pandas_2

今回のモチベーション
今回はExcelファイルとCSVファイルを読み込んでみたいと思います!
そして、簡単な操作(概要を確認)も
やってみます!
Excelファイルの読み込み
臨床で取得した一次データ(自分で取得した
データ)はExcelで保存している事が多いと思います。
それに伴い、分析したいデータもExcelに保存されているデータになるはずです。
今回はダミーデータとして次のようなものを準備しました。
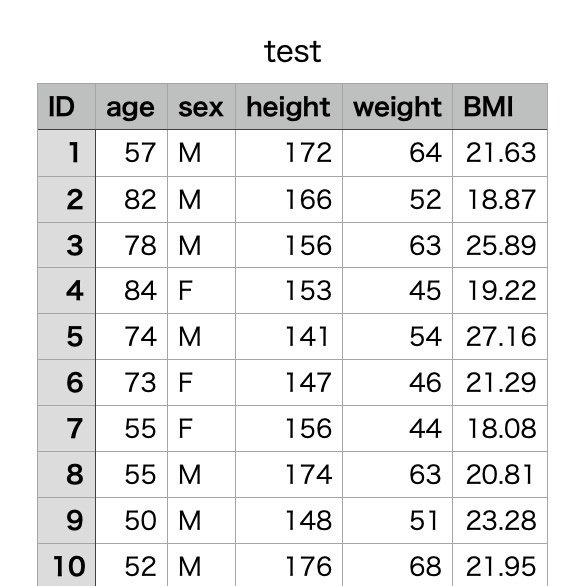
100人分の体格に関するデータです。
このデータはpythonのいろんな技術を
駆使して作成しました。
一定の規則性を持たせました。
保存場所に注意
例えば、デスクトップにあるpythonフォルダにはtest.xlsxというExcelファイルがあるとします。
同じようにpythonフォルダに作業ファイルがあるとします。そして、作業.ipynbという名前であったとします。
整理すると
test.xlsxと作業.ipynbは同じ階層にいます。
この状況下において作業.ipynbでtest.xlsxを読み込むためのコードは次の様になります。
import pandas as pd
df_test1 = pd.read_excel(‘test.xlsx’)次に保存先を少し変えてみます。
pythonフォルダにfileという新しいフォルダを作ります。
そして、fileフォルダにtest.xlsxだけを移動します。
今の状況を整理すると・・・
test.xlsxの保存先
1.Desktop → 2.pythonフォルダ → 3.fileフォルダ
作業.ipynbを保存先
1.Desktop → 2.pythonフォルダ
両者、保存されている位置が違います。
作業.ipynbの方が上流にいます。
このような時はエラーになります。
エラーを起こさないためには次のように
コードを書きます。
import pandas as pd
df_test1 = pd.read_excel(‘file/test.xlsx’)()の中が変わっていることに気づきましたか?
同じ階層にいるときは('test.xlsx')でしたが
作業.ipynbが上流にいる時は('file/test.xlsx')になります。
ファイル名の前にフォルダ名を記載しなければいけません。
自分がどこの階層にいて対象のファイルが
どこにあるかはしっかりと把握しておくことを
オススメします!
これは地味に引っかかりポイントです。
コードの確認
前回のおさらいの意味で1行目にpandasを
インポートするコードも書いています。
ライブラリをインポートしなければ2行目を
書いてもエラーになり実行されません。
ライブラリを使用する場合は必ずインポート
しましょう!
2行目を日本語で表現してみます。
まず左辺(=の左側)です。
「df_test1って名前にするよ」
そして右辺(=の右側)です。
「Excelを読み込むよ」
「読み込むのは()の中に書いてある’test.xlsx’
だよ」
こんな感じでしょうか。
df_test1という変数にtest.xlsxファイルを
代入するイメージです。
読み込みの確認
きちんと読み込んでいるか確認して
みましょう。
df_test1.head()上記のコードで読み込んだデータの先頭5行を
確認する事ができます。
この様になります。

()の中の事を一般的に引数(ひきすう)と
呼ぶのですが今回のコードの引数は表示したい
行数を入力します。
引数を指定しなければ勝手に先頭の5行が
表示されます。
先頭2行だけをを表示する場合は引数を2に
すれば良いですね。
ちなみに、
df_test1.tail()とすると末尾から5行が表示されます。

こちらも表示したい行数を指定したければ
引数に行数分の数字を入力してください。
csvファイルの読み込み
場合によってはExcelではなくcsvで保存
しているケースもあると思います。
次はtest.csvというファイルをpandasで
読み込むコードです。
df_test2 = pd.read_csv(‘test.csv’)上のコードはpandasがインポートされている
前提ですのでimport〜は省略しています。
Excelファイルの時と多少異なりますが
基本は同じです。
こちらもdf_test2にcsvファイルを代入する
イメージで良いかと思います。
次は超簡単な操作でデータの概要を表示してみたいと思います。
データサイズの確認
(サンプルサイズの確認)
データ分析を行うにはデータがどれ位あるか
把握すると思います。
例えばExcelファイルのデータである
df_test1のサイズを確認するには
df_test1.shapeと書けばデータサイズを把握する事が
できます。

(100,6)と表示されました。
これは100行、6列であることを意味します。
データの概要を把握する上で一番初めに
確認することだと思います。
代表値の確認
そして、サンプル数、平均、最小値、最大値、
4分位範囲(25%点、中央値、50%点)も
データを分析する前に把握すると思います。
pandasでは次の1行を書くだけです。
Excelファイルであるdf_test1であれば
df_test1.describe()これだけです。
こうなります。

名義尺度であるsexはMかFであり
数値ではありませんので反映されません。
しかし、同じ名義尺度でもIDは数値ですので
反映されています。
IDの平均値など分かっても何の意味もない
のですが、反映させてしまうあたりは
機械の可愛いところです。
describeメソッドを知った時に
「ヤベー」
と心の中で叫んだのはいい思い出です。
さいごに
今回はファイルに保存しているデータを読み込んでみました。
皆さんも自分で取得してみたデータで実行してみてくれるとうれしいです!
しかし、実際のデータが無い人や個人情報保護の観点から自宅でデータ分析の練習が難しい人は多いのではないでしょうか。
実は世の中には練習用のデータが無数に存在しているのをご存知でしょうか?
次回はそんな練習用のデータで遊んでみたいと
思います!
この記事が気に入ったらサポートをしてみませんか?