
猿の種類を見分ける画像判別機を転移学習、google coloboratory、kerasで作ろう!(ディープラーニング入門)

作るもの
猿の画像をアップロードするとその画像に写っているのがゴリラなのかチンパンジーなのか、それともオランウータンなのか? を判定するモデルを作ります。
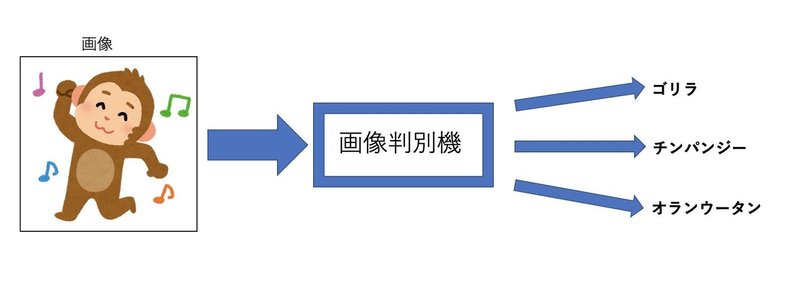
猿が写っていない写真を入れても判定してくれます。
例えば知り合いの顔写真を入れて
「うわ、あいつゴリラ顔じゃんっ!わろたww」
みたいな感じで楽しむことも出来ます。
(ちなみに私はゴリラ顔でした...)

目次
・データの集め方
・前処理、下準備
・モデルの作成、学習
・予測の方法
・発展
まず使用するデータの準備
データを集める
方法1 (沢山集められる!方法2と比べると少し面倒かも)
$ pip install icrawlerとターミナルまたはコマンドプロンプトでまず打って実行(Enterを押す)。
$はすでにあるので打たなくて良いです。
from icrawler.builtin import GoogleImageCrawler
import sys
import os
argv = sys.argv
if not os.path.isdir(argv[1]):
os.makedirs(argv[1])
crawler = GoogleImageCrawler(storage = {"root_dir" : argv[1]})
crawler.crawl(keyword = argv[2], max_num = 100)が書かれたファイルをimage.pyなどと名前をつけて保存してください。
(エディターを紹介してるサイト)
max_numで集める枚数を指定しています。
crawler = GoogleImageCrawler(storage = {"root_dir" : argv[1]})
crawler.crawl(keyword = argv[2], max_num = 100)
で集めた画像を保存する場所の指定、集める画像のキーワードの指定の仕方を決めています。
今回は簡単のため、集める画像は100枚だけにしてあります。max_numの値をいじって欲しい枚数にして下さい。
ターミナルまたはコマンドプロンプト場でcdコマンドを使って、image.pyが保存された階層に移動し、(linuxコマンドを説明してるサイト)
$ python image.py gorilla gorilla$ python image.py orangutan orangutan$ python image.py chimpanzee chimpanzeeと打ち実行してください。
$ python image.py 集めた画像を入れるフォルダの名前 集めたい画像のキーワードとなっています。フォルダは自動で生成され、指定した名前がそのフォルダの名前となります。
集めた画像を入れるフォルダの名前は英語にしておいた方が無難です。
(エラーが出ることもありそうだからです。(出ないかも...))
方法2(お手軽だが、集められる枚数が少ない)
「google-image-download」というものを用いるのがお手軽です。google 画像検索から条件を指定して、検索キーワードに関する100枚の画像を自動で集めることが出来ます。(指定外の画像は排除されるので実際は100枚よりも数は少ない。)(101枚以上は集められない)
まず、以下でgoogle_images_downloadをインストールします。
Macの方はterminalで、windowsの方はコマンドプロンプトで$より後ろの部分を打って実行してください。
$ pip install google_images_download次に、三種類の猿の写真を集めていきます。
--keywordsの後ろに検索キーワードを
-f の後に集めたい画像の形式を記述して、条件を指定します。
(-fはなくても良いが、つけておくと開けない画像などを排除することが出来ます。)
より細かく条件を指定することも可能です。ご自身で調べてみて下さい。
$ googleimagesdownload --keywords "gorilla" -f "jpg"$ googleimagesdownload --keywords "orangutan" -f "jpg"$ googleimagesdownload --keywords "chimpanzee" -f "jpg"以上を実行するとPCのダウンロードのところに新しく、
「gorilla」、「orangutan」、「chimpanzee」という名前のフォルダが作られていると思います。
英語で検索キーワードを設定しなくてはいけない訳ではないですが、フォルダ名は英語にしておいた方が無難です。
(エラーが出ることもありそうだからです。(出ないかも...))
