
量子コンピューターで機械学習を学ぼう!「QC4U2」に参加してみた-第4回目-

こんにちは、デザイナーのヤマモモです!🙇♂️
今日も引き続き、大関さんが量子コンピューターを無料で教えてくれるというオンライン講座の第4回目のレポートを書きます😄
前に書いた部分は省略して省エネで書いて行きますので、ご了承ください🙏
↑前回の記事
会員登録してない人でもこの動画視聴できますので、是非御覧ください!
アヤメのデータ識別
今回は花のアヤメの識別問題に機械学習で挑戦します🌷

実はアヤメって色々があり、wikipediaで見ると「アヤメ」「カキツバタ」「ハナショウブ」という3種類のアヤメが確認できます。
で、今回は「萼片の長さ」「萼片の幅」「花弁の長さ」「花弁の幅」と4つの数値で分類するそうで…
それの関数を考えてね!というのが今回の目標💡
萼片と花弁とは?
アヤメのデータをダウンロードする
from sklearn import datasets
iris = datasets.load_iris()いつも通りPennylaneを入れます。
そのあとsklearnという機械学習などのライブラリのセットを入れて…
その中のiris(あやめ)のデータセットを読み込みます。
てかアイリスってアヤメの事なんだ!??知らんかった💦
コメントでも書かれている方いましたが、アイリスオー●マって…?と思った方は少なくないはずw

Irisのデータセットの中身を見ると大量の数字が並んでいます。
これは左から「萼片の長さ」「萼片の幅」「花弁の長さ」「花弁の幅」を表しているそうです。
アヤメの花のサイズを色んな角度から測ったもので、その長さのデータが150個並んでいるデータだとか🫨

その150個のデータの3種類の内訳がこんな感じに入っています。
1〜50が0番目の種類のアヤメ
51~100までが1番目の種類のアヤメ
101〜150までが2番目の種類のアヤメ

↑このように「xx番目のデータ」を見ることも出来ます!
(左の)1番目のデータは「萼片の長さ4.9&幅3.0」「花弁の長さ1.4&幅0.2」の0番目のアヤメのデータですと言っています。
大関さん「0番目のアヤメは、花弁の幅0.2と如実に小さいことがわかる。」
ほうほう。。こう数字が並んでいると全部一緒に見えてくるのが文系脳です🤣
こんな感じでデータを眺めると各アヤメの特徴がありますね?と。
少ない数なら1個1個調べて、比べるというのは小学生でもできるけど、100個とか沢山あったらそれらを見比べるって大変ですよね?😅
なので、今回はそれをコンピュータでやりましょう!というお話💻
前回同様、このデータセットをPytorchに入れて学習させるらしいです。
アヤメのデータを学習させる

この後、トレーニングデータとテストデータに分けます(省略)
ニューラルネットワークの部分

ReLU(レル)関数は2回目の講義で大関さんが話してましたね!
0になりそうになるとポキっと折れるみたいな関数で、勾配消失問題を解消してくれるとかなんとか。
誤差をどうにかする
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001)今までの「MSE=平均二乗誤差」ではなく、今回のような分類を識別したい時はCrossEntropyLossを使うといいらしいです。(MSEでもできるらしいけど)
SGDは2回目の講義で学んだ確率勾配降下法ですね。
空のリストを作る
train_loss_value=[]
train_acc_value=[]
test_loss_value=[]
test_acc_value=[]いつも通り、学習が上手くいってるかloss_valueをトレーニングデータとテストデータで作ります。
識別の問題は正解してるかが、はっきりしてるので点数を出すことができるそうなので、accという空リストも作ります️📝
学習させる

やってる事は2回目、3回目に似てます。
回帰(関数にマッチさせる)に比べて、今回の識別はちょっと一部違うんですが、なんとなく見慣れてきた感じがします!
さて、これでニューラルネットワーク君への学習が終了しました👏
結果発表

回帰の時に比べて、減り方が緩やかですが減っているのがわかります。
今回accというのが追加されてましたよね?
それで正解率も見れるそうなので、見てみましょう!

おいおい、最後失速してるじゃねーかw
最後頑張りきれなかった子ですね😭
可哀想な事に、親に似てアホの子です(´;ω;`)ぶわっ
正解と解答

tensor()の中の数字が0,1,2番目のアヤメかという事です。
一致してれば正解という事ですね。
うーーん🤔うちの子、三択なのに0と2しか書いてないのなんでなん?アホなの?🤪

