
社内向け文字起こしサービス「YOLO」のご紹介

はじめに
メディア研究開発センターの山野です。
そろそろコーヒーを砂糖・ミルクなしで飲めるようになりたいお年頃(もうすぐ30歳)です。
さて、約2年ほど前から社内向けの文字起こしサービスを開発しており、最近大型のアップデートをしたこともあり、これまで行ってきたことを一部紹介させていただきます。
サービス名
早速ですが、このサービスは社内でYOLOという名前で親しまれています。
(”YOLO”は物体検出の手法で有名ですね、またネット上でもスラングで使われているそうです)

「ファイルだったらなんでもアップロードしてOK、あとはうまく処理しまっせ」
みたいな願いを込めたサービスです。
活用実績
2021年1月にリリースしました。リリース以降、社内でどれぐらい使われているかを、縦軸は処理時間、横軸は四半期で示したのがこちらになります。
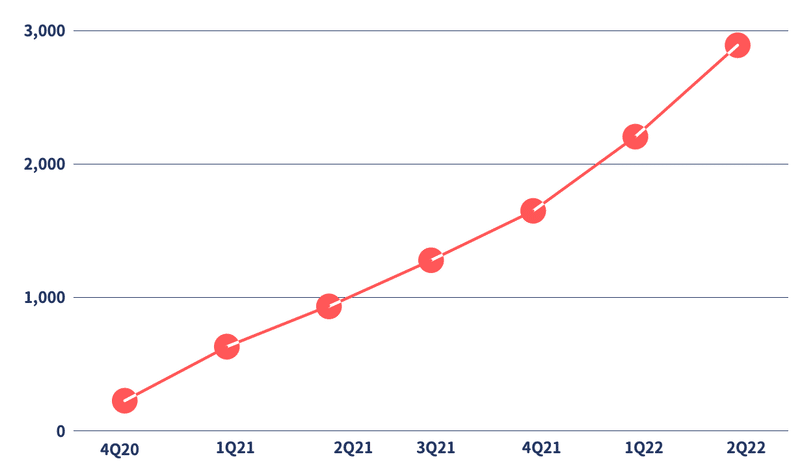
社内で様々な用途で使われ始めています
後述しますが、サービスの特性上社員がより使ってくれれば使ってくれるほど、機械学習のためのデータが蓄積されていくような仕組みを構築しております。
このまま右肩上がりのグラフが描けるよう、どんどん改善していきより良いサービスにしていきたいです。
できること
YOLOでできることは、ざっくりと以下の通りです。
音声や動画、画像の文字起こし
文字起こしされたファイルの蓄積・検索・共有
自動で見出しを付与したり、動画の場合はサムネイルを自動で付与

