
「Amazon価格ツイート」アプリ作成⑥ DB環境構築

どうも、タケオです。
今回は実行履歴を管理するためのDB設計を行なっていきたいと思います。
なぜDBを利用するのか
取得する情報が固定のものならPGに直に書いてしまうこともできますが、汎用性もなくあまりいい手法ではありません。
またファイルで管理することも可能ですが、同じ情報を何回もツイートしてしまわないように実行履歴を参照しながら処理を行うにはファイル管理では処理が煩雑になってしまいます。
そのため取得する情報の定義や処理結果などを簡単に保存・参照できるDBでの管理がベターだと言わざるを得ません。
何を管理するのか
必要になる項目を挙げていきます。
アカウントマスタ(ツイートするTwitterアカウントのAPIキーなど)
検索リスト(検索条件などを設定)
ツイート履歴(どの検索条件が該当したのか、ツイート内容など)
実行履歴(検索結果など。これはログファイルとして外部保存する予定)
思ったよりも少ないですね。実質3テーブルあれば稼働できそうです。
DBは何を使用?
元々業務系の開発が多かったためMicrosoftのSQLServerの利用が多かったのですが、Pythonを使うことですしPostgreSQLかmySQLあたりにしようかと思います。また当初の予定であったRaspberry Piでサーバーを立てる際にはmySQLの導入が楽そうなので今回はmySQLを使用することにします。
環境構築
丁寧な解説ページまで用意してくれているのでサクッとインストールしてみたいと思います。(仮サーバーはWindows環境です。)
開発者オプションでインストールすると MySQL Workbench も同時にインストールされます。コマンドラインではなくGUIを使ってDBを作成していきま
す。
管理機能がエラーになる場合
処理に直接関係はないのですが「Could not acquire management access for administration」エラーが出て管理機能が使えないエラーが出ていました。
PATHが通っていないというエラーなのですが、確認しても正しく設定されています。また「chcp」コマンドも実行可能でした。
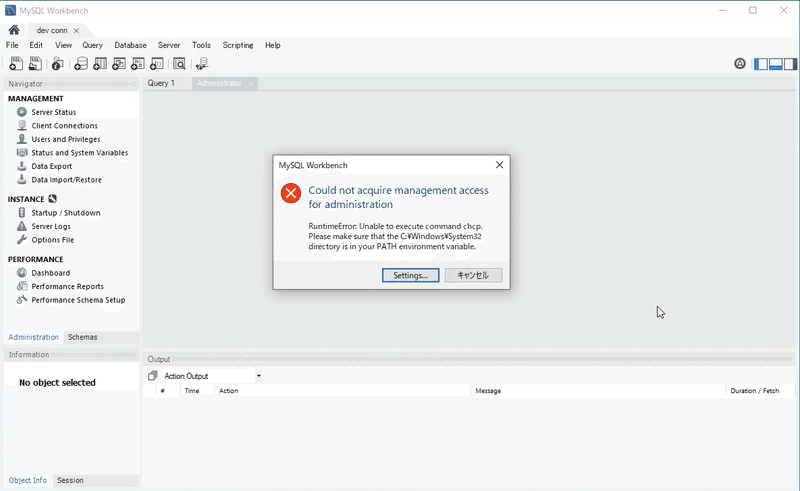
色々ネットで検索しているとシステムロケールの変更に「ワールドワイド言語サポートでUnicode UTF-8を使用」にチェックを入れてみるというのがありました。

