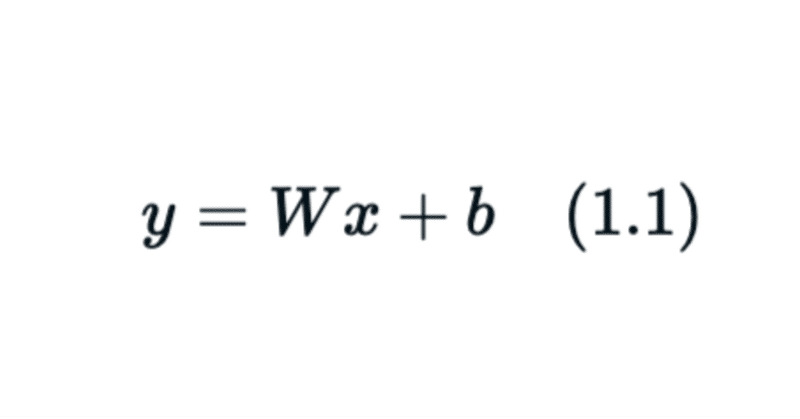
小話: 機械学習系の論文実装で気をつけて読むべきほぼ唯一の箇所, 行列演算

この記事は3分程度で読み終わる小話になっています。
この記事の対象者
・何でもかんでもフルスクラッチで一度は論文実装しなければ気が済まない人
Qiitaにも投げようかと思いましたが, Qiitaは実装の話をする場なのでNoteに投稿しました。
と言っておきながら, 実は過去にQiitaに数学の話を投稿してしまっています。いいねとブクマお願いします。
本題
まずは簡単な線形層を考えていきましょう。$${x \in \mathbb{R}^{n}, W \in M_{m \times n}, b \in \mathbb{R}^{m}, y \in \mathbb{R}^{m}}$$とする時, n次元ベクトルをm次元ベクトルに射影する線形層(実はアフィン変換)は,
$${y = Wx + b (1.1)}$$
と書くことができます。
ここまでは良いです。何回も見たことがある人は多いかと思います。しかし, 実装の際は少し都合がことなります。ここでpytorchの公式ドキュメントなどを見てみましょう。彼らの実装では, こんな式が出てきます。(あとで文字の混同を避けるため, ここでは一部の文字をリンク先から変更しています。)
$${Y = XW^{T} + b^T (1.2)}$$
なんだか式が倒置されている部分があります。これはどういうことなのでしょうか
解答
答えはもちろん意図的に文字を変えたように, $${x, y, X, Y}$$はそれぞれ定義が違うことからきています。
式1.1は$${\mathbb{R}^{n}}$$の入力に対して$${\mathbb{R}^{m}}$$を返す変換です。しかし, 式1.2はd個のデータに対しての変換であり, $${X, Y}$$は計画行列です。それぞれの計画行列$${X \in M_{d \times n}, Y \in M_{d \times m}}$$を考えると$${M_{d \times n}}$$の入力に対して$${M_{d \times m}}$$を返す変換になっています。
この計画行列の定義の仕方が式の違いを生み出しています。自分でコードを書くときに, 意識せずに行はデータ数, 列はそれぞれのデータの特徴量といった感じで計画行列を定義していると思います。
式1.1は言うまでもなくあるデータ一つに対しての変換を意味します。これを$${i}$$番目のデータの特徴量ベクトルに対する変換だとして, 明示的に式1.3のように書きましょう。
$${y_i = Wx_i + b (1.3)}$$
そして, $${i}$$番目のデータ特徴量ベクトルを$${x_i}$$とするとき, 行はデータ数, 列はそれぞれのデータの特徴量とすると, 計画行列$${X}$$は
$${X = \begin{bmatrix}x_{1}^{T}\\x_{2}^{T}\\x_{3}^{T}\\\vdots\\x_{d}^{T}\end{bmatrix}}$$
として定義されます。同様にして, 出力される計画行列$${Y}$$は以下のようになります。
$${Y = \begin{bmatrix}y_{1}^{T}\\y_{2}^{T}\\y_{3}^{T}\\\vdots\\y_{d}^{T}\end{bmatrix}}$$
式1.3の倒置をとりましょう。
$${y_{i}^{T} = x_{i}^{T}W^{T} + b^{T} (1.4)}$$
式(1.4)の$${y_{i}^{T} = x_{i}^{T}W^{T}}$$の計算結果を縦に積み上げていきます。
もう少し,詳しく言うと式1.4をバイアス項の部分以外を縦に積み上げていきます。
すると, 式1.5となります。
$${\begin{bmatrix}y_{1}^{T}\\y_{2}^{T}\\y_{3}^{T}\\\vdots\\y_{d}^{T}\end{bmatrix} = \begin{bmatrix}x_{1}^{T}\\x_{2}^{T}\\x_{3}^{T}\\\vdots\\x_{d}^{T}\end{bmatrix}W^{T} + b^{T} (1.5)}$$
これは計画行列$${X, Y}$$の定義に照らし合わせると式1.2そのものになります。
このように, 機械学習の理論の本と実装の間にはここまでのような式変形が省略されています。Transformerで有名なScaled Dot Product Attentionの実装でもこの式変形に加えて, アインシュタインの縮約記法を使ったeinsumで効率の良い実装を行っています。ぜひここまでを読んだ方は論文の式変形を実装用に変形したものを紙に書き, 式変形と照らし合わせながら実装してみてください。
おまけ
$${Y = XW^{T} + b^T (1.2)}$$
って行列にベクトルが足し合わされてて気持ち悪くね?と思ったそこのあなたは勘がするどいです。機械学習系のPaperはPythonのnumpy, jax, tensorflow, pytorchのブロードキャスト機能を暗に含んだ式をよく書いてしまうことがあります。そのため, このような記法になっております。
この記事が気に入ったらサポートをしてみませんか?