以上はこちらのサイトを参考にさせて頂きました。
前処理
集めた画像のうち質の悪いものを頑張って取り除きます。
形式がおかしい画像や、関係ない画像を取り除きます。横を向いていたり、複数で写っていたりするものもできれば除いた方が良いです。複数写るものなどは、一匹のみ切り取るのも一手です。
ここは精度に大きく影響するのでとても大事な作業です!!!
データの分割
データを学習(train)用と、評価(validation)用とに分割します。
大体それぞれ 7:3 ~ 8:2 位の割合になるようにtrainフォルダとvalidationフォルダに分けて入れて下さい。(以下のような位置関係になるように)
(ちょっと面倒ですが、頑張って下さい!!!)
-train -gorilla (ゴリラの中で2~3割)
-orangutan (オランウータンの中で2~3割)
-chimpanzee (チンパンジーの中で2~3割)
-validation -gorilla (ゴリラの中で7~8割)
-orangutan (オランウータンの中で7~8割)
-chimpanzee (チンパンジーの中で7~8割)
(.DS_Storeが勝手にフォルダに含まれてしまっていることが原因で後々エラーが出ることがあります。.DS_Storeはフォルダを普通に見ても表示されないことがあります。ターミナルやコマンドプロンプトでcdをつかってtrainフォルダ、validationフォルダまでそれぞれ移動し、ls -aとすれば表示されるので、含まれていればrm .DS_Storeと打って、消して下さい。)
データを圧縮してから、google driveに上げます。
まずtrainフォルダとvalidationフォルダを圧縮します。Macの方は、フォルダを選択して右クリックすると、"〜を圧縮” という項目があるので、そこをクリックします。そうすると、train.zip、validation.zipをつくれます。
windowsの場合も似たような方法で圧縮できます。参考リンク
その2つの圧縮したフォルダーをgoogle driveにアップロードします。
google driveをプラウザで開いて、2つのファイルをそこにドラッグすれば良いです。
(圧縮してから、google drive にあげてください。後にgoogle coloboratoryを使う時に、圧縮していないと読み込めないです。)
(google アカウントの作成)
goole driveに上げたら、そのフォルダを右クリックして「共有可能なリンクを取得」を押します。
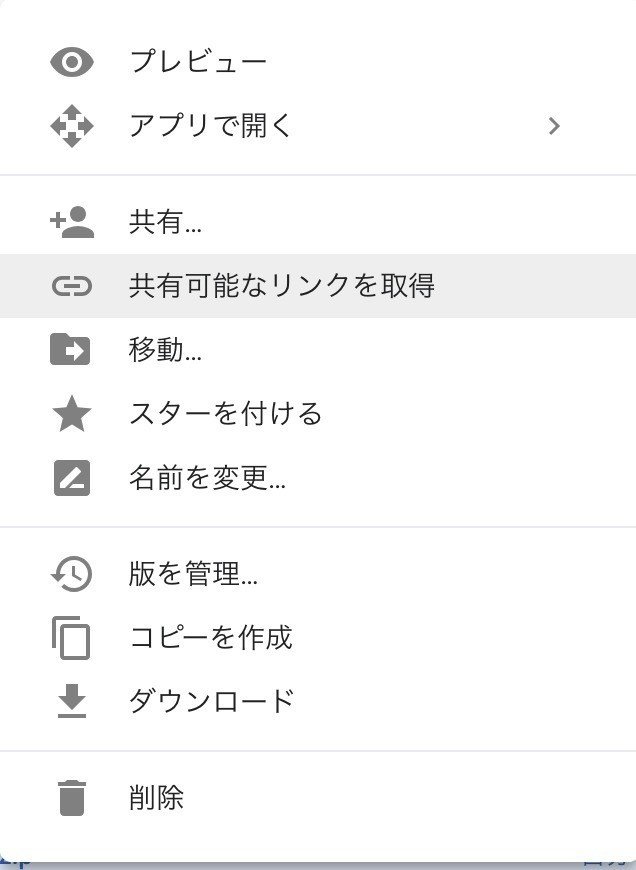
「https://drive.google.com/open?id=~~~~~~~~~~~」のようなリンクを得るのでid=より後ろの部分をコピーしてメモ帳かどこかにペーストしておいてください。
(train.zip、validation.zipのどちらについても行い、trainのidか、validationのidかが区別できるように気をつけて下さい。)
次に、モデルが完成したら判別させてみたい画像を用意し、それらが入ったフォルダを作ってください。ここでは「test」と言う名のフォルダにしています。学習に使っているデータを入れてもあまり意味がないので、未使用の画像を入れましょう。(自分の顔写真とかを入れておいても楽しいですね)
以上で大体の準備は完了です。
モデルの作成
画像判定を行うにはディープラーニングを行うのですが、それには大量の計算が必要であるので、GPUを使います。
google のアカウントを持っていれば無料で、GPUコンピューティングが出来るサービスがあります。
そのサービスの名前は「google coloboratory」です!!GPU搭載のPCを持っていなくても、GPUを使えるは本当にありがたいですね!!
