Spotifyのデータから遊佐未森を分析する

さて、みんな大好きSpotifyですが、開発者向けにAPIが開放されておりいろいろなデータを取得できます。
これでちょっと遊んでみましょう。
以下すべて2024年3月時点での情報です。
Spotifyに存在する遊佐未森のスタジオアルバム
Spotifyに存在する遊佐未森のスタジオアルバムは以下の14作品でした。
『水色』『roka』『ECHO』『庭』『small is beautiful』『honoka』『Bougainvillea』と『檸檬』が来てないみたいですね。
『空耳の丘』『ハルモニオデオン』『HOPE』『モザイク』『瞳水晶』『momoism』『アルヒハレノヒ』『アカシア』『休暇小屋』『スヰート檸檬』『銀河手帖』『淡雪』『せせらぎ』『潮騒』
よく聞かれている曲Top10
Spotifyでよく聞かれている遊佐未森の楽曲Topは以下の順。
うーん、やっぱり「地図をください」がトップか。一般的な認知はそこで止まってるんだなあ。
2位以下は初期の名曲が並んでいて「まあ、そうだよね」という印象。
「野生のチューリップ」はスピッツのファンも聴いてるのかな。
1. 地図をください(『空耳の丘』)
2. 夏草の線路(『HOPE』)
3. 暮れてゆく空は(『ハルモニオデオン』)
4. 窓を開けた時(『空耳の丘』)
5. 瞳水晶(『瞳水晶』)
5. 0 の丘 ∞ の空 [version Ⅱ](『ハルモニオデオン』)
7. 靴跡の花(『モザイク』)
8. 僕の森(『ハルモニオデオン』)
9. 野生のチューリップ(『アカシア』)
10. 夢をみた(『HOPE』)
参考までにシングル売上TOP12作品は以下。
1. 地図をください
2. 靴跡の花~アルスラーン戦記より
3. ONE
4. 夏草の線路
5. 野の花
6. 0の丘∞の空
7. 暮れてゆく空は
8. GRACE
9. 東京の空の下
10. タペストリー
11. ココア
12. light song
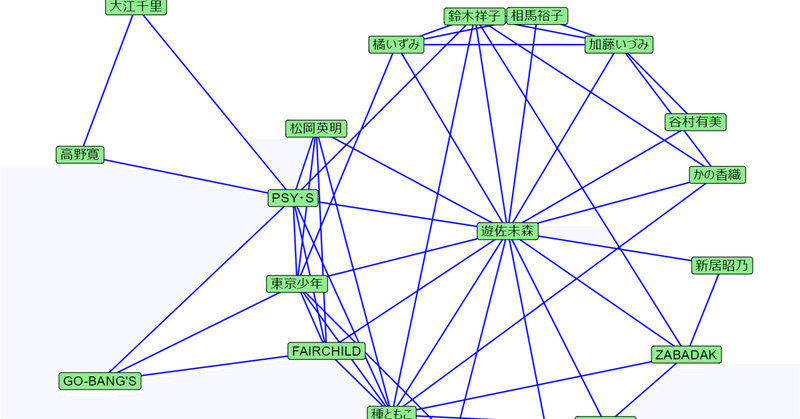
遊佐未森の関連アーティスト

Spotifyでは「ファンの間で人気」という項目で聴き手が共通するアーティストが表示されます。
これを使って遊佐未森に関連するアーティストを確認してみましょう。
手順として、まず遊佐未森の「ファンの間で人気」アーティストを抽出し、次にそのアーティストの「ファンの間で人気」アーティストを抽出します。それらの情報を合わせて、お互いに関連しあう関係だけを取り出します。
結果を可視化したのが上の図です。
顔ぶれとしては80年代後半から90年代前半にかけて活躍した女性ボーカルのアーティストが多いようです。(松岡英明はよく分からない……)
追記:松岡英明は同じEpic Sony出身で、NHK「ジャストポップアップ」での共演経験もあったからではないか、というご意見をいただきました。
各楽曲のポジショニング

Spotifyでは独自のアルゴリズムで各楽曲を分析して指標化しており、その数値もAPIから取得できます。詳しくはこちらなどを参照してください。
この値を使って遊佐未森の各楽曲のポジショニングマップを書いてみたのが上の図です。
Spotifyから取得した値を因子分析で次元縮約しプロットしています。
横軸(ML1、x軸)は右に行くほどエネルギッシュでポジティブな曲。
縦軸(ML2、y軸)はインスト度で上に行くほど人の声の成分が少なくなります。
左上にインスト曲が配置されているのが分かります。
右下に「カラフル!」(『淡雪』)や「野生のチューリップ」(『アカシア』)のように元気な曲が配置されています。どちらも遊佐未森作曲ではない曲ですね……
ほぼ真ん中にあるのが「森とさかな」(『momoism』)で最も平均的な遊佐未森の曲と言えるかも?
