
ComfyUI AnimateDiff + LCM-LoRAによる高速な動画生成を試す

StableDiffusionを高速化するLCM-LoRAを応用したAnimateDiffワークフローが話題になっていたので、さっそく試してみました。
LCM-Loraを使うと8以下のStep数で生成できるため、一般的なワークフローに比べて生成時間を大幅に短縮できるようです。
ワークフロー
ComfyUI AnimateDiffの基本的な使い方から知りたい方は、こちらをご参照ください。
今回試したワークフローは以下になります。
【GoogleColab Pro/Pro+で試す場合】このワークフローを実行するためのColabはこちらです(Googleの規制によりフリーのColabでは使えません)。
【ローカル環境で試す場合】特別なカスタムノードは不要です。HuggingFaceから「LCM-LoRA(.safetensors)」をダウンロードし、ComfyUI/models/loras/に置きます。
アウトプット
512x512サイズの24フレーム(3秒)の動画生成を行い、通常のAnimateDiffワークフローと比較しました。
LCM-LoRAではstep数は2-8が推奨されています。AnimateDiffで使用する場合はstep数は8に設定するのが無難なようです。

Colabの標準GPU(T4)環境で、通常のAnimateDiffは150秒程度、LCM-LoRA適用で70秒程度でした。生成時間は半分以下です。
一方、動画の質自体はやはり低下してしまうようです。特にアニメ絵はあまり学習されていない感じがします。
モデルによってはCFGを2-3に設定することで改善しました。
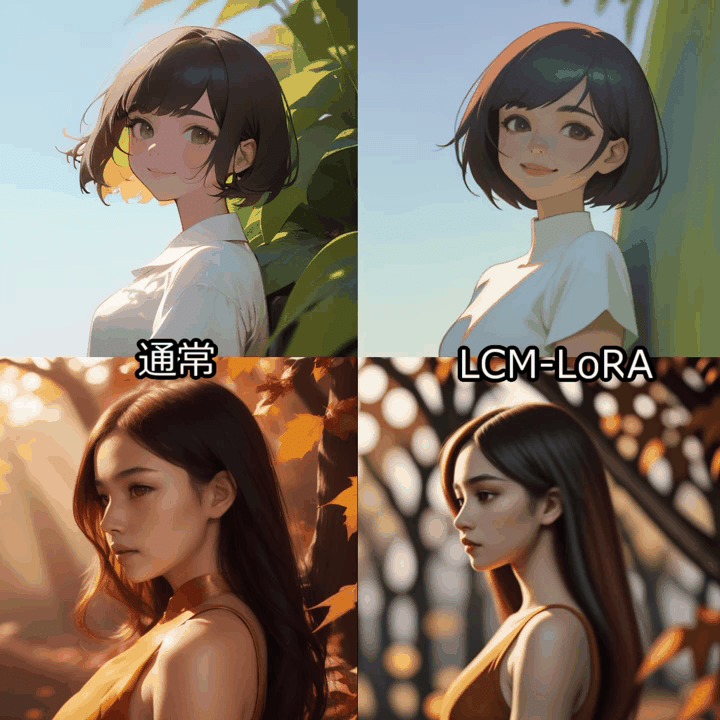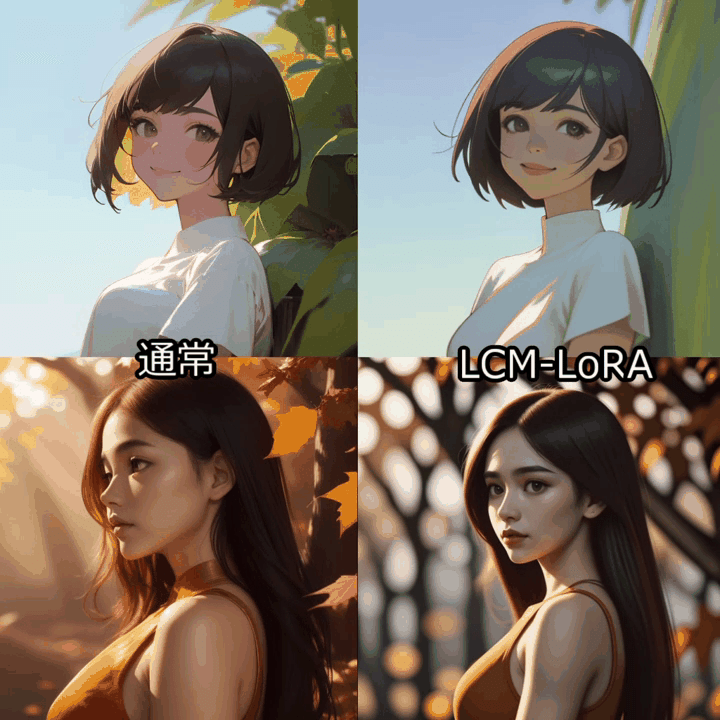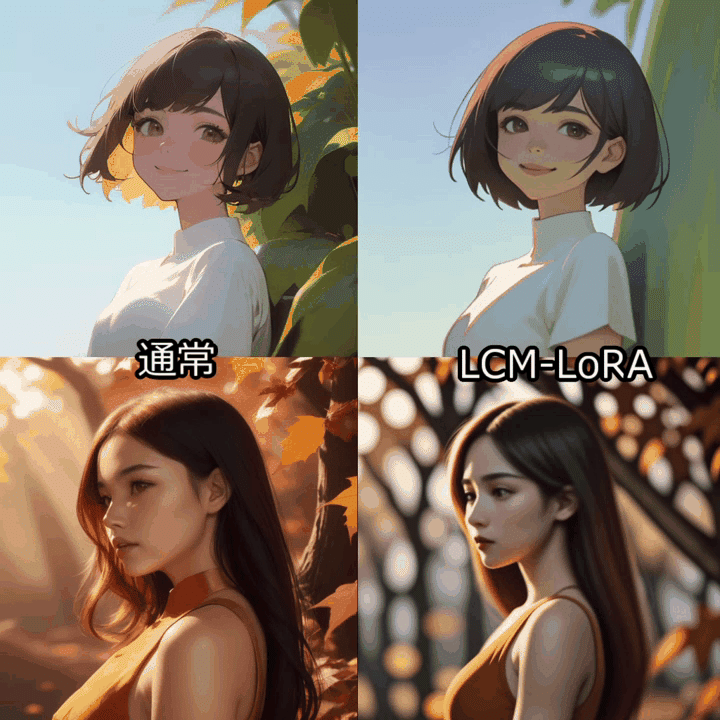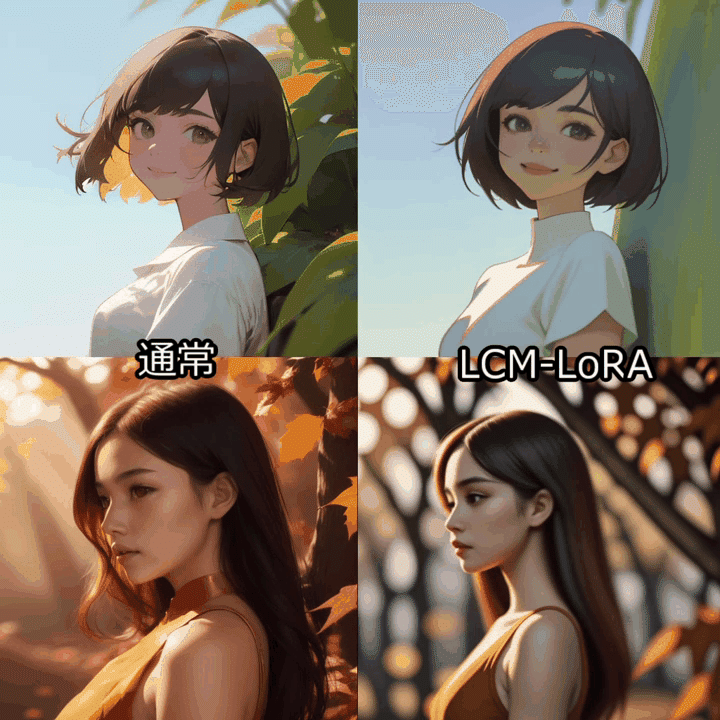
生成は格段に速いので、ControlNetと併用して長めの動画をVid2Vid変換する用途には向いてそうな印象です。
関連記事
Animate関連の記事は以下のnoteにまとめています。