
Pythonによるスクレイピング①入門編 ブログの記事をCSVにエクスポートする

***追記***
3つのチュートリアル¥6,940相当を、セット割¥4,980のプランを用意しました!集中的に勉強してみたい方は、こちらもおすすめです!
・Pythonによるスクレイピング超絶入門
・Pythonによるスクレイピング応用
・スクレイピングを利用したAIアプリ開発
********
こんにちは、Daiです。
スクレイピングマニュアルの希望があったので、作成しました。
このチュートリアルで完成するもの
今回は、環境構築一切不要でスクレイピングを学べるように解説します。このコンテンツでは実際に僕のブログの記事一覧ページをスクレイピングして、
・記事名
・その記事のURL
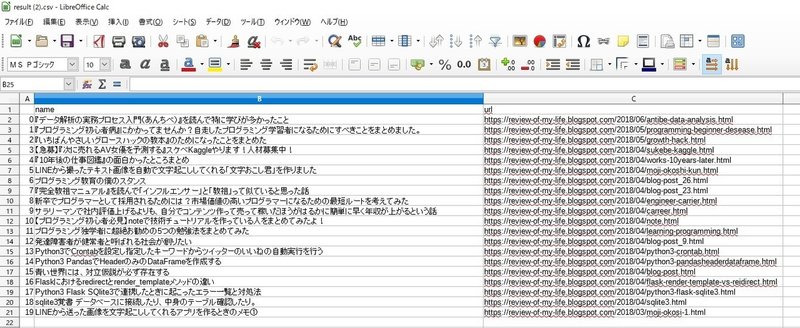
をcsvに出力して自分のPCにダウンロードするところまでを解説してみたいと思います。下図がダウンロードするCSVの例となります。
対象者
このチュートリアルの対象者は、こんな人です。
1. Pythonの基礎レベル. HTML, CSSのことが理解できている人
2. Pythonの基礎は分かるけど、実践的なことをやったことがないので、何かやってみたい人
3. データの自動収集に興味がある人
Pythonの基礎が理解できていない人はProgateを利用して、全コースクリアしておいてください。
学習内容
このチュートリアルでは、Pythonを利用して、以下のことを学びます。
・Google Colaboratory: Web上でPythonを実行できるツール
・pandas: 取得したデータをCSVに変換できるライブラリ
・BeautifulSoup: 取得したHTMLを操作できるライブラリ
・requests: Webからデータをダウンロードできるライブラリ
進め方
Google Colaboratoryを利用して、Colaboratory上で写経しながら進めていくのがよいでしょう。次のセクションでGoogle Colaboratoryの利用方法を説明します
更新:2019年6月10日
動画での解説も追加いたしました。ほかにもプログラミング学習系のコンテンツがあります。チャンネル登録はこちらから。
Google Colaboratoryを使えるようにしよう
それでは、さっそくはじめていきたいと思います。Pythonの実行環境を整えるのは、初学者だと大変面倒くさいです。
そこで最初に、WebでPythonが利用できるGoogle Colaboratoryを利用します。Google Colaboratoryは、Web上で3分でPythonの実行環境を用意できるツールです。Colaboratoryを利用すれば、初学者が折れてしまう環境構築を一切やらず、ネットさえつながっていればどこでもPythonの実行できるようになります。
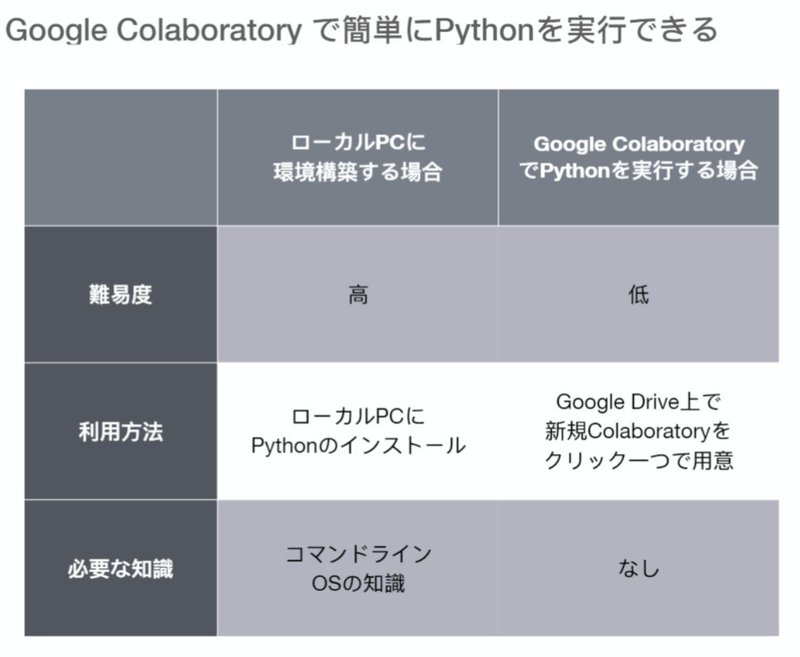
Google Colaboratoryについての設定は、以前書いたこの記事を参照してください。この記事の設定に従って進めると、2-3分ほどでWeb上でPythonが実行できるようになります。
Google ColaboratoryでHello Worldしてみよう
