時系列予測で「人の噂は何日まで」か測る

「人の噂も七十五日」
......とはよく聞くけれど、本当にそうなのか気になってた。
時系列予測が気になる
前々から気になってた時系列予測をやってみたいと思った。
Facebookが作った時系列予測ライブラリを使えばと~っても簡単と聞いたのでやってみる。
でもただそれっぽい日付と紐づいたデータを用意して、
はい予測してみた~~~みたいなのはつまらないので、時系列予測を使って調べ物をしたいと思う。
人の噂は何日続くのか
「俳優の○○が覚せい剤をやってるらしい」
「△△という店で食中毒事故が起きたらしい」
「サッカー部の××に彼女が出来たらしい」
普段話題にすることはなかったのに
何かしら事件が起きるとつい話したくなってしまうのが噂というものだが
「人の噂も七十五日」というように長くは続かないらしい。
事件が起こるとゥワァーって話題になり、最近だとSNSのトレンドになったり、検索ランキングに乗ったりして、そのうち忘れられる。
時系列予測を使えば、
「もし事件が起こらなかった場合」の普段の話題量を再現することが出来るのではないか。
もっと言えば実際の世界で起きた事件後、噂によって一時増えた話題が
予測で再現した、事件がなかったはずの"普段の話題量"と一致するようになったとき、「噂が収束した」といえるのではないか。
つまり、実際に事件が起きた日から、噂が収束した日までの日数が
「人の噂もN日」になるのではないだろうか。
やるぞ~
アパマンショップ爆発事件
もう誰も覚えてないだろこれ。
Wikipedia「札幌不動産仲介店舗ガス爆発事故」
2018年12月16日20時29分頃、札幌市豊平区平岸の「アパマンショップ平岸駅前店」(運営はAPAMAN子会社の「アパマンショップリーシング北海道」)等が入居する木造2階建ての雑居ビル(酒井ビル)で爆発が発生。同店および隣接する居酒屋「北のさかな家 海さくら平岸店」が倒壊・炎上、52人が負傷した。北海道新聞の報道によれば、爆発音は15 km離れた江別市内でも聞こえたという。火災は翌17日2時10分に鎮火した。
アパマンショップに関する人々の関心度を毎日測ることのできるものとして、今回はGoogleの検索数を用いた。
Googleトレンドに検索ワード打ち込むだけで誰でも簡単に関心の推移をみることが出来る。
本当は噂の量=コミュニケーションの量、ということでTwitterのキーワード推移がいいかと思ったが、無料で使えるAPIでは30日分しか遡れないので断念。
アパマンショップといえば不動産仲介業。
当然一年ごとに就職進学など新生活準備による繁忙期があるため
予測のためには少なくとも一年以上の学習データを用意して繁忙期・閑散期の影響を考慮したい。ということで今回は過去5年分のGoogle検索トレンドを取得する。
注意したいのがこの検索トレンドは正規化された相対的な値であり、
検索数が最大だった日を100とした基準に基づいた値であることと、
9か月以上遡ったトレンド検索では値の計測単位が一週間ごとになってしまうという点。
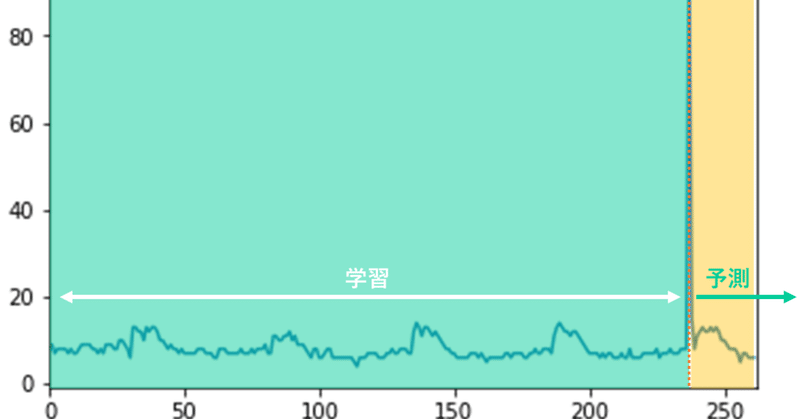
実際に横軸に時系列、縦軸にトレンドの値をとって
5年間をプロットするとこんな感じ。

