pre-labelingを使ってみましたので、そちらもご紹介できたらと思います。
実際に使ってみよう
インストール
Label Studioの導入はとても簡単です。pip・Docker・brewなどでインストールできます。今回はpipでのインストール手順をご紹介…といっても下の1行を実行するだけです。
pip install -U label-studio※ Python 3.7以降に対応
バージョンは執筆当時最新の1.6.0をインストールしました。
起動
label-studio start上記を実行して、http://localhost:8080にアクセスします。
デフォルトのポートは8080ですが、変更したい場合は--portオプションでポートを指定します。その他のオプションは下記をご参照ください。
アカウント作成・ログイン
SIGN UPからメールアドレスとパスワードを登録し、アカウントを作成します。アカウント作成済みの場合はLOG INします。
プロジェクト作成
Create Projectから以下の手順で作成します。
1. プロジェクト名設定
自由に設定します。
2. データのImport
Label Studioは様々な方法でデータのImportが可能です。ブラウザからサクッとアップロードすることも、クラウドストレージと同期することも可能です。
ローカルに置いているデータの登録に関しては下記記事にて詳しく説明されているので、こちらをご参照ください。
3. ラベリング設定
テンプレートを選択し、ラベリング設定を行います。例としてImage classificationのテンプレートを選択すると、このような設定画面となります。
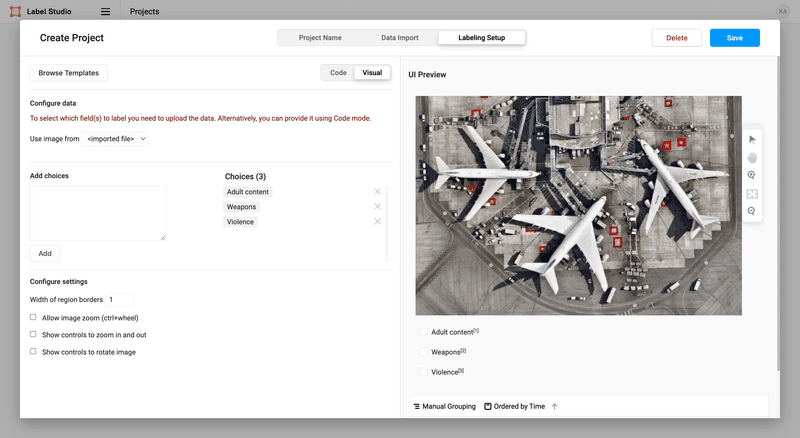
ラベリング設定はCode・Visualのどちらからでも可能です。簡単な設定のみで良い場合はVisualのAdd choicesからラベルを追加するだけでOKです。後ほど実際の設定Codeもご紹介します。
4. プロジェクト作成完了
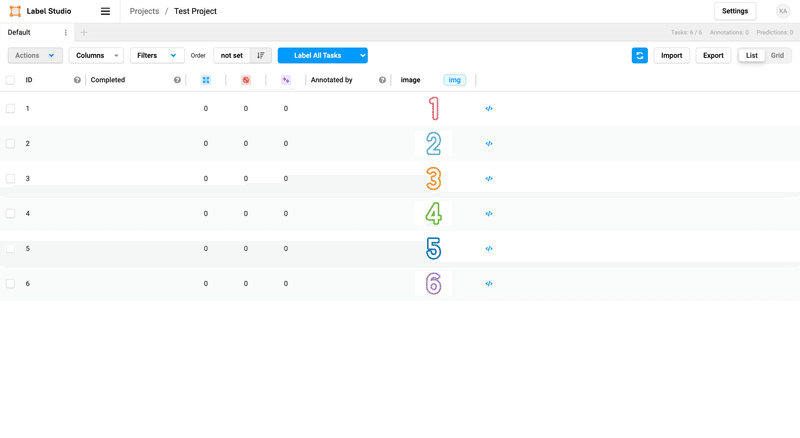
上記手順を完了すると、プロジェクト画面へと遷移します。ここではImportしたデータのアノテーション状況が確認できます。
右上のImportからデータを追加したり、Settingsでラベリング設定を修正したりできます。
いざアノテーション
プロジェクト画面でLabel All Tasksをクリックし、アノテーションを始めます。
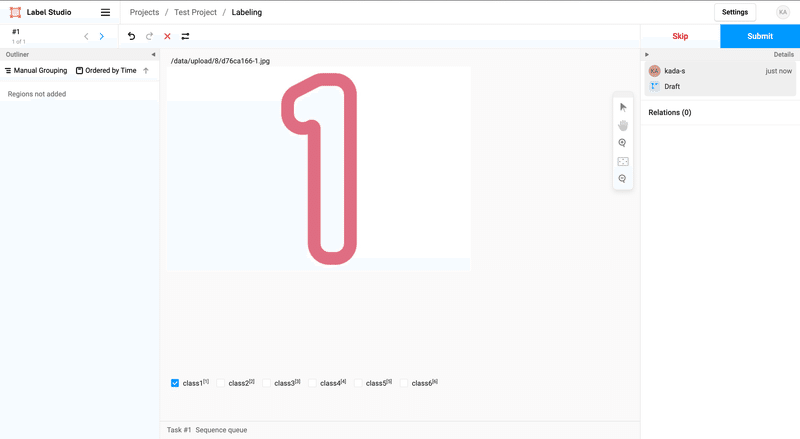
後ほど実例もご紹介しますが、基本的には
アノテーション作業
完了したらSubmit
を繰り返します。飛ばしたいデータはSkipも可能です。
