【Python学習日記5】 生鮮野菜の価格予測

こんにちは。プログラミングスクールでPythonを使ったデータ分析を学習中の ひよっこ分析者B(Book358)です。今回はスクールで教わったSARIMAモデルの復習(実践)を兼ねて、過去の「市場データ (各野菜の卸売価格)」を元に
、未来の「野菜価格(11品目)」を予測する Nishikaの定期開催コンペにトライしてみました。
※ 開発環境
Python3,Windows11 ,Chrome,Google Colaboratory
1. 概要
1.1 題目
生鮮野菜の価格予測2024冬
1.2 目的
「各野菜の日次の卸売価格」の市場データを用いて、生鮮野菜(11品目)の価格を予測する機械学習モデルを構築すること
(今回はSARIMAモデルを使用)
1.3 データセット
・train.csv
訓練データ
・test.csv
評価データ
・weather.csv
天候データ
・sample_submission.csv
投稿データ (フォーマット)
2. SARIMA
2.1 SARIMAモデル
SARIMAはSeasonal Autoregressive Integrated Moving Average(季節自己回帰和分移動平均)モデルの略称。時系列データの予測や分析に使用される統計モデルの一つ。SARIMAモデルは季節性やトレンドを考慮して時系列データのパターンを捉えることができるため、季節変動やトレンドのあるデータの予測に有効です。(PythonのStatmodelsライブラリなどを使用して、SARIMAモデルを構築・評価することが可能)
2.2 SARIMAのパラメータ
・ARIMAパラメータ (p, d, q)
p:自己相関度 (モデルが直前 p個の値を用いて予測されるのか)
d:誘導 (時系列データを定常にするために d次の階差が必要)
q:移動平均 (モデルが直前 q個の値に影響を受ける)
・季節パラメータ (sp, sd, sq, s)
sp:季節性自己相関
sd:季節性導出
sq:季節性移動平均
s:季節周期
3. ライブラリのインポート
使用するライブラリをインポート。
import pandas as pd
import numpy as np
import datetime as dt
import warnings
import itertools
import statsmodels.api as sm
import matplotlib.pyplot as plt
import math
from sklearn.metrics import mean_squared_error
from google.colab import drive
drive.mount('/content/drive')
pd.options.display.max_rows = 54. データセット
訓練データ(train.csv)と評価データ(test.csv)を読込んだ後、価格(mode_price)を予測する野菜の種類を確認します。
train = pd.read_csv('/content/drive/MyDrive/Datasets/train.csv')
test = pd.read_csv('/content/drive/MyDrive/Datasets/test.csv')
train
test

※ kind:野菜の種類 date:日付 amount:卸売数量
mode_price:卸売価格(中央値) area:産地 year:年 weekno:週番号
for kind in test["kind"].unique():
print(kind)
5. 過去5年間のデータを抽出
pd.to_datetimeで、訓練データのindexにdatetime型の日付を代入し、過去5年間のデータを抽出します。
(6年以上前の古いデータは予測に用いない事にしました。)
train.index = pd.to_datetime(train["date"], format = "%Y%m%d")
train = train[train.index > dt.datetime(2018,7,1)]
train
6. 「だいこん」の予測
予測する野菜(11種類)の内、「だいこん」の価格を予測します。
6.1 前処理
「だいこん」のデータを抽出した後、週毎の平均値に変換します。
daikon = train[train.kind == 'だいこん']
daikon.drop(["kind", "date", 'amount', 'area', "year", "weekno"], axis=1, inplace=True)
daikon = round(daikon.resample(rule="W").mean())
daikon
6.2 価格推移をプロット
「だいこん」の価格推移(過去5年間)をプロットします。
(グラフ上の緑の区間(2023年8月)が予測対象)
plt.figure(figsize=(24, 8))
plt.plot(daikon)
plt.axvspan('2018-07-01', '2018-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2018-08-01', '2018-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2019-07-01', '2019-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2019-08-01', '2019-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2020-07-01', '2020-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2020-08-01', '2020-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2021-07-01', '2021-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2021-08-01', '2021-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2022-07-01', '2022-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2022-08-01', '2022-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2023-07-01', '2023-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2023-08-01', '2023-08-31', facecolor='C2', alpha=0.2)
plt.show()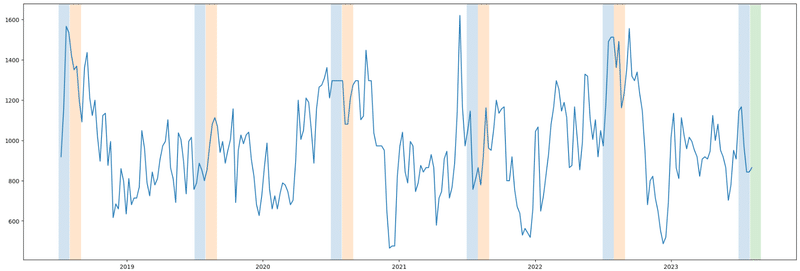