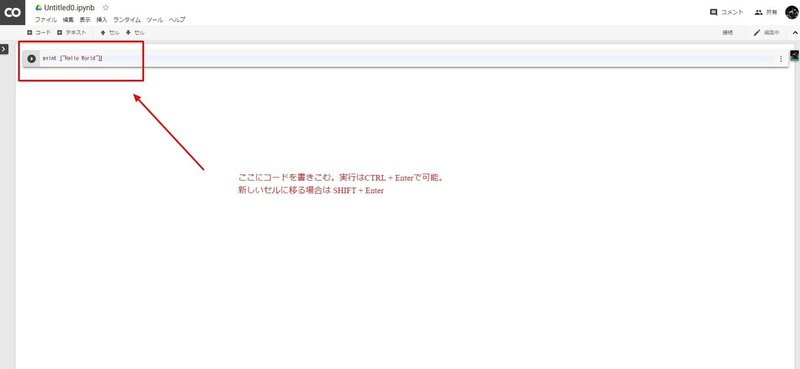
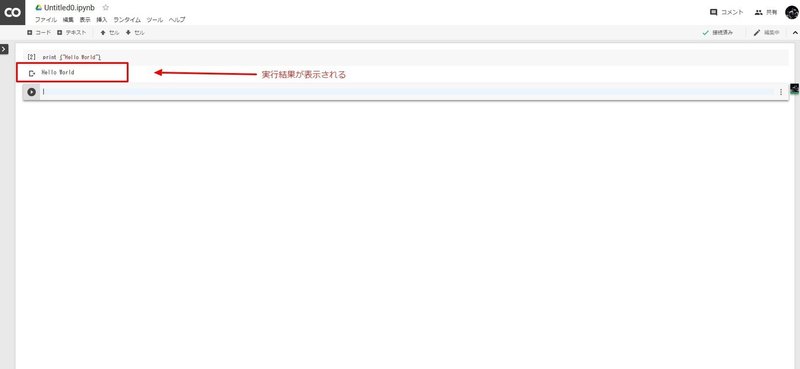
それでは、さっそくGoogle ColaboratoryでHello Worldしてみましょう。セルが表示されるので、
print ("Hello World")と入力し、CTRL + Enterで実行することができます。また、SHIFT + Enterで新しいセルを追加することができます。
スクレイピングしてみよう
さっそく、Web上からデータを取得する、スクレイピングをしてみます。今回利用するライブラリは、Requests, BeautifulSoup, Pandasです。

Requestsは、Web上のデータを取得できるライブラリです。BeautifulSoupは、取得したHTMLのデータを切り貼りできるライブラリです。そしてPandasは、取得したデータを行列で扱い、CSVにエクスポートができるライブラリとなります。
1. Beautiful Soup: 必要なモジュールをインストール
スクレイピングでHTMLを加工する際に利用するBeautifulsoupというモジュールをインポートします。 BeautifulSoupは、取得したHTMLのデータの中から、タグを読み取り、操作することができるライブラリです。
ドキュメンテーションはこちらになりますが、見なくてもこのチュートリアルを見るとわかるようになっています。まずはライブラリをインポートします。
# Beautiful Soupのインポート
from bs4 import BeautifulSoup2. BeautifulSoupの初期化
BeautifulSoupで、HTMLを読み込みます。本来は、外部サイトのHTMLを取得して、そのデータを受け取りますが、学習のため、こちらで用意したHTMLを利用してみたいと思います。
# こちらで用意したHTML
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# BeautifulSoupの初期化
soup = BeautifulSoup(html_doc, 'html.parser') # BeautifulSoupの初期化それでは、実際にこの中から、HTMLのデータを取得してみましょう。 print(soup.prettify())を利用すると、ぐちゃぐちゃしたHTMLをきれいにインデントしてくれます。さっそくやってみましょう。
print(soup.prettify()) # HTMLをインデントすることができます。実行すると、以下のようにインデントされて表示されます。こうすることで、HTMLの構造を直感的に理解しやすくできます。
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>3. BeautifulSoupでtitleを取得
BeautifulSoupを利用する方法はいたってシンプルです。
titleタグの内容を取りたい場合は、soup.titleで取得できます。
例: <title>The Dormouse's story</title>
titleタグの中身の文字だけを取りたい場合は、soup.title.stringで取得できます。
