kaggleの地震コンペで3位になりました

kaggleで1月11日から6月4日にかけて行われていた「地震コンペ」に参加し、3位という成果を残すことができました。
この記事では、コンペの概要、参加の流れ、ソリューションについてまとめたいと思います。
地震コンペ、来たー!!!!!! pic.twitter.com/1hDyR5HsHH
— カレー🍛専業kaggler (@currypurin) June 4, 2019
この記事をもとに生放送で説明をしますした。良ければ視聴ください。
— regonn&curry.fm@ポッドキャストやっています (@regonn_curry) June 7, 2019
コンペの概要
実験室で、地震を起こした際の波形データが与えれ、何秒後に地震が発生するかを予想するコンペになっています。
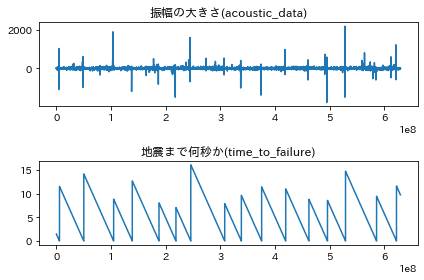
具体的なデータはこのようなデータ。

1列目が振幅の大きさ、2列目が地震まで何秒かということを表しています。
トレーニングデータは、629,145,480行 x 2列、
テストデータは、150,000行のデータが2624個あり、そのそれぞれが地震発生まで何秒のデータかということを予測し提出します。
トレーニングデータ全部をplotすると次の図
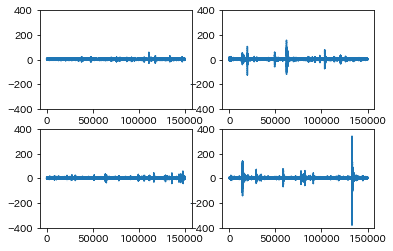
テストデータの4つをplotしてみると次の図になります。
トレーニングデータの下段をみるとわかるように、0秒に16回到達しており、地震が16回発生していることがわかります。
また、はじめと終わりにも、地震データがあるため、全部で18回の地震のデータであるということがわかります。
テストデータの図からは、たまに大きくなっている箇所があるということと、このデータからなん秒後に地震が発生するかを予測するのは難しいのではないかという印象を受けます。
リーダーボード(順位表)の流れなど
このコンペは開催期間が約5ヶ月ととても長期間にわたるコンペでした。(Kaggleのコンペは2ヶ月から3ヶ月くらいの開催期間のものが多いので、kaggleのコンペの中でも、とても長い部類です)
私は、技術書典6でKaggleのチュートリアルを頒布してからの参加だったので、4月下旬からの参加と、約40日ぐらいの参加期間でした。
5月1日ごろには、チームメイトのhmdhmdさんと、牡蠣を食べにいって、お互い地震コンペで良い順位になったら、チームマージしようと誓い合う。
結果的に考えると、ここでhmdhmdさんに地震コンペに参加してもらえたのが1番のファインプレー。後でチームマージして情報交換する際に、全く参考になる情報がないのも嫌なので、実験管理もちゃんとするようになりました。
からの、牡蠣三昧。
— カレー🍛専業kaggler (@currypurin) May 1, 2019
めっちゃ、美味しい。 pic.twitter.com/JOxMcmQ0d2
5月下旬はまだリーダーボードを追いかけていた時期。ひたすら特徴を作って、スコアが上がることを楽しんでいました。
地震コンペ久しぶりにスコア上がった!
— カレー🍛専業kaggler (@currypurin) May 19, 2019
MKさんと同スコアだった。 pic.twitter.com/XofVDneCJk
周りが軒並みスコアを上げている。
— カレー🍛 (@currypurin) May 23, 2019
プライベート気になるなー pic.twitter.com/WAfTG2IR2t
自分のマシンだけだと特徴が作りきれなくて、GCP(googleのクラウド)にも手を出したりした。
これまで細々とローカルとkernelでやっていたんだけれど、ついにGCP課金してしまった。
— カレー🍛 (@currypurin) May 24, 2019
5月26日ついにhmdhmdさんとチームマージ。この日までは一人でもくもくとやっていたので、チームマージして議論することができることにより、ものすごい進捗が生まれる。コンペ後にhmdhmdさんが言っている文殊の知恵というのはまさにそう。
hmdhmdさんとチームマージした!
— カレー🍛専業kaggler (@currypurin) May 26, 2019
ここからが勝負!! pic.twitter.com/GR8wcXE6Eg
ありがとうございました!
— hmdhmd (@hmd_kaggle) June 4, 2019
カレーさんがいなかったら、途中でコンペを辞めていたと思います
二人寄っても文殊の知恵!
5月28日頃、ディスカッションでtestデータについて議論されていることが重要なことに気づき、testデータにfittingしていかないといけないことに気づく

