
Trying Data Science(12) : 決定木とランダムフォレストで返済予測

1.はじめに
今回は、貸出データを活用してランダムフォレスト(Random Forest)と決定木(Decision Tree)マシンラーニングモデルを学習し、これらのモデルを使って貸出償還可否を予測するプロジェクトを進めていきます。 ランダムフォレストと決定木は、ローンの債務返済予測にどのように活用されるかを詳しく見てみましょう。
2. 概念
2.1 決定木(Decision Tree)
「決定木」は、機械学習とデータマイニングの分野で使用される、意思決定のプロセスをツリー構造で表現するためのモデルやアルゴリズムの一つです。英語では「Decision Tree」とも呼ばれます。ツリーの根から始まり、各ノードで特定の条件に基づいて分岐し、最終的に葉ノードで意思決定を行います。
具体的な用途
分類(Classification)、回帰(Regression)、特徴量の選択(Feature Selection)などで利用されます。
特徴
直感的で理解しやすい反面、過学習(Overfitting)の傾向があるため、適切なハイパーパラメータの調整やプルーニングが必要です。また、データセットが小さくてもうまく機能することがあります。
2.2 ランダムフォレスト(Random Forest)
機械学習のアルゴリズムの一つで、高い予測性能と汎用性を持つ強力なモデルです。ランダムフォレストは、複数の決定木(Decision Tree)を組み合わせて、より正確で安定した予測を行うための手法です。
アンサンブル学習法
ランダムフォレストはアンサンブル学習法の一種です。アンサンブル学習は、複数のモデルを組み合わせて単一のモデルよりも優れた性能を実現しようとする手法です。ランダムフォレストでは、複数の決定木モデルを組み合わせて、より強力なモデルを構築します。
多数決(Majority Voting)
ランダムフォレストでは、複数の決定木が個別に予測を行います。そして、それぞれの決定木が予測した結果の多数決を行い、最終的な予測を決定します。この多数決により、モデルの安定性が向上します。
過学習(Overfitting)の軽減
ランダムな特徴選択とブートストラップ標本により、過学習のリスクが軽減されます。モデルは訓練データに対して適合しすぎず、一般化能力が向上します。
3.実習
3.0 csvファイルのコラム

credit.policy: クレジット引受基準を満たしている場合は 1、それ以外の場合は 0。
purpose: 融資の目的(「credit_card」、「debt_consolidation」、「educational」、「major_purchase」、「small_business」、および「all_other」の値を使用します)。
int.rate: ローンの利率は、割合として(11%の利率は0.11として保存されます)。 リスクが高いと判断された借り手には、より高い金利が割り当てられます。
installment: 借入者が融資を受けた場合に支払う毎月の分割払いです。
log.annual.inc: 借入人の自己申告年収の自然ログ。
dti:債務者の所得に対する負債比率(債務額を年間所得で割った値)。
fico: 借入者の「FICOクレジットスコア」。
***クレジットスコアは「FICOスコア」という手法で、300点から850点で採点をします。点数が低いほど信用力が低いとみなされる。***
days.with.cr.line: 借入人がクレジットラインを持っている日数です。
revol.bal: 借入人の回転残高(クレジットカードの請求サイクル終了時に未払額)。
revol.util: 借入者の回転利用率(利用可能なクレジット合計に対して使用されるクレジットラインの金額)。
inq.last.6mths: 過去6ヶ月間の債権者による借入人の照会数。
delinq.2yrs: 過去2年間に借入人が支払期限を30日以上経過した回数。
pub.rec: 貸主の軽蔑的な公的記録(破産申請、納税者、判決)の数。
3.1 データ取得
# 必要なライブラリをインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# データを読み込む
loans = pd.read_csv('loan_data.csv')3.2 データ探索
# データの概要を確認
loans.info()
# データの基本情報を表示
loans.describe()
# 数値データの統計情報を表示
loans.head()
# データの最初の5行を表示

