
電撃発表!GPT-4を超えるGoogleの次世代生成AIモデル,「Gemini」登場

12月6日グーグルが次世代AIモデル「Gemini」発表しました。Geminiは、今年5月に開催されたGoogleの開発者向けイベントで「現在開発中である」とだけ公開されていたものの、ここまで急速に発表されるとは思っていませんでした。今回はGeminiについて詳しく見ていきたいと思います。

現在提供されているのは、Geminiの機能のうちほんの一部です。今後はテキストだけではなく、音声など異なる種類のデータを処理できる「マルチモーダル」機能が追加されるようになるみたいです。
これまでのグーグルによる生成AIと同様にGeminiも今のところEUでは利用できません。
Geminiの特徴は、「マルチモーダルかつ論理的な判断に優れている」という点であり、マルチモーダルとは、画像だけ・テキストだけでなく、人間と同じように「画像」「文字」「音声」「動画」といった複数の要素を同時に扱えるということです。
これらにより、複雑な文字情報や視覚情報を理解するのに役立ち、膨大な量のデータの中から識別するのが難しい知識を発見することが可能になります。
さらに、Geminiはテキスト、画像、音声などのマルチモーダルな情報を認識し理解するために訓練されており、音声と動画のコンテキストも理解し、複雑な話題に対する質問に答えることができます。以下の動画では、人が動作を見せるとそれに沿ってその動作を理解し、説明しています。
Geminiは3つのバージョンがあり、規模が大きいほうから、Ultra>Pro>Nanoとなります。Gemini Proというとプレミアムな響きがしますが、Bardで無料で利用できるのも魅力的ですね。
Gemini Ultra — 非常に複雑なタスクに対応する、高性能かつ最大のモデルGemini Pro — 幅広いタスクに対応する最良のモデル
Gemini Nano — デバイス上のタスクに最も効率的なモデル
*引用
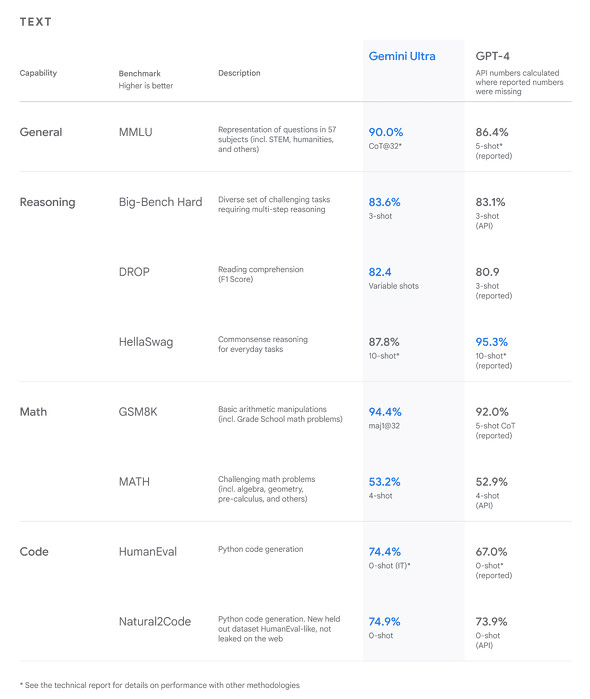
Gemini Ultraは「最も高性能なモード」で、テキスト、画像、音声、動画、コードなど多岐にわたる複雑なタスクを処理ができます。上位モデルの「Gemini Ultra」を使った場合、生成AIのモデルを評価するために使われているベンチマーク32種類のうち「30で既存の最高水準の結果を上回っている」とのこと。
数学、物理学、歴史、法律、医学、倫理など57の科目の組み合わせて知識と問題解決能力をテストするMMLU(大規模マルチタスク言語理解)では、90.00%のスコアで、人間の専門家を上回るパフォーマンスを示した初のモデルとなります。
Gemini Proは今後検索サービスや広告、Chrome、Duet AIなど、幅広く展開していくみたいです。
スマートフォンの機能の一部として設計された小型版のAIモデルはGemini
Nanoと呼ばれ、現在Pixel 8 Proに搭載されているみたいです。
現在もPixelシリーズには独自のオンデバイスAIが搭載されていますが、今回ボイスレコーダーに搭載された「音声文字起こし」機能では、オンデバイスAIを使って通信をせずに文字起こしをすることができるようになり、要約もできるようになるみたいです。WhatsApp から始まる Gboard のスマート リプライも展開され、来年にはさらに多くのメッセージング アプリに対応することが出来るようになるでしょう(日本語対応は未定)。

BardでGeminiを使用するには、ブラウザからウェブサイトにアクセスし、ログインするだけです。
実際に機能する場合、グーグルのほかのサービスと統合できる点がBardの強みの一つといえます。例えば、Gmailと連携させてチャットボットに毎日メールを要約させたり、YouTubeと連携させてあるトピックの動画を探させたりすることができます。
Googleは、AIの責任ある進歩に焦点を当てており、Geminiモデルにマルチモーダル機能の保護を加え、安全ポリシーを強化しています。開発の各段階でリスクを評価し、テストと軽減に努めています。バイアスと有害性の包括的な評価を含む安全性チェック、敵対的テスト技術の応用、外部の専門家との協力によるモデルのストレステストが行われており、安全分類子とフィルターにより安全で包括的なモデルを目指しています。また、Googleは業界と連携し、セキュリティリスクを軽減するベストプラクティスを確立しています。
Googleによると、「これは、創造性を高め、知識を拡張し、科学を進歩させ、生活と働き方を変革するイノベーションの未来」が待っているそうなので今後のリリースにも期待大です!
この記事が気に入ったらサポートをしてみませんか?