また、このディスカッションは、オールゼロから、オール12のサブミットなどを行い、testの最大値が9以上10未満、平均値が4.017ということなどを解き明かしているディスカッション。
平均4.017というのは、ランダムにサンプリングしてきた値としては小さいので、testデータはおそらく連続した1部分を切り取ったのではないかという予測がされている。
MAE(mean absolute error)という評価指標は、正解と予測の差の合計の平均なので、このようにLB Probingされやすい指標。
また、このディスカッションなどではトレーニングデータとテストデータが、p4677実験番号の地震から作成されたデータなのではないかという推測がされている。
この仮説について、5月28日ごろから検証の実験などを行い、その場合にどのように、サブミットファイルを作っていけば良いか議論と検証を行い、やり切ることができました!
地震コンペやりきった!!
— カレー🍛専業kaggler (@currypurin) June 3, 2019
めちゃくちゃ色々考えたコンペだった! pic.twitter.com/7qtanykAVd
ソリューション
ソリューションについては、twitterに書いたので、それを埋め込みます。
足りないところだけ少し補います。
地震コンペの3位のsolutionまとめ。
— カレー🍛専業kaggler (@currypurin) June 4, 2019
・このコンペは、testにある約0.036秒間の波形データを見て、何秒後に地震が発生するを予測するコンペ
・ディスカッションで、p4677という実験noの地震データということは予想されていたので、それをどう活用するかが勝負のコンペ。https://t.co/t6Y6Cbxt4I
・p4677の論文ではこのような図があり、trainはだいたい紫の部分のデータ+黄緑の最初の少しだけということがわかる。
— カレー🍛専業kaggler (@currypurin) June 4, 2019
・とすると、testは黄緑の部分ということが予想される
・検証のためにtrainを分割して、予想したいデータの形がわかったとして、精度よく当てられるか検証するも自分の特徴では無理 pic.twitter.com/Qt0J0oKTSA
・もう一度この図を見ると、論文執筆者もTime to failure(地震までの時間で一番下)はあまり当てられていないが、 Time sinse failure(地震発生後何秒かで真ん中)は精度よく当てることができている
— カレー🍛専業kaggler (@currypurin) June 4, 2019
・自分の特徴で試すと、同じ傾向で、かなり良い精度で推測することができる。 pic.twitter.com/n9xJJw6QTC
testの形がわかりtest(この図の黄緑の部分)は、最大で10sぐらいのデータが多く、また地震発生後何秒かということを精度よく当てられるのであれば、地震発生直後であれば10s、地震発生1秒後は9sのように予測を行えば良い予測となるのではという発送で次のように、トレーニングデータのyを修正してしまうことにしている。
・yを修正して学習・推論することにする
— カレー🍛専業kaggler (@currypurin) June 4, 2019
・yの修正の仕方は複数試したけれど、次のやり方が一番cvがよかった。理論的にはこれがbestとは思わないしなぜかは不明。
・testで一番MAEが最小になる値を求める。(高さが0と結んだ時に最小となるbを求める) pic.twitter.com/xK2ioaAihZ
上記のcvというのは正確じゃなくて、
1つめ〜4つめの地震が検証データで、残りがtrainデータ。
5つめ〜8つめの地震が検証データで、残りがtrainデータ。
12個め〜15個目の地震が検証データで、残りがtrainデータ。
というように学習・推論してのスコアが良かったと言う意味。
・trainのyを次の図のように修正する。地震直後をtestで求めたbにして、地震発生が0になるようにする。
— カレー🍛専業kaggler (@currypurin) June 4, 2019
・あとはこれを、Kernel等にあるようにlgb等で学習・推論。特に後処理等はなし。 pic.twitter.com/XSMg59qmNv
・この方法は、地震の発生までの時間を予測していないので、コンペの意義的には微妙かもしれない。
— カレー🍛専業kaggler (@currypurin) June 4, 2019
・ただ、この実験室地震は、徐々に力を加えいって、一定の力が加わった後は確率的に地震が発生するようなのと思われる。
ソリューションツイート終わり。
finalサブミットに選んだのは次の2つ。
パブリックLBは、1.6台とベストスコアより0.2以上悪いものを選択しています。
finalサブミット pic.twitter.com/OetdvLwIUE
— カレー🍛専業kaggler (@currypurin) June 4, 2019
最終モデルはLightGBMとRNN。LightGBMの特徴は、ほぼこのKernelとこのKernelを参考にして作成した特徴でした。
まとめと告知
最後はtwitterに書いたsolutionを貼っただけになってしまいましたが、ここまでにしたいと思います。
年内にKaggleグランドマスターを目指して、Kaggleに専念しており、残り金メダル3つ。長らく金メダルが取れていなくて、9ヶ月ぶりくらいに2つめを取ることができました。
去年の7月で仕事をやめてkaggleに取り組んで、8月にSantanderでパズルを解いて金メダルとるも、その後は結果が出ず。
— カレー🍛専業kaggler (@currypurin) June 4, 2019
この6月についに2つめの金メダル。
残り半年で金メダル3個は難しい目標だけれど、年内GM目指してやっていきます!
質問があれば、質問箱までお願いします。
個人的に驚いたこと
同じ時期にサンリオのキャラクター大賞が行われていて、なんと地震コンペの結果発表と、キャラクター大賞の結果発表は同じ日!
そして、私の大好きなポムポムプリンが、同じ3位という順位で終わっていました!
プリンも3位という偶然、なんか言葉にできない思いだけど、一生忘れないな。 https://t.co/fiK4ApcCzk
— カレー🍛専業kaggler (@currypurin) June 5, 2019
プリンは何度も1位になったことがあるので、本当は3位じゃ全然喜べないんですけどね。。。
プリンも前日の夜は100%目がさえて寝れていませんでした。
100%、目がさえてる・・・! pic.twitter.com/ScnM7eoNoM
— ポムポムプリン【公式】 (@purin_sanrio) June 3, 2019
100%目がさえてる。確かに。
— カレー🍛専業kaggler (@currypurin) June 3, 2019
コメントお待ちしています。匿名の質問はマシュマロから→https://marshmallow-qa.com/currypurin