例:The Dormouse's story
さっそく試してみましょう。
TODO
1. <title>The Dormouse's story</title>を取得してprintしてください。
2. The Dormouse's story を取得してprintしてください
解答
soup.title でHTMLを取得できます。
soup.title.stringで中の文字列を取得できます。
# <title>The Dormouse's story</title>を取得してください。
print(soup.title)
# The Dormouse's story を取得してください。
print(soup.title.string)出力結果
<title>The Dormouse's story</title>
The Dormouse's story4. BeautifulSoupで複数のaタグを取得
では、今度は同じタグが複数存在する場合も見てみましょう。現状、aタグは3つあります。
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>これらのタグをすべて取りたいです。そこで、このaタグを取ろうとして、soup.aを試すと、最初の一つだけとることになり、すべてを取ることができません。
print(soup.a)実行結果:一つしかとれない
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>find_all メソッド
そこで、今回は複数のタグを取る find_all メソッドを利用して、複数タグを取得します。 soup.find_all('a')のように指定すると、リスト形式ですべてのaタグを取得することができます。
soup.find_all("a")実行結果:複数のaタグがリスト形式で返ってくる
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
それでは、取得したaタグのリンクを一つ一つ取り出してみましょう。リストの中から、一つ一つaタグを取得していきます。
TODO
1. for文を利用して、取得したaタグのHTMLを含む部分をprintしてください。
2. for文を利用して、取得したaタグのHTMLを含まない部分だけprintしてください。
ヒント
1. リスト形式のデータは、for 単数 in リスト 構文を利用して、一つひとつ取り出すことができます。
2. HTMLを含まない中身をとるものは、stringを利用するのでした。
解答
tags = soup.find_all("a")
# for文を利用して、取得したaタグのHTMLを含む部分をprintしてください。
print("1. ")
for tag in tags:
print (tag)
# for文を利用して、取得したaタグのHTMLを含む部分をprintしてください。
print("2. ")
for tag in tags:
print (tag.string)出力結果
1.
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
2.
