
沖縄でモダンデータ基盤を構築するインターンに参加した

9/4~15で行われた ちゅらデータ のサマーインターンシップに参加しました。この記事ではインターンシップの内容について振り返りを書こうと思います。
データサイエンスコースとデータエンジニアコースがあり、私はデータエンジニアコースに参加していました。
先週まで2週間、ちゅらデータのサマーインターンでした
— 菱沼 雄太@ちゅらデータCTO(しばらく執筆モード) (@foursue) September 18, 2023
データエンジニアコースサマリ
・オンラインろあちゃん講義が2日間(データエンジニア概要、AWS入門)
・Tabeau AmbassadorによるTableau講義
・Airbyteやdbt Cloud使ってデータパイプラインづくり
・オフラインは沖縄でデータ基盤づくり
(続く)
自分のインターンの内容を他人に共有する必要性が生じたことと、データ基盤系のインターンレポートがいくつか投稿されたこともあって、せっかくなので筆を執りました。
TL;DR
S3・RDS・Aurora上のデータをAirbyte・Snowflake・dbtを用いたELTパイプラインを構築し、最終的にTableauを用いて可視化を行うとこまでが課題でした。
最初はポチポチすればできるかと思っていたのですが、多くの箇所でつまづき、チーム内で相談を繰り返して発表直前まで作業をしていました。
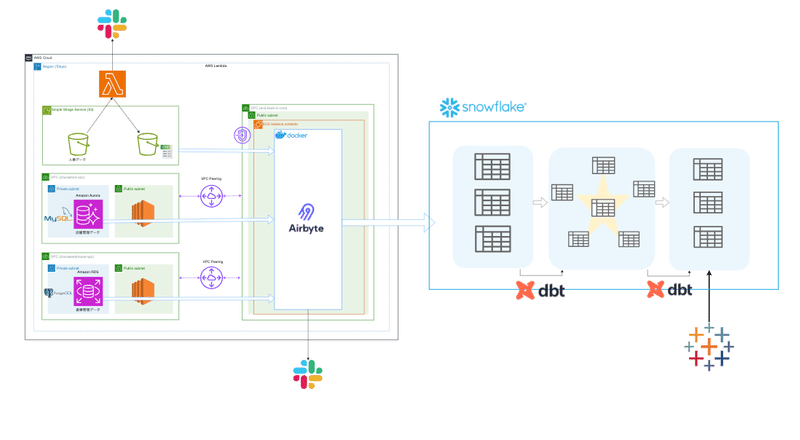
最終的な成果物として、5人1組のチームで以下のようなデータ基盤を構築しました。
もう一つのチームが発表直前に
「できました!セルフマージします!」といっていたのが印象的です。
Airbyte
AirbyteはOSSのデータインジェストを実現するツールです。クラウド版もあります。2020年創業で、多くのデータソースと転送先に対応しています。ELTのELを担うツールで、dbtと組み合わせるとELTをすべて行うことも一応可能です。
類似したツールにFivetranなどがあります。
Snowflake
Snowflakeは近年注目を集めているデータクラウドサービスでデータレイク、データウェアハウス、データマートなどを構築可能。各種パブリッククラウド(AWS,GCP,Azure)上で動作し、無制限の容量や自動スケーリングに加えて、データ共有の容易さや高いパフォーマンスが特徴です。また運用コストが低く、ニアゼロメンテナンスとよばれています。
dbt
ELTのTの部分をサポートするツール。複数のSQLの依存関係を考慮しながらデータの更新ができることや、gitによるバージョン管理、テスト機能、ドキュメントの生成などSQLによるデータエンジニアリングの品質を高めてくれます。
Tableau
ノーコードで非常に高い可視化表現力をもつBI Tool。前処理や関数といった機能の充実度や、多様なグラフのサポートによって優れたアウトプットを提供できる。データソースとしてローカルのファイルからsnowflakeまで対応している。
はじめに
ちゅらデータのインターンシップに関する情報が公開されたのは5月上旬だったと記憶しています。
私は以前からちゅらデータという会社を、データエンジニアリングやNLPを始めとするデータサイエンスの領域において非常に高いレベルをもった会社と聞いたことがあり、インターンシップの内容を鑑みて自身が成長できる機会だとfdjdp
2週間で20万(+交通費)もらって沖縄(オフラインは後半の一週間)で遊べるという誘惑に気づいたら応募していました。
実際インターン生の多くは沖縄を目的の一つとしていましたが、ちゅらデータは今年の自然言語処理学会やYANSのスポンサーだったようで、それで会社を知った人もいたようです。
学会のスポンサーをすると大学院生に知ってもらえる。なるほどと思いました。
インターン 前半
前半はオンラインでの研修です。
CTOによるAWS講義・演習
Tableau AmbassadorによるTableau講義・演習
SQL、dbt、snowflakeの講義・演習
といった感じです。ほとんど毎日昼にLTがあり、実際の業務の話や数学の話を色々聞くことができました。
インターン 後半
後半 1 週間は沖縄でわいわいできます。
(一部参加者と社員の方は0日目の夜から国際通りで親睦を深めていました)
オフラインでの課題は以下のような感じです。
課題
AWS上に設置された開発用の DB とデータをSnowflakeにロードし、ディメンショナルモデリングを用いて様々な分析要求に対応できるようなスタースキーマを構築しなさい.