ちょっと縦軸のインスト度が効きすぎてる感はありますが、まあ一つの見方としてはありなんじゃないでしょうか。
使用したコード
R言語を使ってSpotify API から情報を取得しました。
実際に使用したコードは以下です。
# ライブラリ呼び出し ---------------------------------------------------------------
library(conflicted)
library(spotifyr)
library(tidyverse)
library(igraph)
library(tidygraph)
library(ggraph)
library(psych)
# 準備 ----------------------------------------------------------------------
Sys.setenv(SPOTIFY_CLIENT_ID = 'xxxxxxxxxxxx')
Sys.setenv(SPOTIFY_CLIENT_SECRET = 'xxxxxxxxxxxx')
mimori_yusa <- "遊佐未森" |>
search_spotify(type = "artist")
# 人気曲は --------------------------------------------------------------------
mimori_yusa$id |>
get_artist_top_tracks() |>
dplyr::select(popularity, name, album.name) |>
arrange(desc(popularity))
# 関連アーティスト ----------------------------------------------------------------
# 「ファンの間で人気」
# https://support.spotify.com/jp/artists/article/fans-also-like/
# 1秒待ってspotifyr::get_related_artists()を実行する関数を定義
get_related_artists_Sys_sleep <- function(id) {
Sys.sleep(1)
spotifyr::get_related_artists(id)
}
# 複数のアーティストをベクトルで与えて関連アーティストを取得する関数を定義
my_get_related_artists <- function(ids, artist_names) {
ids <- unique(ids)
artist_names <- unique(artist_names)
artist_names_df <- data.frame(from = artist_names) |>
rowid_to_column()
purrr::map(
ids,
\(ids) get_related_artists_Sys_sleep(ids),
.progress = TRUE
) |>
purrr::list_rbind(names_to = "rowid") |>
dplyr::left_join(
artist_names_df,
by = join_by(rowid)
) |>
select(from, name, id)
}
# 第1段階取得
related_step1 <- my_get_related_artists(
ids = mimori_yusa$id,
artist_names = mimori_yusa$name
)
# 第2段階取得
related_step2 <- my_get_related_artists(
ids = related_step1$id,
artist_names = related_step1$name
)
# 第1段階と第2段階を合わせてエッジリストとして整理
# さらに相互に関連しあう無向グラフに整形
# さらにネットワーク形式のオブジェクトに変換
g <- bind_rows(
related_step1, related_step2
) |>
distinct() |>
dplyr::select(from, to = name) |>
mutate(
z1 = pmax(to, from),
z2 = pmin(to, from),
.keep = "none"
) %>%
dplyr::filter(duplicated(.)) |>
as_tbl_graph(directed = FALSE) |>
mutate(center = if_else(name == "Mimori Yusa", TRUE, FALSE))
# アーティスト名を日本語表記に直す
artist_names <- V(g)$name
V(g)$name <- case_when(
artist_names == "Syoko Suzuki" ~ "鈴木祥子",
artist_names == "Tomoko Tane" ~ "種ともこ",
artist_names == "PSY・S[saiz]" ~ "PSY・S",
artist_names == "Yumi Tanimura" ~ "谷村有美",
artist_names == "Mimori Yusa" ~ "遊佐未森",
artist_names == "Hideaki Matsuoka" ~ "松岡英明",
artist_names == "Izumi Kato" ~ "加藤いづみ",
artist_names == "Senri Oe" ~ "大江千里",
artist_names == "Izumi Tachibana" ~ "橘いずみ",