Elsie
Lacie
Tillie5. BeautifulSoupでURLの取得
今度は、取得したaタグのhrefに当たる部分、つまりURLだけとりだしてみましょう。
soup.a.get("href")のように指定することで、URLを取得することができます。
soup.a.get("href")
出力結果
u'http://example.com/elsie'それでは、さきほど取得したaタグのすべてのURLをprintしてみましょう。
TODO
1. for文を利用して、aタグのURLをすべてprintしてください解答
# TODO1 for文を利用して、aタグのURLをすべてprintしてください
for link in tags:
print (link.get("href"))結果
http://example.com/elsie
http://example.com/lacie
http://example.com/tillie実際のサイトをスクレイピングしてみよう
それでは、実際のサイトをスクレイピングしてみましょう。これは僕のブログのURLとなります。 https://review-of-my-life.blogspot.com/
https://review-of-my-life.blogspot.com/
1. Requests: WebページのHTMLを取得しよう
このページから、記事のタイトルと、その記事のURLを取得してみましょう。実際にWebページからデータを取得するのは、requestsというライブラリを利用します。 requestsをimportします。requests.get(url)でurlのページの情報を取得し、textを実行するとHTMLの内容を取得することができます。
import requests
response = requests.get("https://review-of-my-life.blogspot.com/")
print (response.text)結果(一部省略)
<!DOCTYPE html>
<html class='v2' dir='ltr' xmlns='http://www.w3.org/1999/xhtml' xmlns:b='http://www.google.com/2005/gml/b' xmlns:data='http://www.google.com/2005/gml/data' xmlns:expr='http://www.google.com/2005/gml/expr'>
<head>
<link href='https://www.blogger.com/static/v1/widgets/2437439463-css_bundle_v2.css' rel='stylesheet' type='text/css'/>
<link href="//alexgorbatchev.com/pub/sh/current/styles/shCore.css" rel="stylesheet" type="text/css">
<link href="//alexgorbatchev.com/pub/sh/current/styles/shThemeDefault.css" rel="stylesheet" type="text/css">
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shCore.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushCpp.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushCSharp.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushCss.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushJava.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushJScript.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushPhp.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushPython.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushRuby.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushSql.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushVb.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushXml.js" type="text/javascript"></script>
<script src="//alexgorbatchev.com/pub/sh/current/scripts/shBrushPerl.js" type="text/javascript"></script>
<script language='javascript'>
/*
SyntaxHighlighter.config.bloggerMode = true;
SyntaxHighlighter.config.clipboardSwf = 'http://alexgorbatchev.com/pub/sh/current/scripts/clipboard.swf';
SyntaxHighlighter.all();
*/
</script>
<script async src="//pagead2.googlesyndication.com/pagead/js/adsbygoogle.js"></script>
<script>
(adsbygoogle = window.adsbygoogle || []).push({
google_ad_client: "ca-pub-1032252535131809",
enable_page_level_ads: true
});
</script>
<meta content='width=device-width, initial-scale=1.0' name='viewport'/>
<meta content='text/html; charset=UTF-8' http-equiv='Content-Type'/>
<meta content='blogger' name='generator'/>
<link href='https://review-of-my-life.blogspot.com/favicon.ico' rel='icon' type='image/x-icon'/>
<link href='https://review-of-my-life.blogspot.com/' rel='canonical'/>
<link rel="alternate" type="application/atom+xml" title="Review of My Life - Atom" href="https://review-of-my-life.blogspot.com/feeds/posts/default" />
<link rel="alternate" type="application/rss+xml" title="Review of My Life - RSS" href="https://review-of-my-life.blogspot.com/feeds/posts/default?alt=rss" />