対象となるデータは以下になります
- 人事データ ← S3
- 営業データ ← S3
- 店舗管理データ ← Aurora (MySQL)
- 倉庫管理データ ← RDS (PostgreSQL)
また、分析要求とは例えば以下のようなものです。
- 売上を商品ごとに確認したい
- 売上を曜日ごとに確認したい
- 売上をスーパーバイザーごとに確認したい
- 在庫数を週ごとに確認したい(例:最大値、最小値、平均値、中央値)
- 在庫回転率(出庫/(期間内在庫+入庫-出庫))を週ごとに確認したい
- 上記を組み合わせたような、
xxxを店舗ごと、曜日ごとに確認したい、など
課題に関して補足をすると、工夫が必要な点として
S3上のファイルはcsv, xlsx, json, xmlファイルなど拡張子は異なる
AuroraとRDSは異なるVPC上にあり、Airbyteもまた異なるVPC上に構築する必要がある.
データは2週間分存在し、たとえば在庫の情報はレコードがupdateされるため、その差分も含めてデータウェアハウスに取り込む必要がある(SCD,Slowly Changing Dimension Type 2)
以上を考慮した上で私達のチームは以下のようなアーキテクチャを構築しました。
データのインジェストにはOSSのAirbyteを採用していましたが、データソースをS3とした場合には対応するファイル形式がcsv, jsonlであったために非対応のファイルについてはlambdaで変換をしています。
RDS、AuroraについてはAirbyte(EC2)をたてているVPCとピアリングを行って、踏み台を経由して連携を行っています。
Snowflake上にデータをロードした後、dbtを用いてスタースキーマ、データマートマートを構築しています。
しかし実際はマートの構築は十分な時間が取れず、可視化の際はTableau上でたくさんテーブルを結合したりしていました。
困った点
差分連携を行うために、AuroraのMySQLのバイナリログを有効にする必要がありました。特にバイナリログを有効にしてもライターインスタンスにしか反映されないことを知らず、data sourceにリーダーエンドポイントを指定したままにしており、時間を費やしました。
VPCピアリングを行うためにはIPアドレスの範囲が重複していない必要がありますが、RDSのVPCが10.0.0.0/16となっており(確か)、VPCの作成時に特に変更しない場合はアドレスが重複する罠が仕掛けられていました。
ディメンショナルモデリングや、スタースキーマとデータマートといった理解がチーム内で深まっておらず、何をfactとして何をdimensionとするかといった議論を長い時間行いました。
よくデータをみると途中で在庫がマイナスになっている罠が仕掛けられていました。しっかりとデータを確認する必要性を認識しました。
データソースには2週間分のデータが追加されていきますが、今回は2週間分のデータをデータの時間に沿って格納するわけにはいかないので、社員の方が1日分の更新をスクリプトで行う形式でした。このとき、複数日のデータ更新を短期間で行ったために、その間にデータのインジェスチョンが行われないという現象が生じました。この結果更新した複数日の中間データが欠落してデータの整合性が取れていませんでした。
再度テーブルのtruncateと更新を行っていただくよう頼みましたが、協力をえられず時間の都合上それはかなわず、既存のデータからの復旧も間に合いませんでした。当初、リアルタイム性を担保するためにRDS, Aurora ↔ Airbyte のインジェスチョンの周期を非常に短く設定していました。これらはCDC(Change Data Capture)を設定していたため、テーブルに変更がなかった場合は何も行われないという想定でした。
ただ、実際はテーブルに変更がなくてもairbyteがsnowflake上でクエリを叩くいていました。結果としてsnowflakeが常に稼働しており、想定以上にコストがかかってしまいました。
おわりに
学生のうちにAWSやGCPを利用することはあっても、データ基盤に関わる機会は非常に稀だと思います。今回のようなELTパイプライン、データマートからBIツールによる可視化といった一連のフローを構築する経験ができたのは非常にためになりました。ちゅらデータの方たちのレベルも非常に高く、いろいろ勉強させていただきました。
データサイエンスコースの内容もLLM関連で非常に楽しそうでした。
チームのメンバーや社員の方々など多くの方にサポートいただいたおかげで2週間無事に終えることができました。本当にありがとうございました。
初日から遅刻したやつがいるのか、、!?
・オフライン0日目の夜に一部インターン参加者とディープな沖縄の居酒屋でわいわい(=>結果初日遅刻者発生(ワロタ
— 菱沼 雄太@ちゅらデータCTO(しばらく執筆モード) (@foursue) September 18, 2023
・進捗が良かったのでビーチでびちゃびちゃに
・天の川を見に行くイベント発生
・CTOのオープンカーでドライブしつつ、ゆるゆる1on1(1名できなかったので後でオンラインでやりたい)
宣伝
普段はEngineeBaseというSES営業向けのSaaSの開発をしています。
気になる人は会社か私のTwitter(新: X)に気軽に連絡していただけると。
この記事が気に入ったらサポートをしてみませんか?