
ChatGPTで実現するデータ分析の世界:バイバイSQL(LangChain SQL Database Agent)

データアナリストやデータマネジメントなどの職業が、ChatGPTをはじめとするLLMの出現によってなくなると言われています。私もデータに深くかかわる仕事をしているので、少し気になりますね。
自分のポジショントーク的にはいやいや~無理でしょて気持ちにはなるのですが、少し調べてみました。
今回は、ChatGPTを活用してテーブル作成やデータ抽出をやってみます。やってみたら、SQLがいらなくなる可能性がありえるかもと思いました。
LangChain SQL Database Agent
LangChain
LangChainはご存じだと思いますが、LLMを便利に使うためのPythonのライブラリです。LLMの使いかたは、SNSなどで日々いろいろな方がアイデアがディスカッションされていますし、論文も発表されています。
そのようなアイデアが数行のコードで実現することができるのがLangChainです。
毎日アップデートしているような状況で、まだまだ粗削りなところがあります。
最近の私はLangChainのアップデートを確認し、新機能を発見して使って遊んでみるというのが日課になっています。
SQL Database Agent
LangChainではAgentという仕組みがあります。
これはLLM(今回はChat GPT)とToolを用意することで、様々なタスクをLLMと連動して実行することができるようになります。
ToolはLLMからデータアクションを実現するツールです。例えば今回はLLMがSQLを実行する必要があると判断した場合に、SQLを実行するツールを指します。
この仕組みの詳細は以下の記事が参考になるかと思います。
LangChainのコードについては、こちらの記事を参照しています。
やってみましょう
今回はChatGPTと連動して、テーブルを作成し、データを抽出する一連の例を実行します。
pip install
まずはこれから。LangChainは毎日更新しているので、バージョン指定をすると、確実に動くかとおもいます。
load_dotenvはlangchainに環境変数としてOpen AI のAPI KEYを渡すのに使用します。
pip install langchain==0.0148
pip install load_dotenvインポート部分
Agentは一連のタスクを実行するために定義されたクラスになります。
AgentはLLMとToolで構成されます。
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from dotenv import load_dotenvLLM
今回はChatGPTを使用します。
from langchain.llms.openai import OpenAI
Agent
Sql Agentを使用します。
詳しくは後ほど説明します。
from langchain.agents import create_sql_agent
Tool
今回はあらかじめ用意されている SQLDatabaseToolkitを使用します。
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
AgentExecuter
AgentExecuterはChatGPTとToolとのやり取りを自動化してくれます。ChatGPTがツールを使う必要がある、つまり今回はSQLを実行する必要があると、それを検知して、Toolを実行することを自動化してくれます。
今回はチュートリアルなので、細かい設定はしていませんが、実行上限回数など細かな設定が可能です。(他のノートで解説予定です)
from langchain.agents import AgentExecutor
初期化部分
load_dotenv()
chatgpt = OpenAI(temperature=0.5)
chatgpt.openai_api_key ='your_open_ai_api_key'
db = SQLDatabase.from_uri("sqlite:///sound.db")
toolkit = SQLDatabaseToolkit(db=db).envファイルを作成する
`.env`というファイル名のファイルを作成して以下のように取得したAPIを入力します。
「OPENAI_API_KEY」の変数名は重要です。これらの変数名をKeyとした環境変数が、後ほど作成されます。最終的には、以下のように処理されるとイメージするとわかりやすいでしょう。
イメージ:env['OPENAI_API_KEY']='sk-tbnwI3DATvzzwxisdalfjalsdjfasdlfjaf'