<link rel="service.post" type="application/atom+xml" title="Review of My Life - Atom" href="https://www.blogger.com/feeds/2592581639714884938/posts/default" />
<link rel="me" href="https://plus.google.com/108212213124852595543" />
<link rel="openid.server" href="https://www.blogger.com/openid-server.g" />
<link rel="openid.delegate" href="https://review-of-my-life.blogspot.com/" />
<!--[if IE]><script type="text/javascript" src="https://www.blogger.com/static/v1/jsbin/3658603751-ieretrofit.js"></script>
<![endif]-->
<link href='https://plus.google.com/108212213124852595543' rel='publisher'/>
<meta content='趣味でRuby Python データアナリティクス・スクレイピングなどをやっています。' name='description'/>
<meta content='https://review-of-my-life.blogspot.com/' property='og:url'/>
<meta content='Review of My Life' property='og:title'/>
<meta content='趣味でRuby Python データアナリティクス・スクレイピングなどをやっています。' property='og:description'/>
<!--[if IE]> <script> (function() { var html5 = ("abbr,article,aside,audio,canvas,datalist,details," + "figure,footer,header,hgroup,mark,menu,meter,nav,output," + "progress,section,time,video").split(','); for (var i = 0; i < html5.length; i++) { document.createElement(html5[i]); } try { document.execCommand('BackgroundImageCache', false, true); } catch(e) {} })(); </script> <![endif]-->
<meta content='summary' name='twitter:card'/>
<meta content='@never_be_a_pm' name='twitter:site'/>
<meta content=' | Review of My Life' name='twitter:title'/>
<meta content='http://bloggerspice.appspot.com/postimage/https://review-of-my-life.blogspot.com/' name='twitter:image'/>
<meta content='趣味でRuby Python データアナリティクス・スクレイピングなどをやっています。' name='twitter:description'/>
<meta content='width=1100' name='viewport'/>
<meta content='text/html; charset=UTF-8' http-equiv='Content-Type'/>
<meta content='blogger' name='generator'/>
<link href='https://review-of-my-life.blogspot.com/favicon.ico' rel='icon' type='image/x-icon'/>
<link href='https://review-of-my-life.blogspot.com/' rel='canonical'/>
<link rel="alternate" type="application/atom+xml" title="Review of My Life - Atom" href="https://review-of-my-life.blogspot.com/feeds/posts/default" />
<link rel="alternate" type="application/rss+xml" title="Review of My Life - RSS" href="https://review-of-my-life.blogspot.com/feeds/posts/default?alt=rss" />
<link rel="service.post" type="application/atom+xml" title="Review of My Life - Atom" href="https://www.blogger.com/feeds/2592581639714884938/posts/default" />
<link rel="me" href="https://plus.google.com/108212213124852595543" />
<link rel="openid.server" href="https://www.blogger.com/openid-server.g" />
<link rel="openid.delegate" href="https://review-of-my-life.blogspot.com/" />
<!--[if IE]><script type="text/javascript" src="https://www.blogger.com/static/v1/jsbin/3658603751-ieretrofit.js"></script>
<![endif]-->
<link href='https://plus.google.com/108212213124852595543' rel='publisher'/>
<meta content='趣味でRuby Python データアナリティクス・スクレイピングなどをやっています。' name='description'/>
<meta content='https://review-of-my-life.blogspot.com/' property='og:url'/>
<meta content='Review of My Life' property='og:title'/>
<meta content='趣味でRuby Python データアナリティクス・スクレイピングなどをやっています。' property='og:description'/>