大関さんも何回もやっていたんですが、この結果ってやる度に変わるそうなんです💧
あとはニューラルネットワークの学習内容を変えてみたりするといいそうです。
def forward(self, x):
h = self.fc1(x)
h = self.relu(h)
y = self.fc2(h)
return y↑ここの層を増やしてみたり
Tall = 500↑学習回数を増やしてみたり
net = NN(2)↑ 計算結果を2つ以上に増やす事もOK!
ただ、どれも増やすと学習時間かかるそうですよ💧
一旦ここで昼休みをはさみます🍽
手書き画像の識別
昼休み明け、アヤメの識別の量子コンピュータ版の講義がありました。
これは第三回と今回の内容で被ってたので、記事にするのは省きます🙇♀️
で、次に第二回の解説で書かれていた「手書き画像の識別」を量子コンピュータでやるそうです!(やろうと思ったけど出来なかったんで助かりますw)
import torchvision画像識別用のライブラリを入れました。
MNISTのデータセットをダウンロードするとコラボラトリー上で色々とダウンロードが始まります。
手書き文字を見てみる
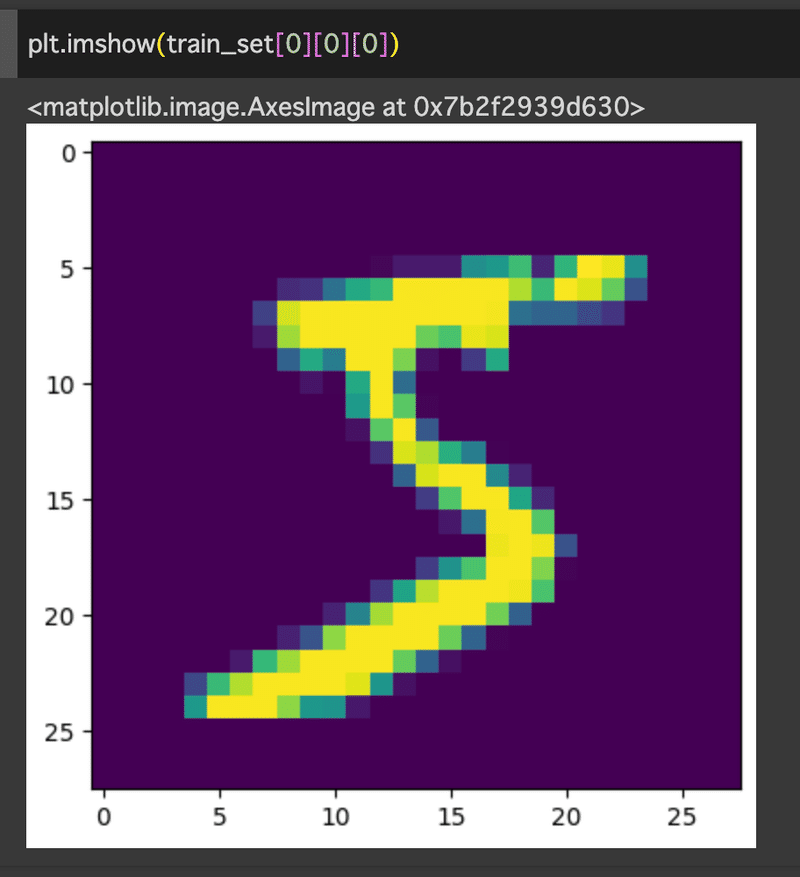
そのtrain_setで0番目のデータを見せてってやるとこんな画像が出てきます。
拡大されすぎてよくわかんないw「S」かな?🤔
皆さんは何に見えます?w

答えは何?と聞くと「5」だと出てきました🫠


これはまだわかる!
ニューラルネットワーク
で、これらをニューラルネットワークに入れます。
画像だと今までとちょっと違う部分も出てきました。

なんで最後10個にするのか、私もわからないんですよね…なんでだろう🤔💦
学習の部分などはアヤメと同じです!なので省きます。
結果発表
さっきの結果がひどかったけど、今回は大丈夫なのか不安や…🥲

おお!さっきよりいい感じに勉強できてるじゃん!
これは結果も期待出来そうだ!😆
正解と解答

これが正解と答案回答なんですが、さっきより量が多い><
でも結構合ってませんか?NNやるやんけ!!🥳

感想
今回で4回目になり、ちょっとコードややることは見慣れてきた感じがしました!✨
あ、でも0から書くのは無理だけどねw
ちょっと成長したなーと思った事があって。
大関さんがYoutubeのコメントに1行ずつコード書いてくれてるんです。
でも1つ1つコピペしんどいなーと思って(コラ)
こちらの解説ページからコードをコピペさせてもらってたんです🤫
で、画像解析の方の学習の段階でエラーが出たんですよ😱ちゃんとコピペしてるのになんで??🤨
エラー前のコードも見直してたら解説ページのコードでミスを見つけられたんですわ!!

これ!ピンク線の部分が「 x 」になってるんです。
ここの「 x 」を「 y 」にしたらエラーなく学習してくれました😇
こういうのがわかるようになったって、ちょっと成長を感じるw
さて、次回が講義編最終回なのかな?
最後まで頑張ります! ノシ
この記事が気に入ったらサポートをしてみませんか?