(時間制限がありますが、あまり気になりません。GPUにしてはそんなに速くないですが、十分使えます。)
1. google colaboratoryと調べてトップに出てくるサイトに入り、「python3の新しいノートブック」をクリックする。
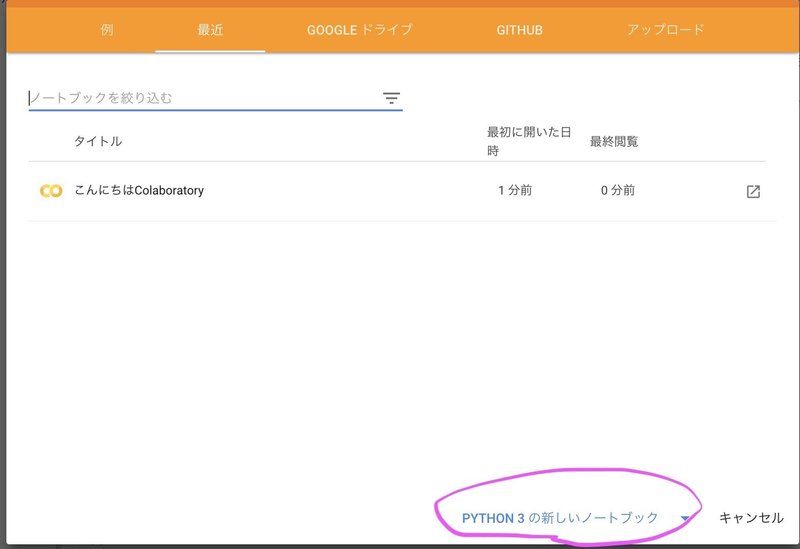
それか、ファイルのpython3の新しいノートブックをクリック
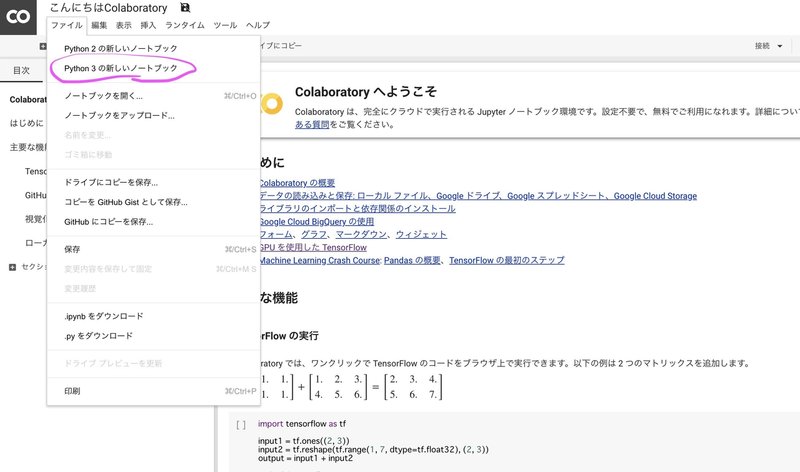
2. 編集の「ノートブックの編集」に入り、「ハードウェア アクセラレータ」をGPUに設定する。

3. 自分のgoogle アカウントを認証します。
google colaboratoryでカーソルが出ているところ(上の写真の青くなっているところ)に以下のコードを打ってください。
(認証するためのおまじないだと思ってもらって結構です。)
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)すると、urlが出てくるので、それをクリックし自分が使いたいgoogle アカウントを選択し、リクエストを許可してください。(zipファイルを上げたgoogleアカウントを選択してください。)
すると文字列が表示されるので、それを全てコピーし元のタブに戻ってurlの下の枠にペーストして下さい。そしてshift+Enterとすると認証完了です。下の画像のようになります。
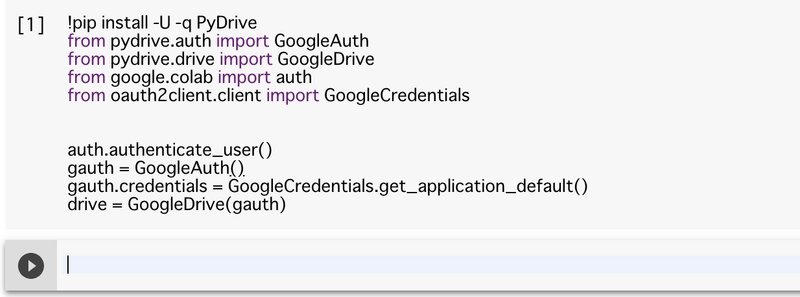
shift + Enterで選択しているセルを実行することができます。
4. 使うデータを取り出して、圧縮されている状態から解凍します。
downloaded = drive.CreateFile({'id':'your_train_id'})
downloaded.GetContentFile('train.zip')your_train_idのところに準備の時にコピーしておいたidをいれ、実行してください。(''は消さないで下さい)
downloaded = drive.CreateFile({'id':'your_validation_id'})
downloaded.GetContentFile('validation.zip')同様にyour_validation_idのところにもidを入れ、セルを実行してください。
これで、google driveからtrain.zip、validation.zipを読み込みました。
次に以下を打ち、実行して解凍します。
!unzip train.zip
!unzip validation.zip以下の画像のように、バァーっとデータを解凍できていたら成功です。
よくあるエラーとして、フォルダをいじっているときに.DS_Storeが勝手に含まれておりエラーが出ることがあります。.DS_Storeはフォルダを普通に見ても表示されないことがあります。ターミナルやコマンドプロンプトでcdをつかってフォルダまで移動し、ls -aとすれば表示されるので、含まれていればrm .DS_Storeと打って、消して下さい。(よくやらかすので2回書いてみました)
モデルの設計
次のセルに行き、以下を実行してください。
NUM_TRAININGのところはtrainデータの数を、NUM_VALIDATIONのところにはvalidationデータの数を入れてください。
ここではそれぞれ、194、50としています。
N_CATEGORIESは今回写真を三種類の猿に分類するので3としています。
もし別の判別機を作られる際は、ここを分類するクラスの数に合わせてください。コードの解説は、最後にまとめて行います。
epochsのところは、エポック数(訓練データを何回学習させるか)を表しており大体の場合多い方が精度が上がります。当然ですが、多ければ多いほど、沢山時間がかかってしまいます。今回は40エポックにしてあります。
from keras.models import Model
from keras.layers import Dense,Input,GlobalMaxPooling2D,Dropout
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD
N_CATEGORIES = 3
IMAGE_SIZE = 224
BATCH_SIZE = 8
NUM_TRAINING = 194
NUM_VALIDATION = 50
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
base_model = VGG16(weights='imagenet', include_top=False,input_tensor=input_tensor)
x = base_model.output
x = GlobalMaxPooling2D()(x)
x = Dense(1024, activation='relu')(x)
x = Dense(2048, activation='relu')(x)
