ChatGPT対Bard対Claude大規模言語モデル評価

こんにちは!ChatGPT部の烏谷です。
前回は、ローカルで動く大規模言語モデル評価として、ChatGPTのようにサーバー型ではなく、ローカルで動く大規模言語モデルについて、問題への解答を例に比較していきました。
では、そもそものサーバー型はどうなんでしょうか。ChatGPTはもちろんのこと、AnthropicのClaudeやGoogleのBardなどが、「GPT-4Vを超える」性能を持つとして、新たなモデルを相次いでリリースしてきています。
そこで、今回は、これらのサーバー型のAI Chatについて日本語の
ChatGPTが一般ユーザー向けに提供されて1年以上が経過しました。その間、ChatGPTのユーザー数が大きく伸び、マルチモーダル対応などの様々な進化を遂げてきました。
一方で、ChatGPT以外の生成AIも多く誕生してきました。その中でも、ChatGPTなどのサーバー型では対話履歴を渡すことになるというセキュリティ面での懸念から、ローカルで動く大規模言語モデルに注目があつまり、多くが開発され、オープンソースとして公開されているものもあります。
その中には、有名企業が独自学習でつくったものや、日本語継続学習のモデルなど様々な種類があります。今回は、これらのローカルで動く大規模言語モデルを比較していきたいと思います。
対象とするサーバー型AI Chat
今回は前述の通り、サーバー型のAI Chatサービスを比較します。対象は次の4種類です。
ChatGPT GPT-3.5
Open AI社が提供するAI Chatサービスで、いまの生成AIブームを巻き起こした立役者です。先月末(23年11月)に公開から1周年を迎えました。
ChatGPTのサイトにいって、フリーで使えるものがこちらです。
ChatGPT GPT-4
GPT-3.5の新たなバージョンとして、23年3月14日にリリースされました。GPT-3.5に比べて、圧倒的に多くのパラメータを持つとされているが、その正確な数は不明です。
長文に対応したり、回答の精度もGPT-3.5とは比べ物になりません。また、直近ではGPT-4Vとして画像などのマルチモーダル対応もされています。
ChatGPT Plus(月額$20)に申し込むと利用可能です。
Brad
Googleが提供するAI Chatサービスです。23年12月6日に、新たな生成AIモデル「Gemini」のミドル版「Gemini Pro」の英語版をBardに搭載しているそうです。(日本語版はまだ未対応のようですね。日本語版のAIモデルは、PaLM2のままなのでしょうか。)
他のサービスと違って、バージョンの明記がなかったので、記録として日本時間2023/12/11にテストを行った旨を記述しておきます。
Bardのサイトにいって、フリーで使えます。
Claude2
Anthropicが提供するAI Chatサービスです。2023年10月19日から日本でも利用可能になりました。※Claude2.1モデルが23年11月21日に発表されており、有料版のClaude Proにアップグレードすると利用できるようですが、今回はClaude2のみを評価対象とします。
ChatGPTに比べて、大量の文章を扱える・解答に安全性があるということが言われています。
Claudeのサイトにいって、フリーで使えます。
評価する軸
ここは、前回と同じです。
大規模言語モデルの評価軸としては、正しく設問に解答できるか。質問に対して適切な文章を作成できるか。社会倫理を守った回答ができるか。など様々な観点がありますが、今回は比較が明確にできる設問に正しく解答できるかを評価したいと思います。