<!--[if IE]> <script> (function() { var html5 = ("abbr,article,aside,audio,canvas,datalist,details," + "figure,footer,header,hgroup,mark,menu,meter,nav,output," + "progress,section,time,video").split(','); for (var i = 0; i < html5.length; i++) { document.createElement(html5[i]); } try { document.execCommand('BackgroundImageCache', false, true); } catch(e) {} })(); </script> <![endif]-->
<!--ブログタイトル-->
<title>Review of My Life</title>
<!--TOPページのタイトル-->
<style type='text/css'>@font-face{font-family:'Vollkorn';font-style:normal;font-weight:400;src:local('Vollkorn Regular'),local('Vollkorn-Regular'),url(//fonts.gstatic.com/s/vollkorn/v8/0yb9GDoxxrvAnPhYGxkkaE0Urhg0xTY.woff2)format('woff2');unicode-range:U+0460-052F,U+1C80-1C88,U+20B4,U+2DE0-2DFF,U+A640-A69F,U+FE2E-FE2F;}@font-face{font-family:'Vollkorn';font-style:normal;font-weight:400;src:local('Vollkorn Regular'),local('Vollkorn-Regular'),url(//fonts.gstatic.com/s/vollkorn/v8/0yb9GDoxxrvAnPhYGxktaE0Urhg0xTY.woff2)format('woff2');unicode-range:U+0400-045F,U+0490-0491,U+04B0-04B1,U+2116;}@font-face{font-family:'Vollkorn';font-style:normal;font-weight:400;src:local('Vollkorn Regular'),local('Vollkorn-Regular'),url(//fonts.gstatic.com/s/vollkorn/v8/0yb9GDoxxrvAnPhYGxkqaE0Urhg0xTY.woff2)format('woff2');unicode-range:U+0370-03FF;}@font-face{font-family:'Vollkorn';font-style:normal;font-weight:400;src:local('Vollkorn Regular'),local('Vollkorn-Regular'),url(//fonts.gstatic.com/s/vollkorn/v8/0yb9GDoxxrvAnPhYGxkmaE0Urhg0xTY.woff2)format('woff2');unicode-range:U+0102-0103,U+0110-0111,U+1EA0-1EF9,U+20AB;}@font-face{font-family:'Vollkorn';font-style:normal;font-weight:400;src:local('Vollkorn Regular'),local('Vollkorn-Regular'),url(//fonts.gstatic.com/s/vollkorn/v8/0yb9GDoxxrvAnPhYGxknaE0Urhg0xTY.woff2)format('woff2');unicode-range:U+0100-024F,U+0259,U+1E00-1EFF,U+2020,U+20A0-20AB,U+20AD-20CF,U+2113,U+2C60-2C7F,U+A720-A7FF;}@font-face{font-family:'Vollkorn';font-style:normal;font-weight:400;src:local('Vollkorn Regular'),local('Vollkorn-Regular'),url(//fonts.gstatic.com/s/vollkorn/v8/0yb9GDoxxrvAnPhYGxkpaE0Urhg0.woff2)format('woff2');unicode-range:U+0000-00FF,U+0131,U+0152-0153,U+02BB-02BC,U+02C6,U+02DA,U+02DC,U+2000-206F,U+2074,U+20AC,U+2122,U+2191,U+2193,U+2212,U+2215,U+FEFF,U+FFFD;}</style>
<style id='page-skin-1' type='text/css'><!--
/*
-----------------------------------------------
Blogger Template Style
Name: Simple
Designer: Josh Peterson
URL: www.noaesthetic.com
----------------------------------------------- */
/* Variable definitions
====================
<Variable name="keycolor" description="Main Color" type="color" default="#66bbdd"/>
<Group description="Page Text" selector="body">
<Variable name="body.font" description="Font" type="font"
default="normal normal 12px Arial, Tahoma, Helvetica, FreeSans, sans-serif"/>
<Variable name="body.text.color" description="Text Color" type="color" default="#222222"/>
</Group>
<Group description="Backgrounds" selector=".body-fauxcolumns-outer">
<Variable name="body.background.color" description="Outer Background" type="color" default="#66bbdd"/>
<Variable name="content.background.color" description="Main Background" type="color" default="#ffffff"/>
<Variable name="header.background.color" description="Header Background" type="color" default="transparent"/>
</Group>
<Group description="Links" selector=".main-outer">
<Variable name="link.color" description="Link Color" type="color" default="#2288bb"/>
<Variable name="link.visited.color" description="Visited Color" type="color" default="#888888"/>