音声や動画、画像の文字起こしを行い、それらのマルチメディアをシームレスに検索できる基盤を構築しています。
また、動画がアップロードされた際にはサムネイルを自動で選択する機能を有しており、検索画面ではその機能によって得られたサムネイル5枚が表示される仕組みとなっております。
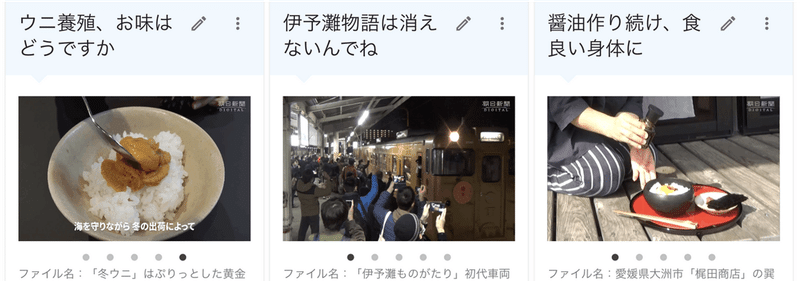
サムネイル選択の手法は、以下のエントリで詳細に書かれていますので、興味のある方はご覧ください。
上記のエントリをお読みになった方は、サムネイル選択をする上でテキスト情報が必要であることがわかったかと思います。そこでYOLOは、自動要約生成API「TSUNA」を活用して自動で見出しを生成しています。「ウニ養殖、お味はどうですか」や、「伊予物語は消えないんでね」などは、音声認識テキストをインプットとしてTSUNAで自動生成した結果となります。
ご興味のある方は以下のURLよりTSUNAを試してみてください。
何を作ってきたか
都合上、システム構成を載せることはできませんが、基本的にAWSで構築しています。
日々発生するバグ対処などに追われることも多くありますが、頑張っていくつかの新機能や基盤を作ってきました。
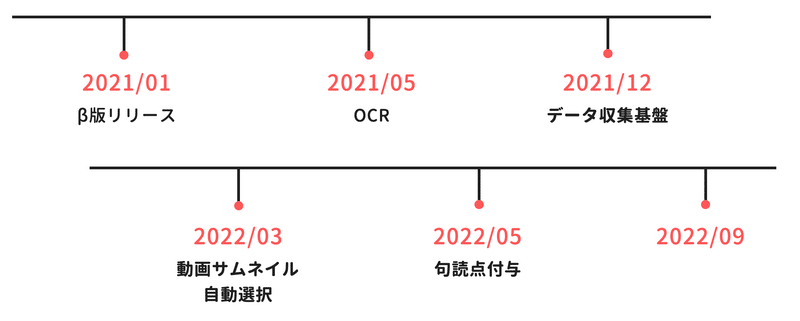
OCRや動画サムネイル自動選択はすでに触れているので、ここでは「データ収集基盤」とそれに続くモデル構築について少しだけご紹介させていただきます。
また、「2022/09」が空白ですがここは最後に少し触れます。
データ収集基盤
大前提として「データ収集基盤」は、「音声認識のための音声とテキストのペアデータセットを効率良く収集するための基盤」を指しております。
そのため以下のようなサイクルを効率よく回せることが理想です。
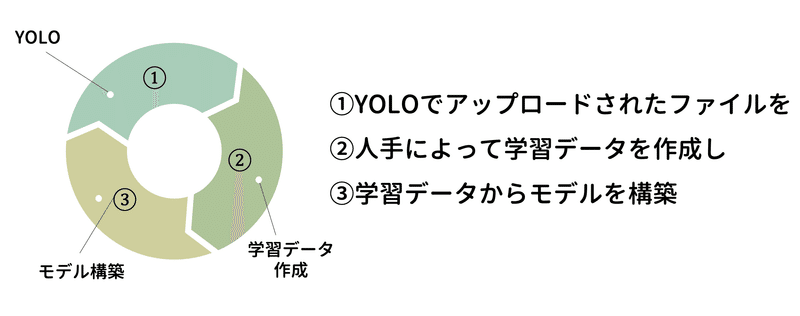
それでは、この3ステップをYOLOはどのように実現しているのかを順に説明します。
「①YOLOでアップロードされたファイルを収集」
まず、学習データとして活用していいかどうかを、ファイルをアップロードする際にユーザーに選択してもらうようにしています。
なお、学習データとして活用するファイルは、社内会議や公の記者会見とし、個人情報やセンシティブな情報が含まれるファイルは使わないようにしています。