x = Dropout(.25)(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(N_CATEGORIES, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers[:15]:
layer.trainable = False
model.compile(optimizer=SGD(lr=1e-4, momentum=0.9), loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()
json_string=model.to_json()
open("model"+'.json','w').write(json_string)
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
shear_range=0,
zoom_range=0.1,
horizontal_flip=True,
rotation_range=0)
test_datagen = ImageDataGenerator(
rescale=1.0 / 255,
)
train_generator = train_datagen.flow_from_directory(
'train',
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
shuffle=True
)
validation_generator = test_datagen.flow_from_directory(
'validation',
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
shuffle=True
)
hist = model.fit_generator(train_generator,
steps_per_epoch=NUM_TRAINING//BATCH_SIZE,
epochs=40,
verbose=1,
validation_data=validation_generator,
validation_steps=NUM_VALIDATION//BATCH_SIZE,
)
model.save('monkey.hdf5')
すると学習の進捗状況、精度のログが出てきます。全て終わったら、以下で学習した結果を表すmonkey.hdf5、model.jsonを保存します。
monkey.hdf5はgoogle driveに保存され、model.jsonはローカルのダウンロードのところに保存されます。monkey.hdf5はドライブからローカルにダウンロードしておきましょう。
upload_file_2 = drive.CreateFile()
upload_file_2.SetContentFile("monkey.hdf5")
upload_file_2.Upload()from google.colab import files
files.download('model.json')以上で、モデルは作り終わりました。
モデルの定義の解説
先ほどの長々としたコードを説明していきます。はやくモデルを使ってみたいという人はこの章は読み飛ばしてください。
機械学習を支援するフレームワークには、Tensorflow、Keras、Chainer、PyTorchなどが有名ですが、今回はシンプルな記述が特徴であるKerasを用いました。(kerasでの記述の裏ではtensorflowなどの他のフレームワークによる処理が行われているらしいです。)
kerasでモデルを作るには2つのやり方があり、Sequential modelとfunctional API modelとがあります。複雑なモデルを組むのには後者が向いているので後者を使いました。参考サイト1、参考サイト2
今回は学習データの枚数が少ないということもあり、転移学習を用います。
kerasではVGG16というImageNetという有名な画像データセットを使って学習済みのモデルが提供されています。畳み込み13層とフル結合3層からなります。
フル結合層は使わないから、13層を使います。
from keras.models import Model
from keras.layers import Dense,Input,GlobalMaxPooling2D,Dropout
で後々使うクラスをインポートしています。
from keras.applications.vgg16 import VGG16
でkeras.applications.vgg16モジュールに入っているモデルを取ってきます。
参考サイト
from keras.preprocessing.image import ImageDataGenerator
で訓練データとvalidationデータを生成する道具を取ってくる。
from keras.optimizers import SGD
深層学習の勾配法(optimizer)には様々なものがあります。そのうちもっとも基本的なSGD(確率的勾配降下法)をここでは用います。参考サイト