artist_names == "Hiroko Taniyama" ~ "谷山浩子",
artist_names == "Hiroko Sohma" ~ "相馬裕子",
artist_names == "Hiroshi Takano" ~ "高野寛",
artist_names == "Cano Caoli" ~ "かの香織",
artist_names == "Shang Shang Typhoon" ~ "上々颱風",
.default = artist_names
)
# 遊佐未森を中心としたネットワーク図を描く
g |>
ggraph('focus', focus = center) +
geom_edge_fan(color = "blue") +
geom_node_label(aes(label = name), fill = "lightgreen", size = 3.5) +
coord_fixed() +
theme_graph() +
labs(title= "遊佐未森の関連アーティスト on Spotify")
# 楽曲の知覚マップ ----------------------------------------------------------------
# アルバムのリスト
mimori_yusa_albums <- "遊佐未森" |>
search_spotify(type = "album")
# シングル、ベスト盤、ライブ盤は除く
mimori_yusa_albums_clean <- mimori_yusa_albums |>
dplyr::filter(!(name %in% c(
"VIOLETTA THE BEST OF 25 YEARS (DISC2)",
"PEACH LIFE",
"P E A C H T R E E",
"カリヨン・ダンス",
"鈴懸の風薫る"
))) |>
dplyr::select(id, name, release_date, total_tracks) |>
arrange(release_date)
# 1秒待ってspotifyr::get_album_tracks()を実行する関数を定義
get_album_tracks_Sys_sleep <- function(id) {
Sys.sleep(1)
spotifyr::get_album_tracks(id, limit = 50)
}
# 各アルバムに収録された楽曲のリストを取得
track_list <- mimori_yusa_albums_clean$id |>
purrr::map(
\(id) get_album_tracks_Sys_sleep(id),
.progress = TRUE
) |>
purrr::list_rbind() |>
select(name, id)
# 楽曲の分析情報を取得
data1 <- track_list$id[1:100] |>
get_track_audio_features()
data2 <- track_list$id[101:147] |>
get_track_audio_features()
# 必要なデータを抜き出し標準化
# 対数instrumentalness, speechiness
data <- bind_rows(data1, data2) |>
dplyr::select(
danceability, energy, loudness, speechiness, acousticness, instrumentalness, valence)|>
mutate(
instrumentalness = sqrt(instrumentalness),
speechiness = sqrt(speechiness)
) |>
scale() |>
as.data.frame()
# 知覚マップ
res_fa <- fa(data, nfactors = 2, rotate = "promax", fm = "ml")
print(res_fa, sort = TRUE)
tibble(
ML1 = res_fa$scores[, 1],
ML2 = res_fa$scores[, 2],
name = track_list$name
) |>
ggplot(aes(x = ML1, y = ML2, label = name)) +
geom_hline(yintercept = 0, color = "blue", linetype = 2) +
geom_vline(xintercept = 0, color = "blue", linetype = 2) +
geom_label(size = 2.5, fill = "lightgreen") +
coord_fixed(ratio = 1, xlim = c(-2.5, 2.5), ylim = c(-1, 4))
# x軸(ML1):よりエネルギッシュでポジティブで電気的
# y軸(ML2):インスト度
# item ML1 ML2 h2 u2 com
# energy 2 0.91 -0.19 1.00 0.005 1.1
# acousticness 5 -0.72 0.12 0.59 0.413 1.1
# valence 7 0.71 0.13 0.46 0.543 1.1
# danceability 1 0.53 0.13 0.24 0.756 1.1
# instrumentalness 6 0.14 0.87 0.70 0.303 1.0
# loudness 3 0.53 -0.57 0.82 0.178 2.0
# speechiness 4 0.04 0.50 0.23 0.766 1.0
この記事が気に入ったらサポートをしてみませんか?