<Variable name="link.hover.color" description="Hover Color" type="color" default="#33aaff"/>
</Group>
<Group description="Blog Title" selector=".header h1">
<Variable name="header.font" description="Font" type="font"
default="normal normal 60px Arial, Tahoma, Helvetica, FreeSans, sans-serif"/>
<Variable name="header.text.color" description="Title Color" type="color" default="#3399bb" />
</Group>
<Group description="Blog Description" selector=".header .description">
<Variable name="description.text.color" description="Description Color" type="color"
default="#777777" />これでは何が何だかわからないので、soup.prettifyを利用してきれいにしてみましょう。
html_doc = requests.get("https://review-of-my-life.blogspot.com").text
soup = BeautifulSoup(html_doc, 'html.parser') # BeautifulSoupの初期化
print(soup.prettify())それでは、このページのリンクをすべて抜き出してみましょう。
TODO
1. このページのaタグをすべて抜き出してください。(HTMLの内容)
2. このページのaタグのテキストのみを抜き出してください
3. このページのaタグのURLのみを抜き出して下さい
解答
# TODO1 このページのaタグをすべて抜き出してください。(HTMLの内容)
real_page_tags = soup.find_all("a")
for tag in real_page_tags:
print(tag)
# TODO2 このページのaタグをすべて抜き出してください。(HTMLの内容)
for tag in real_page_tags:
print(tag.string)
# TODO3 このページのaタグをすべて抜き出してください。(HTMLの内容)
for tag in real_page_tags:
print(tag.get("href"))結果(一部省略)
<a href="http://24work.blogspot.com/" rel="dofollow" target="_blank" title="Drop Down Menus"><img alt="Drop Down Menus" border="0" src="https://bitly.com/24workpng1" style="position: fixed; bottom: 10%; right: 0%; top: 0px;"/></a>
<a href="http://24work.blogspot.com/" rel="dofollow" target="_blank" title="CSS Drop Down Menu"><img alt="CSS Drop Down Menu" border="0" src="https://bitly.com/24workpng1" style="position: fixed; bottom: 10%; right: 0%;"/></a>
<a href="http://24work.blogspot.com/" rel="dofollow" target="_blank" title="Pure CSS Dropdown Menu"><img alt="Pure CSS Dropdown Menu" border="0" src="https://bitly.com/24workpng1" style="position: fixed; bottom: 10%; left: 0%;"/></a>
<a href="index.html"><span></span></a>
<a href="#"><span>書評</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/書評%2F教育"><span>教育</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E6%9B%B8%E8%A9%95%2F%E5%BF%83%E7%90%86%E5%AD%A6"><span>心理学</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E6%9B%B8%E8%A9%95%2F%E7%A4%BE%E4%BC%9A%E5%AD%A6"><span>社会学</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E6%9B%B8%E8%A9%95%2F%E8%87%AA%E5%B7%B1%E5%95%93%E7%99%BA"><span>自己啓発</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/書評%2F技術"><span>技術書</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E6%9B%B8%E8%A9%95%2F%E3%83%A1%E3%83%87%E3%82%A3%E3%82%A2"><span>メディア</span></a>
<a href="#"><span>Python</span></a>
<a href="#"><span>環境構築</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/Python%2F%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0"><span>スクレイピング</span></a>
<a href="#"><span>API</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/Python%2F%E3%83%87%E3%83%BC%E3%82%BF%E5%87%A6%E7%90%86"><span>データ処理</span></a>
<a href="#"><span>定期実行</span></a>
<a href="#"><span>データビジュアライゼーション</span></a>
<a href="#"><span>統計</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/統計%2FR"><span>R</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E7%B5%B1%E8%A8%88%2FR"><span>Tableau</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E7%B5%B1%E8%A8%88%2F%E7%B5%B1%E8%A8%88%E5%AD%A6"><span>統計学</span></a>