全データのアノテーションが完了すると、このような画面へと遷移します。
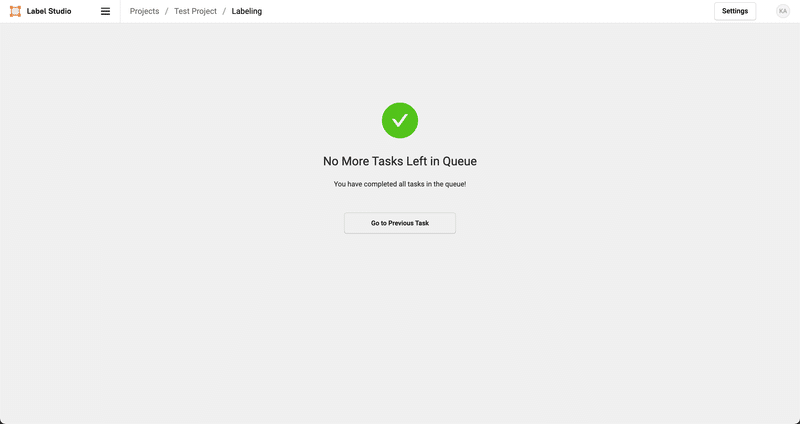
また、アノテーション結果は何度でも自由に編集・更新が可能です。更新時にはUpdateをクリックします。
結果をExport
プロジェクト画面からExportをクリックすると、出力フォーマットを選択できます。
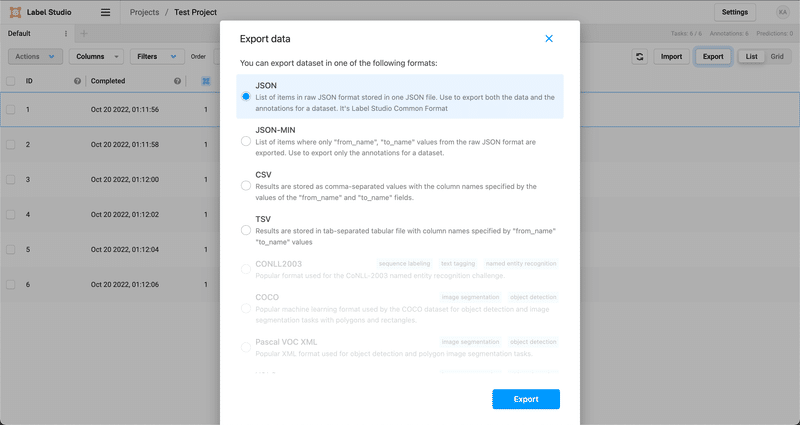
Image classificationの場合はJSON、CSVなどが用意されています。Object detectionの場合はCOCOフォーマット、YOLOフォーマットなど、モデルの学習時に必要なフォーマットが用意されており、出力後に変換が不要なのでありがたいです。
右下のExportをクリックするとダウンロードが実行されます。出力フォーマットによっては、Importしたデータも一緒にダウンロードされます。
アノテーション実例紹介
では実際のアノテーションの様子を、筆者がこれまでにLabel Studioでアノテーションに取り組んだタスク
Image classification・Speaker diarization・Object detection
にてご紹介します。
※ 実際のデータではなく、サンプルデータを使っています。
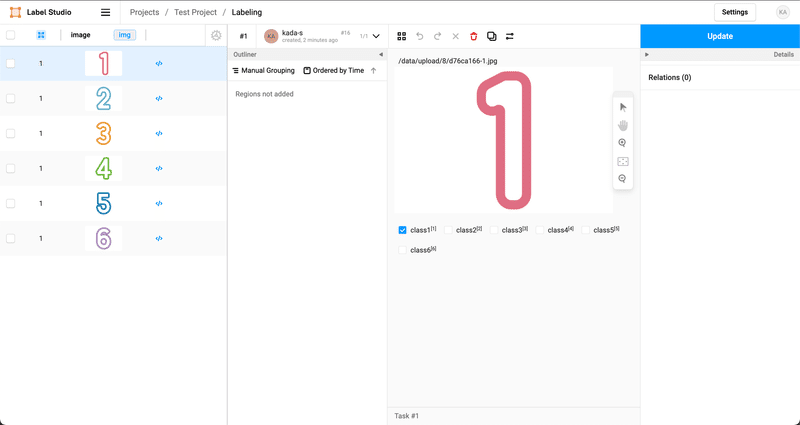
Image classification
独自データで画像分類モデルを構築するための教師データ作成(6クラスの分類、全8,000枚ほど)をしました。
ラベリング設定は下記の通りです。
<View>
<Text name="text" value="$image"/>
<Image name="image" value="$image"/>
<Choices name="choice" toName="image" showInLine="true">
<Choice value="class1"/>
<Choice value="class2"/>
<Choice value="class3"/>
<Choice value="class4"/>
<Choice value="class5"/>
<Choice value="class6"/>
</Choices>
</View><Choice>タグで各クラスを定義します。<Image>タグはアノテーション対象の画像の表示のため、<Text>タグは画像上部に画像パスを表示するために定義しています。
どんなタスクも基本的にはテンプレートのコピペで問題ありません。カスタマイズしたいときには、タグを追加したり、属性を修正・追加します。各タグの詳細は下記ページをご参照ください。
こちらがアノテーションの様子です。
