同じデータでもP値が変わる話

こんにちは。コグラフ株式会社データアナリティクス事業部の塩見です。
統計的仮説検定を行うと、同じデータからは同じ検定結果が得られるものだと思っていませんか。そのように考えたくなりますが、実際には必ずしもその通りではありません。
例えば、コイン投げをして24回中7回が表になるという単純なデータを考えてみましょう。このようなデータでも、実験の設定や投げる回数の制約によって、統計的仮説検定の結果が変わることがあるのです。Pythonで計算しながら説明します。
統計的仮説検定の流れ
統計的仮説検定の大まかな流れを順番に説明します。
帰無仮説をたてる
標本分布を計算する
データを観測してP値を求める
P値で判断
帰無仮説をたてる
ある統計量がある値と等しいということを帰無仮説として設定します。
例)
コインの裏表が出る確率が50%と等しい
二群の平均値が等しい
標本分布を計算する
帰無仮説が成り立つ場合に、その統計量が従うであろう確率分布(標本分布)を計算します。
例)
コインの裏表が出る確率→二項分布など
平均値→t分布など
データを観測してP値を求める
実際に観測された値、もしくはそれよりも極端な値が標本分布に占める面積、つまりそのような値が観測される確率(P値)を求めます。
P値で判断
P値があらかじめ設定したしきい値(たとえば5%)よりも小さければ、そもそも帰無仮説が間違っていたのだと結論づけます。逆に小さくなければ帰無仮説を棄却せず、判断を保留します。
コイン投げの例
例えば、コイン投げをして24回中7回が表になったという単純なデータを考えてみましょう。このコインは公平といえるのでしょうか。検定を行って確かめてみます。
ここで、データ観測者の意図を考えます。ある観測者は、最初からコインを24回投げると決めていました。そして、結果として7回表がでました。一方、別の観測者は、7回表が出るまでコインを投げ続けるぞと決めていました。そして、結果として24回投げました。
このように、観測者の意図が異なる状況を設定して、統計的仮説検定を行ってみましょう。
24回投げると決めていて、結果として7回表が出た
帰無仮説:このコインは公平である
表が出る確率 $${\theta}$$
コインを投げる回数 $${N}$$
表が出た回数 $${z}$$
とすると、標本分布は以下の二項分布に従います。
$$
p(z|N,\theta)=\dbinom{N}{z}\theta^z(1-\theta)^{N-z}
$$
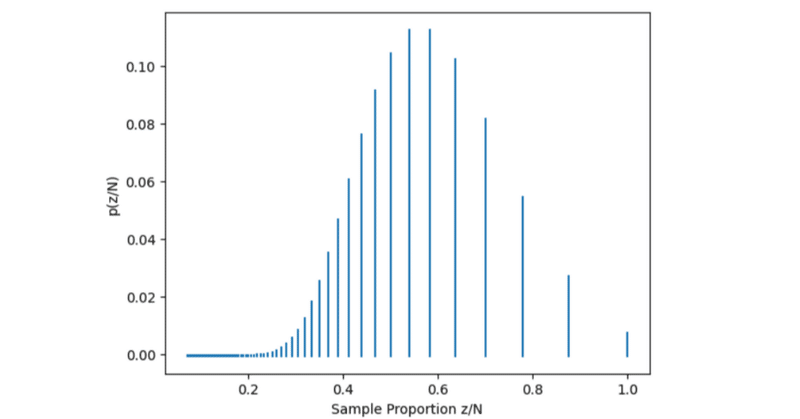
$${\theta=0.5, N=24}$$の標本分布をPythonで描くと、このような形をしています。

# 標本分布(24回投げると決めていて、結果として7回表が出た)を描画するPythonコード
from scipy import stats
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
theta = 0.5
N = 24
z = np.arange(N+1)
proportion = z / N
p = stats.binom.pmf(z, N, theta)
df = pd.DataFrame({'z':z, 'proportion':proportion, 'p':p})
plt.vlines(df['proportion'], -0.001, df['p']) # df['p']の値が小さい場所でもグラフが見えるよう-0.001から描いています。
plt.xlabel('Sample Proportion z/N')
plt.ylabel('p(z/N)')
plt.show()準備ができました。それではデータの観測値、もしくはそれよりも極端な値が標本分布に占める面積、つまりそのような値が観測される確率(P値)を求めましょう。以下のPythonコードでP値は0.064と求めることができます。
# P値を計算
sum(df['p'][df['p'] <= df['p'][df['z']==7].iat[0]])
# 結果 0.06391465663909919上記のP値計算を図で説明すると、赤い四角形で囲んだ範囲の確率の合計を求めています。z=7という観測値、もしくはそれよりも極端な値が標本分布に占める面積(確率)を求めたわけです。

