【ローカルLLM】SuperHOT 8Kで6000トークン超のコンテキストを試す

数日前、RedditのローカルLLMスレに以下の投稿が上がっていた。Llamaベースの大規模言語モデルが6000トークンを超えるコンテキスト長に対応できるようになり、早速text-generation-webuiでサポートされたとのこと。
Llamaは本来2048トークンが限度だったので、画期的な拡張になる。新たなトークン上限はモデルサイズとGPUメモリに依存する。モデルが小さいほど、そしてGPUメモリが大きいほど、処理できるコンテキスト長が長くなる。
webUIの設定上のMAXは8192トークンであり、十分なGPUメモリさえあれば8000超までイケるらしい。text-generation-webuiを手がけるoobabooga氏によると、24GB VRAMのGPU環境において、Llama13Bで6079トークン、Llama30Bで3100トークンまでは確認済み。
SuperHOT
この大幅なコンテキスト拡張は、KaioKenなる人物のプロジェクト「SuperHOT」によって実現したとのこと。素人にはよくわからないが、技術的な詳細はKaioKen氏のブログに説明がある。
「SuperHOT」につながる試みはNSFWなロールプレイング用途を念頭においていて、出力を改善するための試行錯誤の中で今回の発見に至ったという経緯が面白い。
なお、Metaの研究者もこの手法を研究していたらしく、「SuperHOT」が界隈で話題になった後、慌てて論文が公開されるという顛末があった。MetaがKaioKen氏の取り組みをどのくらい参考にしていたのかは謎だが、論文では申し訳程度に「SuperHOT」に言及されている。
Google Colabで試す
SuperHOTによるコンテキスト拡張はLlama系のモデルなら基本的に適用できるが、SuperHOT向けに調整したモデルのほうがより適切に機能するらしい。
例によってTheBloke氏が「SuperHOT」対応の量子化モデルを立て続けにアップしてくれているので、今回は「WizardLM-13B-V1-0-Uncensored-SuperHOT-8K-GPTQ」を使わせてもらった。
#Text Generation WebUIのインストール
!git clone https://github.com/oobabooga/text-generation-webui
%cd text-generation-webui
!pip install -r requirements.txt
#ExLlamaのインストール
!pip install safetensors sentencepiece ninja
!mkdir /content/text-generation-webui/repositories
%cd repositories
!git clone https://github.com/turboderp/exllama
#モデルのダウンロード
%cd /content/text-generation-webui
!python download-model.py TheBloke/WizardLM-13B-V1-0-Uncensored-SuperHOT-8K-GPTQ
#WebUIの起動
!python3 server.py --model TheBloke_WizardLM-13B-V1-0-Uncensored-SuperHOT-8K-GPTQ --chat --share --loader exllama --max_seq_len 6144 --compress_pos_emb 3フリーのGoogle Colab(15GB VRAM)だと6000トークンは難しいのかなと思いつつ、max_seq_len 6144に設定して試してみた。
設定方法の詳細については、冒頭のリンク先を参照。なお、ローダーはExllama(またはその派生のExllama_HF)を使う必要がある。
感想
一応、Colabで6000トークン超のコンテキストウィンドウまで確認できた。
Output generated in 9.77 seconds (10.03 tokens/s, 98 tokens, context 6036, seed 1587725082)
実際にコンテクストを覚えているか調べるため、5000トークン程度の童話(幸福の王子)を読ませた。別の会話を挟んだあとで、物語冒頭の細かい描写について確認してみる。
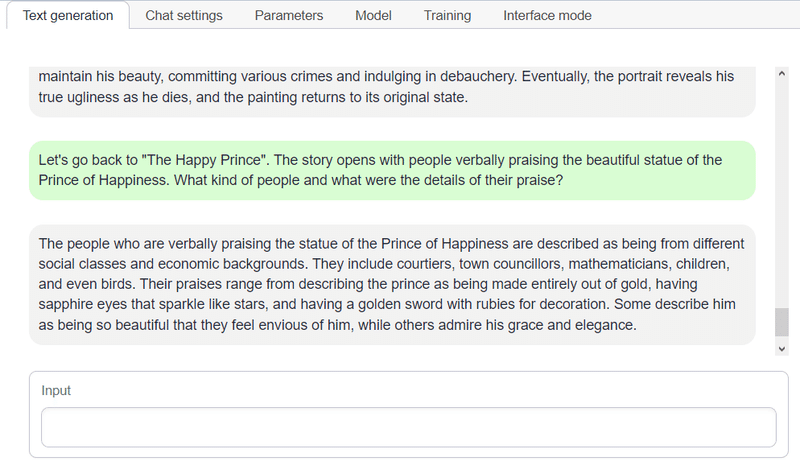
回答を見ると、幻覚が混じるケースはあるものの、おおむね記憶ができている様子。30Bクラスのモデルなら、もっと回答の質が上がるのかも。