とんがったやばいところ(=爆発事件が起こった時)より前を学習させて、
その後を予測させることで「爆発が起こらなかった世界」のアパマンショップのトレンド値を出す、というのが方針。

fbprophetでやってみる
◆すごいぞfbprophet
ProphetはFacebookが開発してリリースしている時系列予測ライブラリ。
以下の特徴を持っている。
・デフォルト設定でいい感じの予測を作成できる。
・ドメイン知識(周期性やトレンド、変化点の入力)によって精度が改善できる。
(・統一的な精度評価ができる。)
・これが難しいコーディングなしで実現できる。
誰でもProphet = 予言者 になれる!!!!!!!ウオオ!!!!!!!!
◆準備
データの入力、fbprophetでは独立変数を'ds'、従属(予測)変数を'y'で渡す必要があるので変換。
# 準備
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
from fbprophet import Prophet
# データ入力
# 学習用(爆発ナシ)
apaman_df = pd.read_csv("apamanshop_before.csv", dtype = None)
# 実測データ(爆発あった世界)
apaman_dfafter = pd.read_csv("apamanshop_after.csv", dtype = None)
# 変数変換
apaman_dftest = apaman_df.rename(columns={'date': 'ds', 'trends': 'y'})
apaman_dfafter2 = apaman_dfafter.rename(columns={'date': 'ds', 'trends': 'y'})◆学習させる
モデルでは時系列トレンドを線形(linear)として予測するか、非線形(logistic)として予測するかの設定する。
今回扱うトレンドデータは無限に伸びていったりしない非線形なので、growthにlogisticを指定する。
また、logisticを指定した場合、上限(キャパシティ)を指定する必要がある。
また曜日に依存するデータか、季節に依存するデータかをそれぞれ設定できる。今回は季節。
本当は変化点も指定できたりする。
本来なら株価情報や新聞記事に登場した日をここに入れるべきだろうが、
今回は週ごとのデータで日付を合わせられそうになかったのでスルー。
from fbprophet import Prophet
model = Prophet(growth='logistic', weekly_seasonality=False, yearly_seasonality=True)
apaman_dftest['cap'] = 100 # 上限の指定
fit = model.fit(apaman_dftest) # 学習(フィッティング)◆予測
# 予測はこんな感じで出せる
future = model.make_future_dataframe(periods=10)
future['cap'] = 100
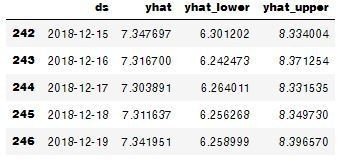
forecast = model.predict(future)
forecast[['ds','yhat','yhat_lower','yhat_upper']].tail()「爆発事故が起きなかった世界」の12/16(爆発日)を予測させるとこうなる。"yhat"というのが予測値。
グラフにプロットするとこうなる。

爆発がなければアパマンの2018-2019年末年始はこんなに静かなはずだったのだ。
今回は"季節に依存する"と指定したので季節の効果を見ることが出来る。

年末から1月にかけて検索数が増えて、春先まで高い水準であることがわかる。
「現実世界」と「アパマン爆発がなかった世界」はいつ交わるのか
ようやく本題がわかる。上述のように、
爆発事件後噂によって一時増えた話題が
予測で再現した、
爆発事件がなかったはずの"普段の話題量"と一致するようになったとき、「噂が収束した」ことになる。
実際のトレンドデータと予測トレンドデータを同時にプロットするとこうなる。
青: 実際データ
橙: 予測データ

2018年末の爆発による急増は当然当てられないが、
その後年明けあたりで予測が当たるようになっている。
拡大すると、

2018/12/25から2019/01/01の間にはすでに噂は収束し、いつも通りになっている。12/16に起きた爆発事故の噂は持って二週間程度ということがわかる。
9ヶ月分なら毎日のデータが取れるので、
それを用いて同様の予測を行っても

2018/12/30に予測と実際のデータが一致することわかる。
「人の噂は14日」なのだ。
以上簡単に「人の噂は何日か」を求めてみた。
Facebook Prophetは本当に簡単で自分がデータサイエンティストになったような気分になってしまった。
それよりも、もう忘れられてる事件を探すほうが時間かかったわ。
みんな清原とかピエール瀧のこと薬物話が出るたびにネタにしすぎだろぜんぜん収束しないじゃん。JUDGE EYESは友人に触らせてもらったけどめちゃ面白かった。
本来なら学習させるデータを訓練データとテストデータに分けて、
その予測が本当に精度のあるもっともらしいものなのか評価する必要がありそうだけど面倒だったので次の機会に。
天気や株価・ニュースの影響も入れてみたいので、次回はもっと粒度の細かいデータでやってみたい。
この記事が気に入ったらサポートをしてみませんか?