そして、環境変数にAPI_KEYが設定されると、LangChainは特にコーディングせずにAPI_KEYを読み込んで処理を実行します。
OPENAI_API_KEY = 'sk-tbnwI3DATvzzwxisdalfjalsdjfasdlfjaf'最後にload_dotenv() でOPENAI_API_KEYを読み込みます。
ChatGPTの初期化
OpenAIで初期化します。これはデフォルト値は以下のようになっています。
主要なところは太字にしています。
model_name: str = "gpt-3.5-turbo" #モデル名
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Holds any model parameters valid for `create` call not explicitly specified."""
openai_api_key: Optional[str] = None #API KEY
max_retries: int = 6 #リトライ数
prefix_messages: List = Field(default_factory=list)
"""Series of messages for Chat input."""
streaming: bool = False #チャットをストリーミングを受取るとき True
chatgpt = OpenAI(temperature=0.5)
chatgpt.openai_api_key ='your_open_ai_api_key'
OpenAIのAPIの取得方法
手前みそになりますが、API KEYの取得方法がわからないって方はこちらでどうぞ。
DBの初期化
今回はSQLiteをわかりやすさを優先して使用します。
以下の部分では、ローカルのあなたのプロジェクトフォルダにsound.dbファイルを作成しています。
形式は sqlite:// のあとにローカルファイルのパスを指定します。
今回は sqlite:///sound.db ですので、プロジェクトのルートにファイルを作成します。
db = SQLDatabase.from_uri("sqlite:///sound.db")
作成したdbをlangchainのtoolに渡します
toolkit = SQLDatabaseToolkit(db=db)
テーブルを作成します
SQL書くのかなと思っている人いませんか。
なんとSQLは必要ありません。
agent_executor.run("playlisttrack テーブルを作成してテストデータを10行挿入してください")SQLエラーとはおさらば!
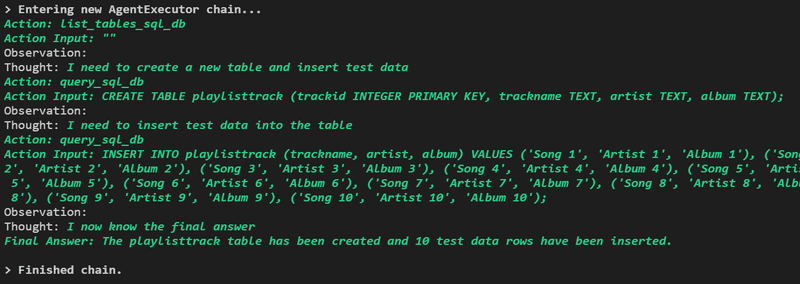
テーブルを作成して、テストデータを入力しています。
Action: list_tables_sql_db
Action Input: ""
Observation:
Thought: I need to create a new table and insert test data
(新しいテーブルを作成し、テスト データを挿入する必要があります)
Action: query_sql_db
Action Input: CREATE TABLE playlisttrack (trackid INTEGER PRIMARY KEY, trackname TEXT, artist TEXT, album TEXT);
一般的なサウドトラックのスキーマってこんな感じだよねって感じでCreate文を作成していますね。
そしてそれにあったテストデータを作成しています。
今回はうまく行きましたが、SQLでエラーが起こった場合はどうなるでしょうか。
例えばこんな感じです。
Observation: Error: (sqlite3.OperationalError) table playlisttrack already exists
[SQL: CREATE TABLE playlisttrack (trackid INTEGER PRIMARY KEY, trackname TEXT, artist TEXT, album TEXT);]
(Background on this error at: https://sqlalche.me/e/14/e3q8)
Thought: The table already exists, so I need to insert test data
(テーブルはすでに存在しますので私はテストデータを入力します)
すでに作成済みのテーブルがある状態で、先ほどのコードを再実行します。エラーが起こったことに対して、テーブル作成は不要であると判断して、テストデータだけを入力しています。