画面下部のラベルを選択後、Submitをクリックすると次のデータに進みます。
ここではキーボードショートカットを使っています。ラベルの右上に表示されている数字をキーボードで入力することで、ラベルを選択できます。SubmitもMacであれば⌘+Enterで実行できます。キーボードショートカットがあるとサクサク進むのでありがたいです。
Speaker diarization
日本語話者分離タスクの評価データ作成(約2時間分)をしました。
ラベリング設定は下記の通りです。
<View>
<Text name="text" value="$audio"/>
<Labels name="label" toName="audio" choice="single">
<Label value="Speaker1"/>
<Label value="Speaker2"/>
<Label value="Speaker3"/>
<Label value="Speaker4"/>
</Labels>
<AudioPlus name="audio" value="$audio"/>
</View><Label>タグで話者ラベルを定義します。話者数があらかじめわかっている場合は、その分だけラベルを定義すれば良いです。わからない場合は適当な数を定義しておきましょう。後からラベルを追加できます。
さらに、<AudioPlus>タグで音声プレイヤーを定義します。
アノテーションの様子はこちら。
※ 音量にご注意ください。
今回使用した音声ファイルは話者が一人ですが、話者が複数人いる場合にはラベルを切り替えてアノテーションしていきます。デモのようにラベルを間違えてしまった場合もササッと直せます。
また、速度やスケールが簡単に変えられるのも便利です。最初はSpeed 0.75で丁寧にやって、最終確認はSpeed 2.0でラベルの間違いがないかのみを確認したりしていました。
Object detection
独自データで物体検出モデルを構築するための教師データ作成(10クラスの検出、全300枚ほど)をしました。
ラベリング設定は下記の通りです。
<View style="display: flex;">
<View style="width: 150px; padding: 0 1em; margin-right: 0.5em; background: #f1f1f1; border-radius: 3px">
<RectangleLabels name="label" toName="image" canRotate="true">
<Label value="class1" background="red"/>
<Label value="class2" background="orange"/>