これによってようやく管理機能が利用できるようになりました。ちょっと脇道に逸れてしまいましたが、気持ちよく開発したいので修正しておきました。
テーブルの作成
では、早速テーブルを作成してみます。SchemasタブでDB(Schema)を作成し Create Table します。
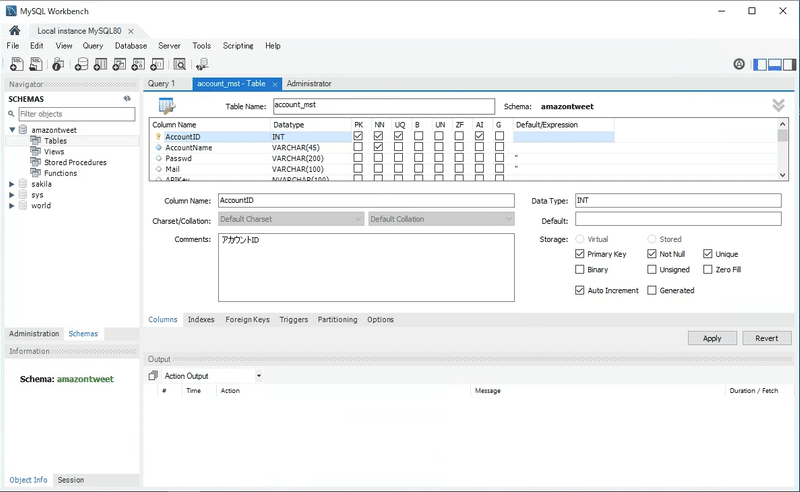
(注意)
'lower_case_table_names=1'が設定されているためテーブル名などは全て小文字で登録します。カラム名は混ざっても問題ありません。
初期データ登録
作成したテーブルに初期データを入力しておきます。
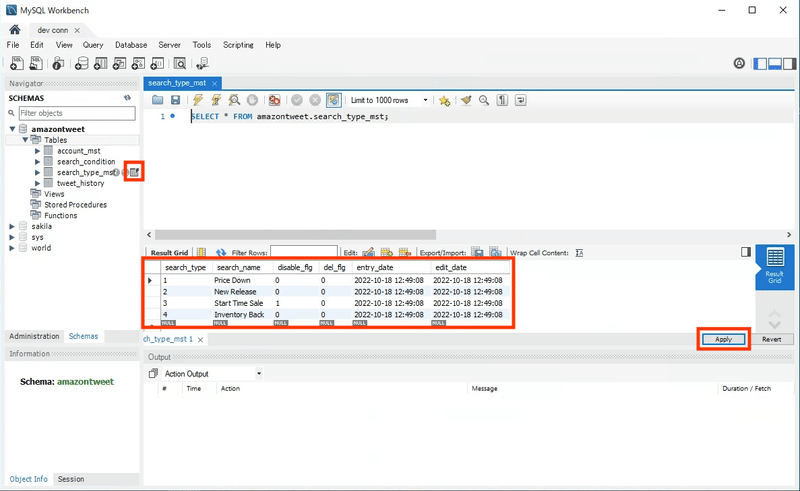
編集したいテーブルの編集マークを選択するとデータがグリッド表示されます。登録したい内容を入力し右下の「Apply」を選択するとINSERT文が作成されテーブルに登録が実行されます。
データ取得
作成したテーブルから正しくSELECT出来るか試してみます。
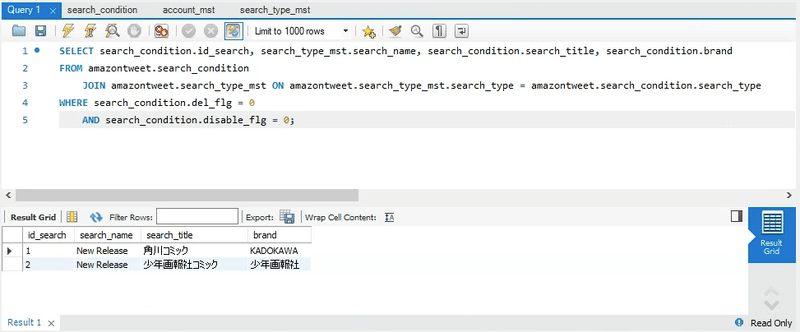
と一先ず取得できることが確認できました。
Pythonから接続
Pythonからも同じデータを取得してみます。
import mysql.connector
DB_USER = 'root'
DB_PWD = 'パスワード'
DB_HOST = 'localhost'
DB_NAME = 'データベース名'
con = None
try:
con = mysql.connector.connect(
user = DB_USER, # ユーザー名
password = DB_PWD, # パスワード
host = DB_HOST, # ホスト名(IPアドレス)
database = DB_NAME # データベース名
)
if con.is_connected:
cur = con.cursor()
sql = ('''
SELECT search_condition.id_search, search_type_mst.search_name, search_condition.search_title, search_condition.brand
FROM search_condition
JOIN search_type_mst ON search_type_mst.search_type = search_condition.search_type
WHERE search_condition.del_flg = 0
AND search_condition.disable_flg = 0
''')
cur.execute(sql)
for (id_search, search_name, search_title, brand) in cur:
print(f"({id_search}) {search_name} {search_title}({brand})")
cur.close()
except Exception as e:
print(f"Error Occurred: {e}")
finally:
if con is not None and con.is_connected():
con.close()この時「import mysql.connector」でエラーが出るときは次のコマンドを実行してパッケージをインストールしておきます。
pip install mysql-connector-pythonコマンドプロンプトから実行すると。

先程のWorkbench上で取得したものと同じものが表示されました。
というわけで
DB環境を用意しPythonからも接続できることが確認できました。
あとはDBに登録した情報を元にAmazonへデータを取りに行き、結果をツイートするだけです(略し過ぎ)。
今後は処理が増えてくるのでどこまでソースを公開できるか分かりませんが、出来るだけ何をやっているかは分かるように出来ればと思います。
この記事が気に入ったらサポートをしてみませんか?