LangChainで便利なのはエラーを自動的に補正しようとするところです!細かな列名の間違いなどを、想定される文字列のパターンでエラー補正を試みます。例えば以下のような動きになります。
agent_executor.run("playlrack テーブルにテストデータを10行挿入してください")まずテーブル名がTypoして間違っています。
(正:playlisttrack 誤:playlrack)

スキーマを探すことでplaylrackテーブルは playlisttrackのことであると判断しています。Typoはテーブルを確認することにより解消しました。これらはSQLだとエラー”テーブルがありません”ということで処理が終了するだけですね。
Action: list_tables_sql_db
Action Input: ""
Observation: playlisttrack
Thought: I should check the schema of the playlisttrack table to see what columns I need to insert data into.
今度はPrimary Keyのエラーです
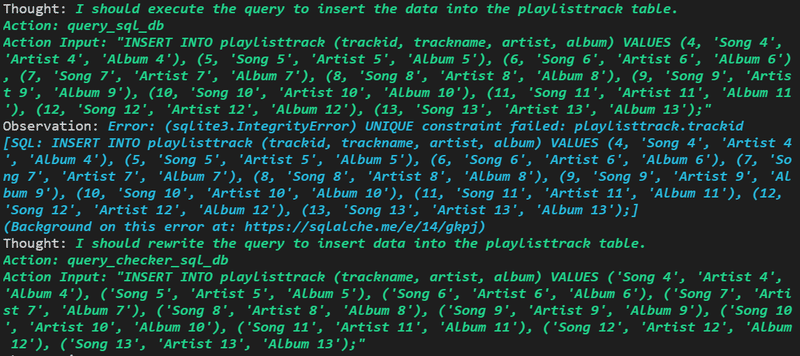
あるあるのエラーになっていますが、これらを改善するSQLを書いて、新たなテストデータを書き込もうとしています。
Error: (sqlite3.IntegrityError) UNIQUE constraint failed:(重複制限のエラー) playlisttrack.trackid
[SQL: INSERT INTO playlisttrack (trackid, trackname, artist, album) VALUES (4, 'Song 4', 'Artist 4', 'Album 4'), (5, 'Song 5', 'Artist 5', 'Album 5'), (6, 'Song 6', 'Artist 6', 'Album 6'), (7, 'Song 7', 'Artist 7', 'Album 7'), (8, 'Song 8', 'Artist 8', 'Album 8'), (9, 'Song 9', 'Artist 9', 'Album 9'), (10, 'Song 10', 'Artist 10', 'Album 10'), (11, 'Song 11', 'Artist 11', 'Album 11'), (12, 'Song 12', 'Artist 12', 'Album 12'), (13, 'Song 13', 'Artist 13', 'Album 13');](Background on this error at: https://sqlalche.me/e/14/gkpj)
最後には、エラーが返ってきていないようですので、最後にSelectしてデータが入っているか確認しています。
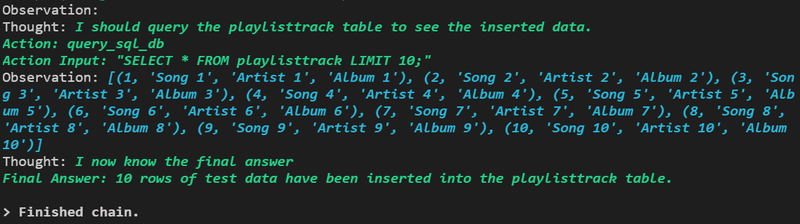
Observation:
Thought: I should query the playlisttrack table to see the inserted data.
(playlisttrack tableにインサートされたデータを確認する必要がある)
Action: query_sql_dbAction Input: "SELECT * FROM playlisttrack LIMIT 10;"
(query_sql_dbAction Inputで次に実行するクエリを指定している)
ここまでの全体のコード
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from dotenv import load_dotenv
load_dotenv()
chatgpt = OpenAI(temperature=0.5)
db = SQLDatabase.from_uri("sqlite:///sound.db")
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
#agent_executor.run("playlisttrack テーブルを作成してテストデータを10行挿入してください")
agent_executor.run("playlrack テーブルにテストデータを10行挿入してください")集計してみましょう
まず以下を実行します。
SQLは??不要です!
agent_executor.run("各アルバムの合計トラック数を表示します。結果にはアルバム名,合計トラック数が含まれている必要があります。")エラーなく結果が返ってきました。

答えは以下のようになっています。
Thought: I now know the final answer.
Final Answer: Album 9 has 2 tracks, Album 8 has 2 tracks, Album 7 has 2 tracks, Album 6 has 2 tracks, Album 5 has 2 tracks, Album 4 has 2 tracks, Album 10 has 2 tracks, Test Album 9 has 1 track, Test Album 8 has 1 track, Test Album 7 has 1 track.
ちょっと使いづらいのでJson形式で結果をだしてもらいます。
agent_executor.run("各アルバムの合計トラック数を表示します。結果にはアルバム名,合計トラック数が含まれている必要があります。json形式で返してください。")答えは以下のようになりました。いいですね!
Thought: I now know the final answer
Final Answer: [{"album": "Album 1", "total_tracks": 1}, {"album": "Album 10", "total_tracks": 2}, {"album": "Album 11", "total_tracks": 1}, {"album": "Album 12", "total_tracks": 1}, {"album": "Album 13", "total_tracks": 1}, {"album": "Album 2", "total_tracks": 1}, {"album": "Album 3", "total_tracks": 1}, {"album": "Album 4", "total_tracks": 2}, {"album": "Album 5", "total_tracks": 2}, {"album": "Album 6", "total_tracks": 2}]

感想
ChatGPTが素晴らしいのは、柔軟性のある言葉でインターフェースができ、多次元の概念を表現できることです。この点において、データの抽出や集計などの作業に適していると思われます。SQLを使えなくても、データ分析が可能になりそうですね!
さらに、集計における定義をDBに保存しておき、ChatGPTに定義の確認などのプロセスを挟んでもらうことで、より精緻な集計が可能になります。また、定義が定まっていない場合には、ChatGPTに提案してもらうこともできるかもしれません。
さらに、通常の言葉で分析できるため、音声認識などと組み合わせれば、会議中に数値をすばやく確認できるかもしれません。ChatGPTが回答してくれるなんて便利ですね。
今回はうまくいく例だけ記載しましたが、実際はエラーを解決できず、結果がでないなどということも多くありました。この点は今後に期待ですね!
この記事が気に入ったらサポートをしてみませんか?