<Label value="class3" background="brown"/>
<Label value="class4" background="blue"/>
<Label value="class5" background="purple"/>
<Label value="class6" background="yellow"/>
<Label value="class7" background="pink"/>
<Label value="class8" background="grey"/>
<Label value="class9" background="cyan"/>
<Label value="class10" background="green"/>
</RectangleLabels>
</View>
<Image name="image" value="$image"/>
</View>視認性向上のため、各ラベルの色を個別に設定しています。また、縦長の画像を扱っていたため、ラベルの位置などを工夫しています。このあたりのカスタマイズも自由にできます。
アノテーションの様子はこちら。
デモは簡単なケースですが、実際はクラス数も物体数も多く、かなり疲れました…。Object detectionでもかなり大変だったので、より厳密なラベル付けが必要なSemantic segmentationなどのアノテーションには戦意喪失状態です。
Pre-labelingをやってみた
気になっていた機能ということで、機械学習モデルを用いたPre-labelingを試してみました。今回は簡単に試せるチュートリアルを動かしました。今後カスタムモデルでもやってみたいです。
チュートリアルの中でもOpenMMLabのMMDetectionを活用したObject Detectionのタスクをやってみます。ちなみに、OpenMMLabのMMシリーズは本当に便利です。随時最新のモデルが取り込まれており、簡単にSOTAモデルを使えます。
モデルのダウンロード
MMDetectionの環境構築は公式リポジトリの通りに進めました。
※ torch、torchvisionがないと怒られたら随時インストールしてください。
pip install -U openmim
mim install mmcv-full
pip install mmdetモデルはチュートリアルに従ってFaster R-CNNを使用します。 モデルとconfigファイルをローカルにダウンロードするため、下記のコマンドを実行します。
mim download mmdet --config faster_rcnn_r50_fpn_1x_coco --dest ./checkpoints--configオプションでダウンロード対象のモデルを指定します。 このコマンドでモデルをダウンロードすると、configファイルも一緒にダウンロードされるのでおすすめです。