6.3 関数を定義 (orderの最適化)
SARIMAモデルに於いて、最適なハイパーパラメータを探索する関数を定義します。
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]6.4 ハイパーパラメータ探索
野菜が1年(12カ月=52週)周期で価格変動する事を前提とし、「だいこん」データに於けるSARIMAの最適なハイパーパラメータを探索します。
param_daikon = selectparameter(daikon, 52)
param_daikon
※ [(p, d, q), (sp, sd, sq, s), BIC]
p:自己相関度, d:誘導, q:移動平均
sp:季節性自己相関, sd:季節性導出, sq:季節性移動平均, s:季節周期
BIC:ベイズ情報量規準。統計モデルの良さや予測能力を評価する指標の
一つ。BICの値が小さいほどモデルの予測性能が良い。
6.5 モデル構築 (SARIMA)
ハイパーパラメータ探索の結果をorder 及び seasonal_orderに入れて、SARIMAモデルを構築します。
SARIMA_daikon = sm.tsa.statespace.SARIMAX(daikon, order=(1,1,1), seasonal_order=(0,1,1,52)).fit()
SARIMA_daikon.bic
6.6 予測値をプロット
予測値を算出してプロットします。
pred_daikon = pd.DataFrame(round(SARIMA_daikon.predict("2018-07-08", "2024-08-30"), 1))
pred_daikon = pred_daikon.rename(columns={'predicted_mean':'mode_price'})
pred_daikon
plt.figure(figsize=(24, 8))
plt.plot(daikon)
plt.plot(pred_daikon, color="r")
plt.axvspan('2018-07-01', '2018-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2018-08-01', '2018-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2019-07-01', '2019-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2019-08-01', '2019-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2020-07-01', '2020-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2020-08-01', '2020-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2021-07-01', '2021-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2021-08-01', '2021-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2022-07-01', '2022-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2022-08-01', '2022-08-31', facecolor='C1', alpha=0.2)
plt.axvspan('2023-07-01', '2023-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2023-08-01', '2023-08-31', facecolor='C2', alpha=0.2)
plt.axvspan('2024-07-01', '2024-07-31', facecolor='C0', alpha=0.2)
plt.axvspan('2024-08-01', '2024-08-31', facecolor='C1', alpha=0.2)
plt.show()
(青:訓練データ, 赤:予測値)
7. Submitデータを作成
以下の手順でSubmitデータを作成します。
7.1 対象期間の予測値を抽出
対象期間(2023年8月)の予測値を抽出し、インデックスを振り直します。
pred_daikon = pred_daikon.reindex(pd.date_range(start='2023/7/30', end='2023/9/3'))
pred_daikon = round(pred_daikon.interpolate(), 1)
pred_daikon = pred_daikon.reset_index()
pred_daikon.insert(0, "kind", "だいこん")
pred_daikon = pred_daikon.rename(columns={'index':'date'})
pred_daikon
7.2 Submit用のデータセット
Submnit用のデータセットを読込みます。(予測値を入れる「mode_price」の列は一旦削除します。)
sub = pd.read_csv('/content/drive/MyDrive/Datasets/sample_submission.csv')
sub_daikon = sub[sub.kind == 'だいこん']
sub_daikon['date'] = pd.to_datetime(sub['date'], format='%Y%m%d')
sub_daikon = sub_daikon.drop('mode_price', axis=1)
sub_daikon
7.3 予測値を結合
Submnit用のデータセットの日付をキーにして、予測値を結合(マージ)します。
sub_daikon = pd.merge(sub_daikon, pred_daikon, on=['kind', 'date'], how="left")
sub_daikon["date"] = sub_daikon["date"].dt.strftime('%Y%m%d').astype(int)
sub_daikon
8. 考察
今回の「生鮮野菜の価格予測」では、SARIMAモデルで過去の「市場データ (各野菜の卸売価格)」を元に、未来の「野菜価格(11品目)」を予測しました。この後、「だいこん」と同じ流れで残り10種類の野菜の価格も予測し、結果を投稿しましたが、最終スコア(Nishikaのコンペ結果)は「28.5」とあまり良くはなかったです。
精度を上げるには、天候データ, 産地, 卸売数量, 予測対象外の野菜などの関連データも用いて予測しないといけない様ですが、今回はSARIMAモデルの使い方の復習という事で、価格(mode_price)の推移のみで予測してみました。