N_CATEGORIES = 何種類に分類するか?を指定
IMAGE_SIZE = 使う画像の大きさ
BATCH_SIZE = 2の冪乗に指定するのがありがちです。大きいと速く学習が進みます。使うデータが少ないなら、バッチサイズも小さく、多いならバッチサイズも大きくします。今回は学習院データが少ないので小さくしました。
NUM_TRAINING = 学習させる画像の枚数
NUM_VALIDATION = 検証に使う画像の枚数
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
入力するデータのサイズを指定しました。(画像サイズx画像サイズxRGB)
base_model = VGG16(weights='imagenet', include_top=False, input_tensor=input_tensor)
wightsで重みの種類を指定します。imagenetとすればImageNetを使って学習した重みとなります。
include_topで元のフル結合層を含むかどうかを決めます。
元の1000分類を使うならTrue、使わないならFalseとします。
input_tensorで入力するデータを指定します。
参考サイト1 参考サイト2
学習済みモデルに新たに独自の層を追加します。まず、学習済みモデルの出力を引き継いでから、pooling層を追加します。ここではGlobalMaxpooling2Dを使いました。さらに、過学習を防ぐためにDropoutを入れました。
x = base_model.output 学習済みモデルの出力をxで受け取る
x = GlobalMaxPooling2D()(x) pooling層を通す
x = Dense(1024, activation='relu')(x) 全結合層を通す
x = Dense(2048, activation='relu')(x)
x = Dropout(.25)(x) dropoutしてる
x = Dense(1024, activation='relu')(x)
predictions = Dense(N_CATEGORIES, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
activationで活性化関数を指定しています。参考サイト
for layer in base_model.layers[:15]:
layer.trainable = False
学習済みモデルのVGG16の重みを上から15番目の層まで固定しました。これで今後の学習により、そこの重みは変化しません。VGG16の最後の畳み込み層達は学習されます。
model.compile(optimizer=SGD(lr=1e-4, momentum=0.9), loss='categorical_crossentropy',metrics=['accuracy'])
lr 学習率
momentum モーメンタム
loss 損失関数
metrics 評価基準 accuracyはどのくらい当たったか?を表します。
他にも色々あります。(参考サイト)
model.summary()
これでモデル構造を見ます。VGG16の層と自分で作った層を確認して下さい。パラメータのところに値が有る層を数えながら、全体像を把握しておくと良いでしょう。
json_string=model.to_json()
open("model"+'.json','w').write(json_string)
これでモデルにmodel.jsonと名をつけ保存しました。
openについて説明してるサイト
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
shear_range=0,
zoom_range=0.1,
horizontal_flip=True,
rotation_range=0)
test_datagen = ImageDataGenerator(
rescale=1.0 / 255,
)
train_generator = train_datagen.flow_from_directory(
'train',
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
shuffle=True
)
validation_generator = test_datagen.flow_from_directory(
'validation',
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
shuffle=True
)
以上でデータを生成するクラスを生成しました。
それぞれの意味は情報量が多いので、このサイトをみてください。
hist = model.fit_generator(train_generator,
steps_per_epoch=NUM_TRAINING//BATCH_SIZE,
epochs=40,
verbose=1,