さて、P値は0.064でした。あらかじめP値のしきい値を0.05と決めていた場合、帰無仮説「このコインは公平である」を棄却することはできません。判断を保留します。
7回表が出るまで投げ続けると決めていて、結果として24回投げた
この場合「23回投げた時点で6回表が出ており、24回目では表が出た」という状況だと言い換えることができます。先ほど「N回投げると決めていて、結果としてz回表が出た」という意図で標本分布は、以下の二項分布に従っていました。
$$
p(z|N,\theta)=\dbinom{N}{z}\theta^z(1-\theta)^{N-z}
$$
「N-1回投げた時点でz-1回表が出ており、N回目は表が出た」という状況の標本分布は以下のようになります。
$$
p(N|z,\theta)=\dbinom{N-1}{z-1}\theta^{z-1}(1-\theta)^{N-z}\cdot\theta
$$
この式を詳しく説明すると、右辺の前半
$$
\dbinom{N-1}{z-1}\theta^{z-1}(1-\theta)^{N-z}
$$
は、N-1回投げた時点でz-1回表が出たという状況を表現しています。そして後半の$${\cdot\theta}$$がN回目は表だったことを表現しているのです。続けて標本分布の式を変形していきます。$${\cdot\theta}$$を適用するとこのようになります。
$$
p(N|z,\theta)=\dbinom{N-1}{z-1}\theta^{z}(1-\theta)^{N-z}
$$
$${\binom{N-1}{z-1}}$$について簡単な計算を行うとこのようになります。
$$
p(N|z,\theta)=\dfrac{z}{N}\dbinom{N}{z}\theta^{z}(1-\theta)^{N-z}
$$
標本分布としてこの式を使うことにしましょう。
帰無仮説:このコインは公平である
$${\theta=0.5, z=7}$$の標本分布をPythonで描くと、このような形をしています。

# 標本分布(7回表が出るまで投げ続けると決めていて、結果として24回投げた)を描画するPythonコード
from scipy import stats
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
theta = 0.5
z = 7
N = np.arange(z, 100) # 100は十分大きい値という意味
proportion = z / N
p = stats.binom.pmf(z, N, theta) * z / N
df = pd.DataFrame({'N':N, 'proportion':proportion, 'p':p})
plt.vlines(df['proportion'], -0.001, df['p']) # df['p']の値が小さい場所でもグラフが見えるよう-0.001から描いています。
plt.xlabel('Sample Proportion z/N')
plt.ylabel('p(z/N)')
plt.show()データの観測値、もしくはそれよりも極端な値が標本分布に占める面積、つまりそのような値が観測される確率(P値)を求めましょう。以下のPythonコードでP値は0.017と求めることができます。
# P値を計算
sum(df['p'][df['p'] <= df['p'][df['N']==24].iat[0]])
# 結果 0.01734483242034913上記のP値計算を図で説明すると、赤い四角形で囲んだ範囲の確率の合計を求めています。N=24における観測値、もしくはそれよりも極端な値が標本分布に占める面積(確率)を求めたわけです。

さて、P値は0.017でした。あらかじめP値のしきい値を0.05と決めていた場合、帰無仮説「このコインは公平である」は棄却されます。
観測者の意図によって検定結果が変わってしまう
このコインは公平であるという帰無仮説のもとで、コインを24回投げて7回表が出たという観測データが得られました。
コインを投げる回数を24回と固定する意図ではP値=0.064となり、帰無仮説を棄却できず、判断を保留しました。
一方、表が出る回数を7回と固定する意図ではP値=0.017となり、帰無仮説を棄却しました。
なんと、同じデータを観測したにもかかわらず、観測者の意図によって検定結果が変わるのです。意外にも、観測者の意図やデータ収集の方法が、統計的仮説検定の結果に影響を与える可能性があるのです。このような現象は、統計的仮説検定の限界や留意すべき要点を浮き彫りにします。単に数値をみるだけではなく、実験の文脈や条件を正しく理解することの重要性を示しているのです。
参考文献
飯塚修平. ウェブ最適化ではじめる機械学習. オライリー・ジャパン, 2020
John K. Kruschke. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan EDITION 2. Academic Press, 2014
データ分析に興味のある方募集中!
コグラフ株式会社データアナリティクス事業部ではPythonやSQLの研修を行った後、実務に着手します。
研修内容の充実はもちろん、経験者に相談できる環境が備わっています。
このようにコグラフの研修には、実務を想定し着実にスキルアップを目指す環境があります。
興味がある方は、下記リンクよりお問い合わせください。

X(Twitter)もやってます!
コグラフデータ事業部ではTwitterでも情報を発信しています。
データ分析に興味がある、データアナリストになりたい人など、ぜひフォローお願いします!
📢Wantedly新掲載!
— アラリコ@コグラフ株式会社 | データ事業部 (@CographData) July 14, 2023
「データに興味がある」
「データに携わる仕事がしたい」
そこのあなた!
私たちと一緒にデータ分析しませんか?
IT業界未経験の方も大歓迎です☺️#エンジニア転職 #データ分析 #駆け出しエンジニアと繋がりたいhttps://t.co/S9o7VSjGRt
この記事が気に入ったらサポートをしてみませんか?