3.3 データ視覚化
「FICOスコア」の分布を可視化
# データの可視化
plt.figure(figsize=(10,6))
loans[loans['credit.policy']==1]['fico'].hist(alpha=0.5,color='blue',
bins=30,label='Credit.Policy=1')
loans[loans['credit.policy']==0]['fico'].hist(alpha=0.5,color='red',
bins=30,label='Credit.Policy=0')
plt.legend()
plt.xlabel('FICO')
# 「FICOスコア」の分布を可視化します。
「FICOスコア」と「ローンの完済状況」の関係を可視化
plt.figure(figsize=(10,6))
loans[loans['not.fully.paid']==1]['fico'].hist(alpha=0.5,color='blue',
bins=30,label='not.fully.paid=1')
loans[loans['not.fully.paid']==0]['fico'].hist(alpha=0.5,color='red',
bins=30,label='not.fully.paid=0')
plt.legend()
plt.xlabel('FICO')
# 「FICOスコア」と「ローンの完済状況」の関係を可視化
「ローンの目的」ごとに完済状況をカウントプロットで可視化
plt.figure(figsize=(11,7))
sns.countplot(x='purpose',hue='not.fully.paid',data=loans,palette='Set1')
# 「ローンの目的」ごとに完済状況をカウントプロットで可視化
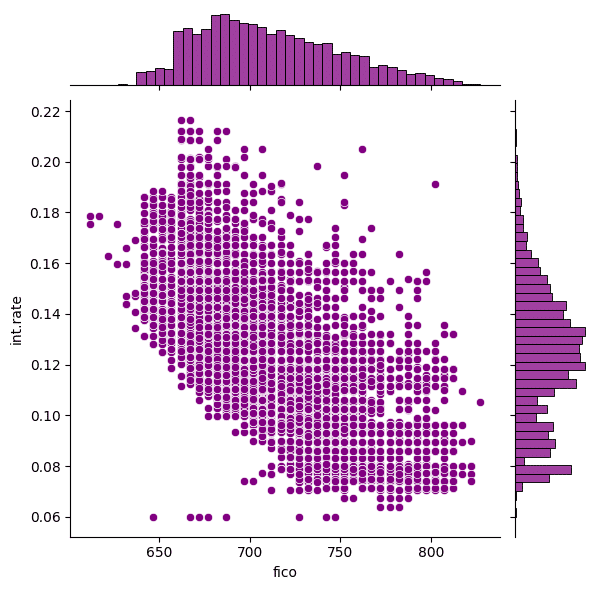
「FICOスコア」と「利子率」の関係をジョイントプロット可視化
sns.jointplot(x='fico',y='int.rate',data=loans,color='purple')
# 「FICOスコア」と「利子率」の関係をジョイントプロットで可視化
「FICOスコア」、「利子率」、「信用ポリシー」、「完済状況」の関係をlmplotで可視化
plt.figure(figsize=(11,7))
sns.lmplot(y='int.rate',x='fico',data=loans,hue='credit.policy',
col='not.fully.paid',palette='Set1')
# 「FICOスコア」、「利子率」、「信用ポリシー」、「完済状況」の関係をlmplotで可視化
lmplotは、SeabornというPythonのデータ可視化ライブラリを使用して、データセット内の2つの変数(数値データ)間の関係をグラフィカルに表示するためのプロットです。lmplotは線形回帰モデルのプロットを作成し、散布図と回帰直線を同時に表示します。
3.4 データの準備
ランダムフォレスト分類モデルのためのデータを設定する準備をします。
cat_feats = ['purpose'] # カテゴリカルな特徴量のリスト
final_data = pd.get_dummies(loans, columns=cat_feats, drop_first=True)
# カテゴリカルな特徴量をダミー変数に変換します。3.5 訓練データとテストデータの分割
from sklearn.model_selection import train_test_split
X = final_data.drop('not.fully.paid', axis=1)
y = final_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=101)
# データを訓練データとテストデータに分割します。3.6 決定木モデル訓練
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier()
dtree.fit(X_train, y_train)
3.7 決定木モデル評価
predictions = dtree.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(y_test, predictions))

このモデルはクラス0に関しては比較的高い適合率と再現率を持っており、クラス1に関しては非常に低い適合率と再現率を持っています。クラス1の予測性能が非常に低いため、モデル全体の性能も低くなっています。
重要な評価概念をまとめます。
適合率(Precision):モデルが陽性と予測したサンプルのうち、実際に陽性である割合を示し、モデルの正確性を表します。
再現率(Recall):モデルが実際の陽性サンプルのうち、陽性として正しく予測した割合で、モデルがどれだけ多くの陽性を見逃さなかったかを示します。
F1スコア(F1-Score):適合率と再現率の調和平均であり、モデルの精度と陽性予測の能力の両方を考慮した指標です。
正解率(Accuracy):全体のサンプルのうち、正しく予測した割合を示し、モデルの全体的な正確性を表します。
マクロ平均(Macro Avg):各クラス(ラベル)ごとに指標を個別に計算し、平均を取る方法で、クラス間の不均衡がある場合に使用します。
加重平均(Weighted Avg):各クラスに対する指標を、そのクラスのサンプル数(ウェイト)で加重平均して計算する方法で、クラス間の不均衡を考慮した平均です。
print(confusion_matrix(y_test, predictions))
正確に予測されたクラス0サンプルの数:1994
正確に予測されたクラス1サンプルの数:105
クラス0をクラス1と誤って分類したサンプルの数:338
クラス1をクラス0と誤って分類したサンプルの数:437
3.8 ランダムフォレストモデル訓練
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=600)
rfc.fit(X_train,y_train)
3.9 ランダムフォレストモデル評価
predictions = rfc.predict(X_test)
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test,predictions))
1クラスの再現率、f1-scoreが0クラスに比較的ひくいです。
print(confusion_matrix(y_test,predictions))
正確に予測されたクラス0サンプルの数:2422
正確に予測されたクラス1サンプルの数:7
クラス0をクラス1と誤って分類したサンプルの数:436
クラス1をクラス0と誤って分類したサンプルの数:9
3.10 モデル性能比較
1クラスの再現率(Recall)について、どちらもうまくいかなかったので、より多くの機能エンジニアリングが必要です。
4.まとめ
このプロジェクトでは、貸出データを用いて、ランダムフォレスト(Random Forest)と決定木(Decision Tree)という2つの機械学習モデルを訓練し、貸出償還の可否を予測しました。決定木は直感的で理解しやすいモデルであり、小規模なデータセットでもうまく機能することがあります。ランダムフォレストは複数の決定木を組み合わせて予測を行う強力なモデルであり、高い予測性能と汎用性を持っています。
正直に言うと、学習資料を真似してみるだけでもあまりにも難しかったです。 でもデータの視覚化と訓練予測と評価まで総合的に一つのプロジェクトを経験することができ、ますますデータ分析の流れに慣れてきているようです。 まだ十分ではありませんが、あと数回やればよくなるのではないかと思います!
エンジニアファーストの会社 株式会社CRE-CO
ソンさん
この記事が気に入ったらサポートをしてみませんか?