ML Backend設定
ML Backendサーバーの設定・起動を行います。
まず、環境構築として下記のコマンドを実行します。
git clone https://github.com/heartexlabs/label-studio-ml-backend
cd label-studio-ml-backend
pip install -U -e .次にML Backendの初期化を行います。label-studio-ml-backendディレクトリ配下で下記コマンドを実行します。
label-studio-ml init coco-detector --from label_studio_ml/examples/mmdetection/mmdetection.pyするとcoco-detectorというディレクトリができます。中身はこんな感じです。
docker-compose.yml Dockerfile mmdetection.py README.md requirements.txt _wsgi.pyでは、ML Backendサーバーの起動です。configファイルとモデルのパスを絶対パスで指定します。
label-studio-ml start coco-detector --with \
config_file=/home/kada/label-studio-tutorial/checkpoints/faster_rcnn_r50_fpn_1x_coco.py \
checkpoint_file=/home/kada/label-studio-tutorial/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth※ GPUでモデルを動かしたいときにはdevice=gpu:0のように指定して実行します。
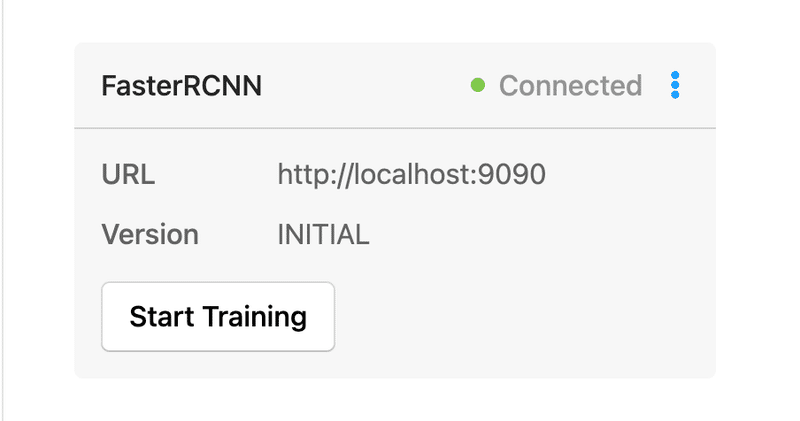
上記を実行してhttp://localhost:9090(デフォルトのポートは9090)にアクセスすると、下記のような画面となります。

これでML Backendサーバーの起動は完了です。
ラベリング設定
Label Studioを起動し、Object detectionのプロジェクトを作成します。
ラベリング設定のCodeには下記を貼り付けます。
<View>
<Image name="image" value="$image"/>
<RectangleLabels name="label" toName="image">
<Label value="Cat" predicted_values="cat" background="red"/>
