とりあえずシュッと OpenAI DevDay の内容をまとめその2

の続き
DALL-E3 での画像生成と ChatGPT-4V の API を試すぞ☆
まずはシュッと画像を生成
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].urlするとこちらのネコちゃんが爆誕☆

まぁ特に気を付けることはないけれど、現状 DALL-E3 は画像生成のみで編集とかはできないぞ☆
リクエスト時のパラメーターが DALL-E3 とそれ以外でちょっと違っているので細かいところは公式ドキュメントを見てね☆
で、次は生成した画像を Vision API で読み込ませてみよう(/・ω・)/
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "写真の中に何が映ってる?"},
{
"type": "image_url",
"image_url": image_url,
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)やってることは簡単で画像 URL を渡しているだけですな(/・ω・)/
(base 64 encode された画像も渡せるよ)
んで結果はこちら
この画像には、2匹のシャム猫が描かれています。
デジタルアートやリアリスティックなイラストで描かれたようです。
猫たちは真っ直ぐ前を見ており、その青い目は非常に生き生きとしていて詳細に作りこまれています。
毛並みの質感や色合いがとても精密で、白とクリーム色が主な体の色ですが、
耳、顔、足、尾にかけて濃い褐色がみられます。ちゃんと読めてるね(/・ω・)/
複数の画像も渡せるみたいよ
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
{
"type": "text",
"text": "What’s in these images? Is there any difference between them?",
},
{
"type": "image_url",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
],
}
],
max_tokens=300,
)
print(response.choices[0])んで detail というパラメータがありんす
低忠実度または高忠実度の画像理解
lowまたはhighの2つのオプションがあるdetailパラメータをコントロールすることで、モデルがどのように画像を処理し、テキスト理解を生成するかを制御できます。
lowは「高解像度」モデルを無効にします。モデルは画像の低解像度バージョン512 x 512を受け取り、65トークンの予算で画像を表現します。これにより、APIはより高速なレスポンスを返すことができ、高詳細を必要としないユースケースではより少ない入力トークンを消費します。
highは "high res "モードを有効にします。これはまずモデルに低解像度の画像を表示させ、次に入力画像のサイズに基づいて512pxの正方形として入力画像の詳細なクロッピングを作成します。各詳細クロップは、トークン予算の2倍(65トークン)、合計129トークンを使用します。
ドキュメントにはちゃんと書いてないけどこういう風に渡しますわよ~
"content": [
{"type": "text", "text": "写真の中に何が映ってる?"},
{
"type": "image_url",
"image_url": { "url": image_url, "detail": "high" },
},
],
low
この画像には、2匹のシャム猫のイラストが描かれています。
彼らはクリーム色のコートと美しい青い瞳を持ち、リラックスした姿勢で一緒に寄り添っています。
猫たちはとてもリアルに描かれており、細部に至るまで丁寧な作画がされています。high
この画像には二匹の猫が描かれています。
それぞれクリーム色とブラウン色のポイントを持つシャム猫
(またはシャム猫に似た品種)のように見えます。
一匹は直接こちらを見つめていて、もう一匹はやや斜めにこちらを見ています。
両方とも青い目をしていて、柔らかそうな毛並みが特徴的です。
美しい描写とリアルなディテールで、高いアートの技術が感じられます。やはり出力に差がありんすねぇ(/・ω・)/
んで制限事項も書かれておりますなぁ
限界
ビジョン付きGPT-4は強力であり、多くの状況で使用することができますが、モデルの限界を理解することが重要です。以下は私たちが認識している限界の一部です:
医療画像: このモデルはCTスキャンのような特殊な医療画像の解釈には適していません。
非英語: 日本語や韓国語のような非ラテンアルファベットのテキストを含む画像を扱う場合、モデルは最適に動作しない可能性があります。
大きなテキスト: 読みやすさを向上させるために画像内のテキストをくしますが、重要な詳細は切り取らないようにしてください。
回転: 回転/上下逆さまのテキストや画像は、モデルが誤って解釈する可能性があります。
視覚的要素: 実線、破線、点線などの色やスタイルが異なるグラフやテキストを理解するのに苦労することがある。
空間的推理: チェスのポジションの特定など、正確な空間定位が必要なタスクに苦戦する。
正確さ: 特定のシナリオにおいて、誤った説明やキャプションを生成することがあります。
画像の形状: パノラマ画像や魚眼画像は苦手です。
メタデータとリサイズ: このモデルは、元のファイル名やメタデータを処理しません。また、画像は分析前にリサイズされ、元のサイズに影響を与えます。
カウント: 画像内のオブジェクトのおおよそのカウントが可能です。
CAPTCHA: 安全上の理由から、CAPTCHAの提出をブロックするシステムを実装しています。
ちゃんと CAPTCHA ブロックはいってるのね(/・ω・)/
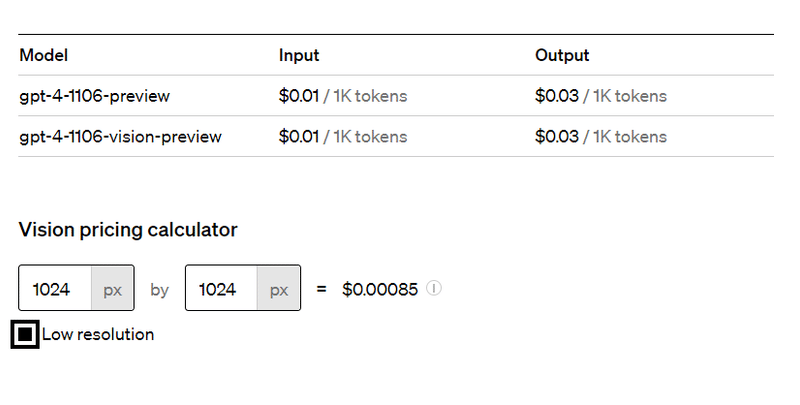
そして気になるコストですな

Vision の方は少々ややこいでござる(/・ω・)/
Calculating costs
Image inputs are metered and charged in tokens, just as text inputs are. The token cost of a given image is determined by two factors: its size, and the detail option on each image_url block. All images with detail: low cost 85 tokens each. detail: high images are first scaled to fit within a 2048 x 2048 square, maintaining their aspect ratio. Then, they are scaled such that the shortest side of the image is 768px long. Finally, we count how many 512px squares the image consists of. Each of those squares costs 170 tokens. Another 85 tokens are always added to the final total.
Here are some examples demonstrating the above.A 1024 x 1024 square image in detail: high mode costs 765 tokens
1024 is less than 2048, so there is no initial resize.
The shortest side is 1024, so we scale the image down to 768 x 768.
4 512px square tiles are needed to represent the image, so the final token cost is 170 * 4 + 85 = 765.
A 2048 x 4096 image in detail: high mode costs 1105 tokens
We scale down the image to 1024 x 2048 to fit within the 2048 square.
The shortest side is 1024, so we further scale down to 768 x 1536.
6 512px tiles are needed, so the final token cost is 170 * 6 + 85 = 1105.
A 4096 x 8192 image in detail: low most costs 85 tokens
Regardless of input size, low detail images are a fixed cost.
しかしまぁ Pricing ページで簡単にわかるのである
というわけでおしまい
この記事が気に入ったらサポートをしてみませんか?