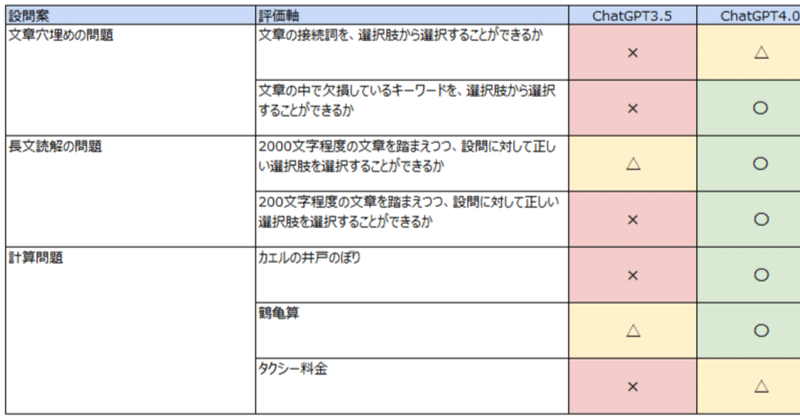
文章穴埋めの問題
大学受験レベルの国語の問題をもとに、文章の前後関係を踏まえて、正しく選択することができるかを検証します。
長文読解の問題
大学受験レベルの国語の問題をもとに、2000文字程度や200文字程度の文章を踏まえつつ、設問に正しい選択肢を選ぶことができるかを検証します。
計算問題
中学受験でよく出題されそうな、次の問題を正しく計算し、解答できるかを検証します。・カエルの井戸登り・鶴亀算・タクシー料金
評価結果
〇:設問に対して解答しており、すべて正しい解答△:設問に対して解答しており、一部のみ正しい解答×:設問に対して解答しているが、正しくないー:そもそも設問に大して解答をしていない
評価結果は次の通りでした。

単純な〇×の付き具合だと、ChatGPT GPT-4.0がまだまだ優位というところでしょうか。特に、計算問題(カエルの井戸登りや、鶴亀算≒連立方程式などは、GPT-4.0では完璧に解答できていたのが、GPT-3.5やBard, Claude2では見当違いな解答をしたりと、散々な結果でした。
ちなみに、このあたりの評価は、ローカルで動く大規模言語モデルでも同様でした。答えが明確に決まる計算問題は、AIの得意領域ではと思っていたのですが、まだまだ進化の途中のようですね。
一方で、文章穴埋め・長文読解の国語的な要素では、GPT-4.0, Bard, Claude2はほぼ同程度の解答精度を示していることがわかりました。
サマリ
国語・数学(算数)をトータルすると、やはり現時点ではGPT-4.0が強いということがわかりました。(特に数学・算数の問題への解答力が高い)
一方で、長文読解で200文字2000文字を読み込んでの設問は、GPT-4.0, Bard, Claude2ともに、正しい選択肢を解答できていました。Claude2は長文が得意ともいわれているので、より長い文章(そうなると今回の大学入試レベルではなくなりそうですが)で評価すると、GPT-4.0を超えるかもしれませんね。
また、穴埋め問題では、これまでどの生成AIでも全問正解できてこなかった、接続詞の穴埋め問題に対して、Bard が完璧な解答を返してくれました。
解答だけでなく、解説についてもしっかり行うことができており、選択肢にないものでは、こういうワードも使えますといった提言をするなど、レベルの高さを感じました。しかし、「文章の中で欠損しているキーワードを、選択肢から選択することができるか」では、その提言が裏目に出たか、一部の解答で選択肢にないものしか答えないといった、あるまじき解答もしてしまっています。(他があっていたので、惜しかった)
Claude2も、国語の日本語力では、GPT-4.0と同程度といったところでしょうか。Bard が間違えた「文章の中で欠損しているキーワードを、選択肢から選択することができるか」では、文章の内容を抽出して、だからこの選択肢が正しいといった解説を、GPT-4.0よりも分かり易く表現してくれています。
ということで、今回はChatGPTを含めて、サーバー型のAI Chatについて評価をしてきました。
ここでの評価としては、まだChatGPT GPT-4.0が優位というレベルでしたが、BardやClaude2のレベルもそれに近づいてきており、今後日本語版BardのGemini対応が進められたり、Claudeの有償版で利用できるClaude2.1などを用いると、より高い精度が得られるかもしれません。
ぜひ、今回の検証結果も参考に、大規模言語モデルの活用を進めていってください。
この記事が気に入ったらサポートをしてみませんか?