<Label value="Dog" predicted_values="dog" background="blue"/>
</RectangleLabels>
</View>ここで、predicted_values属性にCOCOラベル名を入れます。実際にラベルとして表示・選択できるのはvalue属性になります。
プロジェクトが作成できたら、SettingsからMachine Learningのページを開きます。Add Modelをクリックし、先程起動したML BackendサーバーのURL(http://localhost:9090)を貼り付けます。
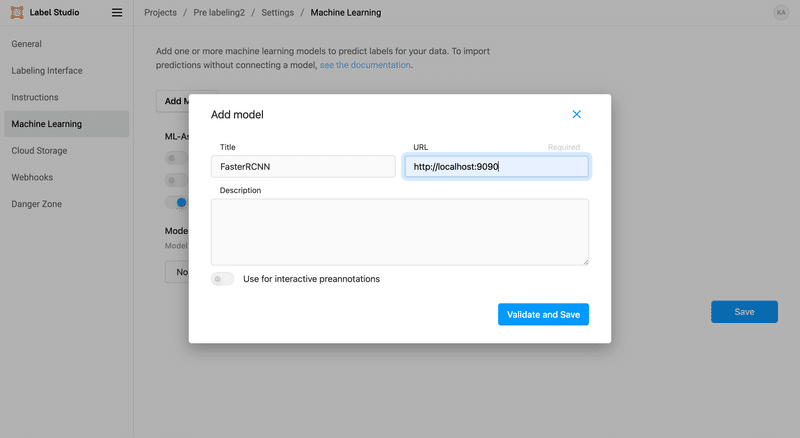
ここまでうまくできていればConnectedと表示されるはずです。
これで設定はバッチリです。
アノテーション
プロジェクト画面から先程も使用した犬・猫の画像を選択します。
するとこのように、既にバウンディボックスが表示されています!これがモデルの予測結果です。
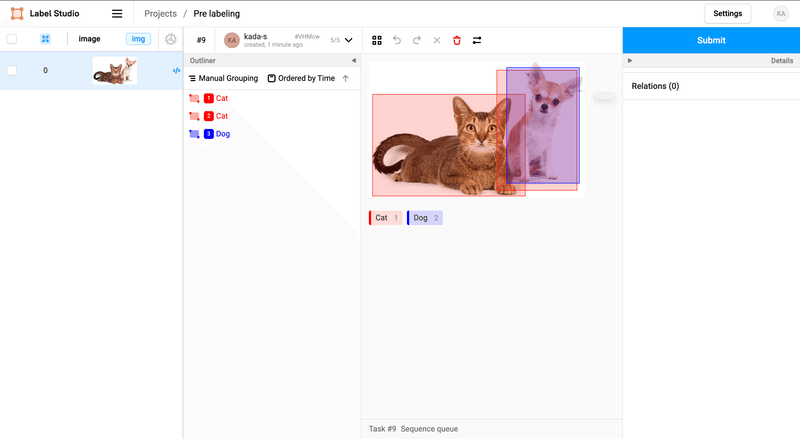
赤色ボックスが猫ですが、一つ誤検出していますね…。信頼スコアは低めです。
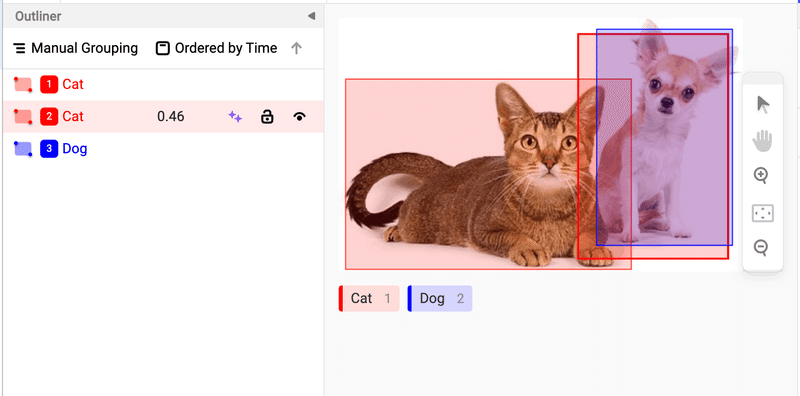
ということでスコアの閾値調整をしてみます。
score_thresholdを指定して、再度ML Backendサーバーを起動します。
label-studio-ml start coco-detector --with \
config_file=/home/kada/label-studio-tutorial/checkpoints/faster_rcnn_r50_fpn_1x_coco.py \
checkpoint_file=/home/kada/label-studio-tutorial/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
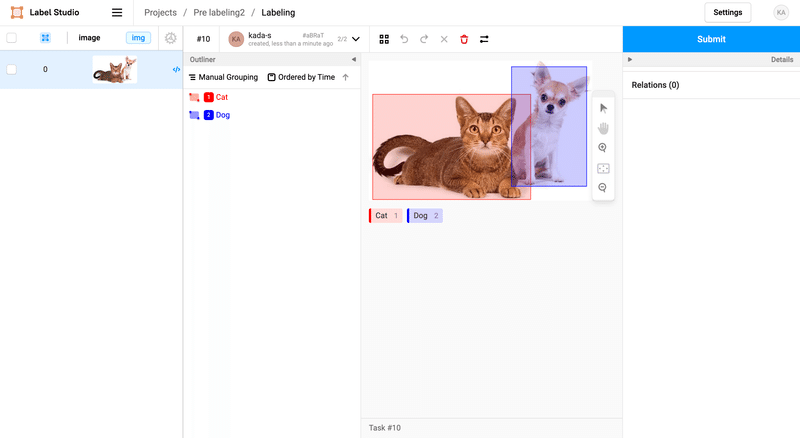
score_threshold=0.5いい感じです!少し調整するだけで、すぐにSubmitできそうですね。
最後に
今年はたくさんアノテーションしました。アノテーションのような単純作業が頭のリフレッシュになるときもあれば、しんどくなるときもありました。が、全てはより良いモデル構築のため。これからも機会があれば全力でアノテーションを頑張ります。
ところで筆者は長いこと古いバージョンを使っており、この記事を書くにあたって最新バージョンにしました。アップデートに驚きました…。
教訓:リリースノートは定期的に確認しましょう(とりあえず筆者は公式Slackに参加しました)。
(メディア研究開発センター・嘉田紗世)