次に、チェックの有無がデータベースに格納され、”提供可”ファイルは社内のオンプレGPUサーバーに日次で取り込まれるような仕組みを構築しました。
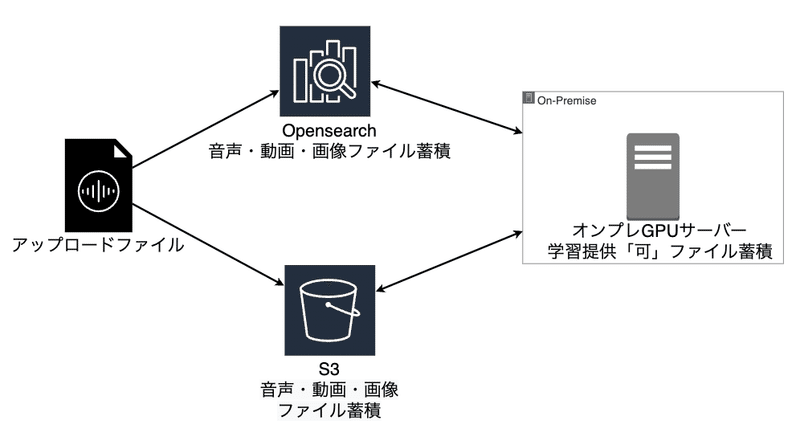
大まかな流れとしては、文字起こし結果とファイルをOpenSearchとS3に格納し、提供可ファイルについては日次でオンプレGPUサーバーに蓄積する、というような仕組みとなっています。
以上が「①YOLOでアップロードされたファイルを収集」パートの説明となります。
「②人手によって学習データを作成」
ここが一番大変で重要な部分です。
朝日新聞社は「ビジネス・アシスト・オフィス」(BAO)という組織があります。こちらは、障がいのある人たちが安心して働ける職場として人事部の中に設けている部署となっており、社内のいろいろな業務を文字通り「アシスト」している部署となっています。
音声認識用のデータ作成でも「アシスト」してもらっており、日々の作業を端的に表したのがこちらになります。
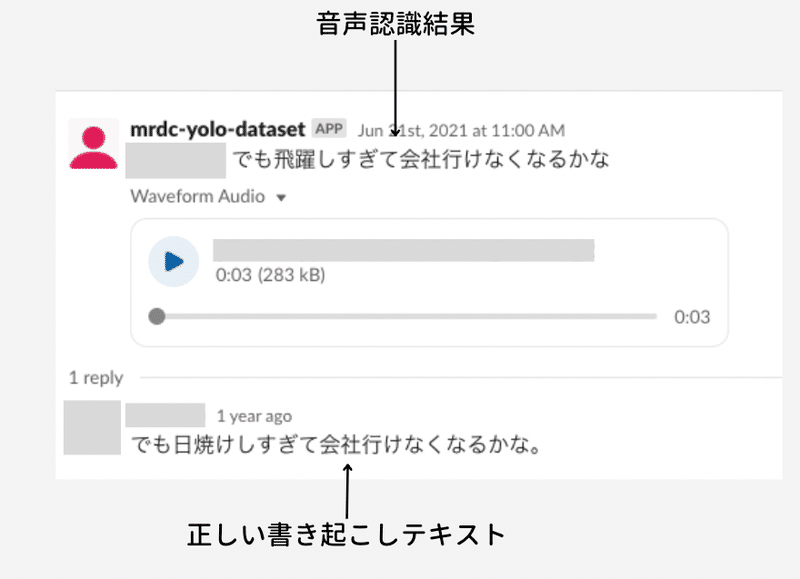
Slackを用いてデータ作成を日々行っています。音声認識結果に対してBAOの方々が音声を聞きながら書き起こし、スレッドで返信します。この例では、音声認識モデルが”日焼け”を”飛躍”と誤認識していることがわかります。
スレッドで返信したBAOの方々による書き起こしテキストは、オンプレGPUサーバーで日次で収集します。正しいデータが日々蓄積されていくような仕組みとなっております。
「③学習データからモデルを構築」
最後にこれまで収集・作成してきたデータからモデルを構築します。
モデル構築フローは長くなりそうなので割愛します。
独自で構築した評価データセットに対してCER(文字誤り率)とWER(単語誤り率)でモデルの評価を行った結果が以下の通りです。
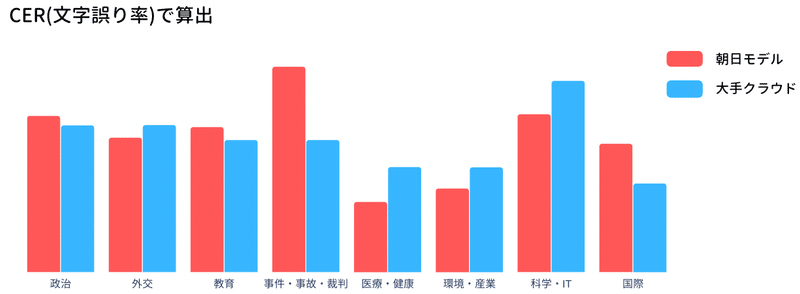
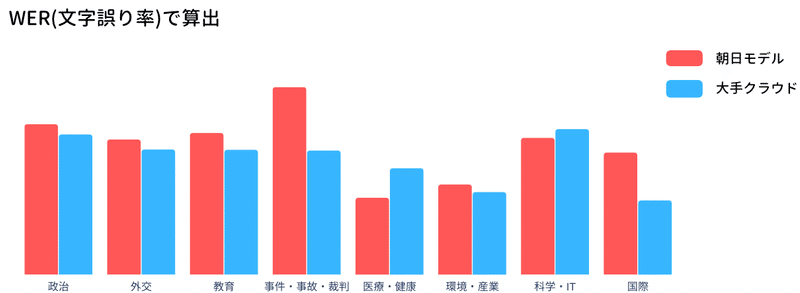
現在YOLOの音声認識エンジンは大手クラウドモデルを用いて文字起こしを行っておりますが、今後さらに朝日モデルの性能が向上した場合リプレイスを行う予定です。
音声認識エンジンの具体的な手法などは別の機会に紹介させていただければと思います。
最近のアップデート
少し話は変わりますが、冒頭でもお話ししたように2022年9月に大型アップデートをしました。リリースした項目は以下の通りです。


「AWS CDK」 や「検索速度向上」、「フィラー・相槌検知」などはこれまた別の機会にでもご紹介させていただければと思います。
まとめと今後の展望
社内向けに展開している文字起こしサービスYOLOのご紹介をさせていただきました。
より多くの社員に日常的に使ってもらえるように、日々機能改善し、より良いモデル構築をしていきたいと思っています。
また、今回紹介した以外にも水面化でいくつか研究開発を進めているテーマがありますので、これまた別の機会に紹介します。
「別の機会に」を多用しすぎてしまいました。
別の機会でまた会いましょう。
(メディア研究開発センター・山野陽祐)