validation_data=validation_generator,
validation_steps=NUM_VALIDATION//BATCH_SIZE,
)
これでモデルの学習が実際に行われます。学習データにtrain_generatorが、精度の評価にvalidation_generatorを使うように書いてあります。
verboseは0か1か2を指定します。0だとログを出力せず、1だとログを標準出力,2だとエポックごとに1行のログがでます。
model.save('monkey.hdf5')
これでmonkey.hdf5という形でモデルを保存しました。
学習済みモデルの使い方
jupyter notebook を使ってモデルを活用します。jupyter notebookはプラウザを使用して動かすノートブックであり、pythonを簡単に実行できます。また、写真やグラフなども簡単に表せるのも利点です。
jupyter notebookの使い方
このサイトを参考にしてください。
もっと手軽に使いたい人は、try jupyter がおすすめです。これは、インストールなどの必要なく、jupyter notebookを使えます。リンク
リンクを開いたらTry JupyterLabをクリックします。(少し開くのに時間がかかります。)
はじめの方で作ったtestフォルダ、monkey.hdf5、model.json の3つが同じ階層になるようにし、そこで新しくノートブックを開き、以下を実行すると判別結果が出力されます。
from keras.models import Model
from keras.layers import Dense, GlobalMaxPooling2D,Input,Dropout
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD
import matplotlib.pyplot as plt
import os,random
from keras.preprocessing.image import img_to_array, load_img
file_name='monkey'
display_dir='test'
label=['chimpanzee','gorilla','orangutan']
N_CATEGORIES = 3
IMAGE_SIZE = 224
BATCH_SIZE = 8
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
base_model = VGG16(weights='imagenet', include_top=False,input_tensor=input_tensor)
x = base_model.output
x = GlobalMaxPooling2D()(x)
x = Dense(1024, activation='relu')(x)
x = Dense(2048, activation='relu')(x)
x = Dropout(.25)(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(N_CATEGORIES, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.load_weights(file_name+'.hdf5')
model.compile(optimizer=SGD(lr=1e-4,momentum=0.9),
loss='categorical_crossentropy',
metrics=['accuracy'])
files=os.listdir(display_dir)
plt.figure(figsize=(10,10))
for i in range(filenumber):
temp_img=load_img(os.path.join(display_dir,img[i]),target_size=(224,224))
plt.subplot(5,5,i+1)
plt.imshow(temp_img)
temp_img_array=img_to_array(temp_img)
temp_img_array=temp_img_array.astype('float32')/255.0
temp_img_array=temp_img_array.reshape((1,224,224,3))
img_pred=model.predict(temp_img_array)
plt.title(label[np.argmax(img_pred)])
plt.xticks([]),plt.yticks([])
plt.show()
from keras.models import Model
from keras.layers import Dense, GlobalMaxPooling2D,Input,Dropout
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD
ここまでは前と同じです。
import matplotlib.pyplot as plt
import os,random
from keras.preprocessing.image import img_to_array, load_img
file_name='monkey'
hdf5ファイルの名前を入れてください。
display_dir='test'
試したい画像を入れたフォルダの名前を指定してください。
label=['chimpanzee','gorilla','orangutan']
分類するクラスの名前を指定します。trainフォルダ、validationフォルダを作る際にその中のフォルダはアルファベット順になっているかと思うので、その順番と同じようにして下さい。もしも、testフォルダの中の画像で、実際に学習済みモデルを使ってみるときに明らかに結果が食い違うならここの記述が違うかもしれません。
N_CATEGORIES = 3
IMAGE_SIZE = 224
BATCH_SIZE = 8
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
base_model = VGG16(weights='imagenet', include_top=False,input_tensor=input_tensor)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(N_CATEGORIES, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
モデル設計の時と同じです。
model.load_weights(file_name+'.hdf5')
これで、学習した結果としてわかった判別するための重みをモデルに付与しています。
model.compile(optimizer=SGD(lr=1e-4,momentum=0.9),
loss='categorical_crossentropy',
metrics=['accuracy'])
モデルの設計をした時と同じようなことを書いてます。
files=os.listdir(display_dir)
listdir関数でファイルの一覧を取得しています。ここではtestフォルダの中の画像ファイルの一覧を取得し、filesに代入している。
filenumber=len(files) filenumberに画像の総数を代入している。
plt.figure(figsize=(15,15))
これで表示する画像のサイズを指定しています。
for i in range(filenumber):
temp_img=load_img(os.path.join(display_dir,img[i]),target_size=(224,224))
plt.subplot(5,5,i+1)
plt.imshow(temp_img)
testフォルダそれぞれの画像について、1つずつ別々の場所に表示させようとしています。
temp_img_array=img_to_array(temp_img)
temp_img_array=temp_img_array.astype('float32')/255.0
temp_img_array=temp_img_array.reshape((1,224,224,3))
temp_imgの画像1つずつについて、処理を加えています。
img_pred=model.predict(temp_img_array)
作ったモデルから予想される、画像のクラスをimg_predに代入。plt.title(label[np.argmax(img_pred)])
画像のタイトルとして表示させようとしています。
plt.xticks([]),plt.yticks([])
これで以下の写真のように目盛りが付いてしまうのを防いでいます。
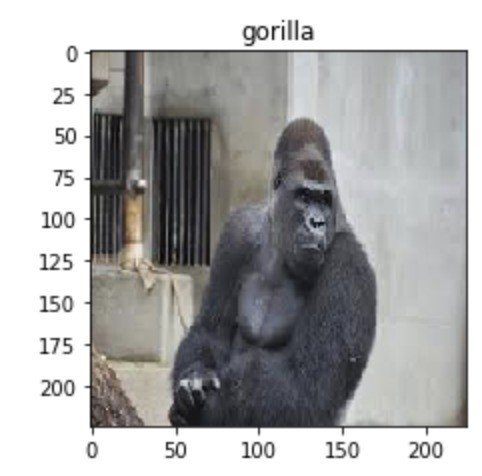
plt.show()
表示させます。

お疲れ様です。
より精度をあげるには
もっと画像を集める
(集めにくい場合は、すでに集めた画像を拡張して増やすのも一手です。参考サイト)
前処理の精度をあげる
エポック数を増やす。
別の学習済みモデルを試してみる
設定した層のところを別のものにしてみる
学習済みモデルのどこまで固定するかを変える
...
などなどが考えられます。色々カスタマイズしてみてください。
想像しうる詰まりそうなところ
・すでに数回述べましたが、.DS_storeが入り込むとエラーが出ます。
(testフォルダの方にも入り込むことがあるので注意です。)
・画像フォルダにひらけないファイルが入っているとエラーが出る
・monkey.hdf5が見当たらない→ 複数のgoogleアカウントを持っている場合、別の方に入っているかも。
・unzipがうまくいかない→ ドライブにあげるときに、圧縮し忘れているかも
・Google colaboratoryは時間制限があります。気をつけましょう!
この記事が気に入ったらサポートをしてみませんか?