<a href="#"><span>分析</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/データ分析%2F教育"><span>教育</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E3%83%87%E3%83%BC%E3%82%BF%E5%88%86%E6%9E%90%2F%E7%A4%BE%E4%BC%9A%E5%95%8F%E9%A1%8C"><span>社会問題</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E3%83%87%E3%83%BC%E3%82%BF%E5%88%86%E6%9E%90%2FIT"><span>IT</span></a>
<a href="#"><span>論文</span></a>
<a href="#"><span>教育学</span></a>
<a href="#"><span>経済学</span></a>
<a href="#"><span>考え</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/考えたこと%2Fキャリア・教育"><span>キャリア・教育</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/考えたこと%2F社会問題"><span>社会問題</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E8%80%83%E3%81%88%E3%81%9F%E3%81%93%E3%81%A8%2F%E3%83%A9%E3%82%A4%E3%83%95%E3%83%8F%E3%83%83%E3%82%AF"><span>ライフハック</span></a>
<a href="#"><span>ブログ</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/ブログ運営%2F結果報告"><span>結果報告</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E3%83%96%E3%83%AD%E3%82%B0%E9%81%8B%E5%96%B6%2F%E7%B5%90%E6%9E%9C%E5%A0%B1%E5%91%8A"><span>技術</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/%E3%83%96%E3%83%AD%E3%82%B0%E9%81%8B%E5%96%B6%2F%E5%AD%A6%E3%81%B3"><span>学び</span></a>
<a href="#"><span>ICU</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/ICU%2F%E5%8F%97%E9%A8%93%E7%94%9F%E3%82%80%E3%81%91"><span>受験生向け</span></a>
<a href="https://review-of-my-life.blogspot.jp/search/label/ICU%2F%E3%81%9D%E3%81%AE%E4%BB%96"><span>その他</span></a>
<a href="https://review-of-my-life.blogspot.jp/p/blog-page_14.html"><span>Contact</span></a>
<a class="quickedit" href="//www.blogger.com/rearrange?blogID=2592581639714884938&widgetType=HTML&widgetId=HTML1&action=editWidget&sectionId=crosscol" onclick='return _WidgetManager._PopupConfig(document.getElementById("HTML1"));' target="configHTML1" title="編集">
<img alt="" height="18" src="https://resources.blogblog.com/img/icon18_wrench_allbkg.png" width="18"/>
</a>2. 記事のHTMLタグを確認して、クラスで記事タイトルを取得しよう
僕のブログページ(https://review-of-my-life.blogspot.com)にアクセスすると、記事一覧が表示されます。この記事一覧の記事名と、URLをとりたいので、開発者ツールを利用してタグを見てみます。※開発者ツールの利用方法がわからない場合、Progateの開発者ツールのチュートリアルをよんでみてください。
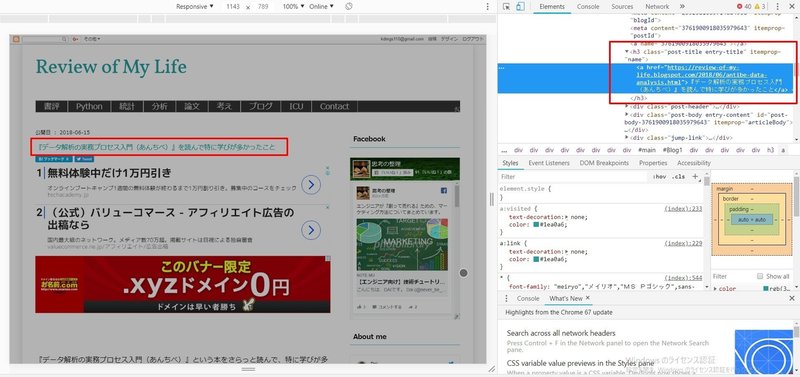
<h3 class="post-title entry-title" itemprop="name">
<a href="https://review-of-my-life.blogspot.com/2018/06/antibe-data-analysis.html">『データ解析の実務プロセス入門(あんちべ)』を読んで特に学びが多かったこと</a>
</h3>今度はClassを指定して、記事のタイトルのみを取得してみます。 find_allの引数に、辞書型でclassを指定することができます。 今回の場合だと、h3タグでclassがpost-titleのものを指定してみましょう。こうすると、記事一覧が取得できます。
soup.find_all("h3", {"class": "post-title"})結果
[<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/06/antibe-data-analysis.html">\u300e\u30c7\u30fc\u30bf\u89e3\u6790\u306e\u5b9f\u52d9\u30d7\u30ed\u30bb\u30b9\u5165\u9580\uff08\u3042\u3093\u3061\u3079\uff09\u300f\u3092\u8aad\u3093\u3067\u7279\u306b\u5b66\u3073\u304c\u591a\u304b\u3063\u305f\u3053\u3068</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/05/programming-beginner-desease.html">\u300e\u30d7\u30ed\u30b0\u30e9\u30df\u30f3\u30b0\u521d\u5fc3\u8005\u75c5\u300f\u306b\u304b\u304b\u3063\u3066\u307e\u305b\u3093\u304b\uff1f\u81ea\u8d70\u3057\u305f\u30d7\u30ed\u30b0\u30e9\u30df\u30f3\u30b0\u5b66\u7fd2\u8005\u306b\u306a\u308b\u305f\u3081\u306b\u3059\u3079\u304d\u3053\u3068\u3092\u307e\u3068\u3081\u307e\u3057\u305f\u3002</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/05/growth-hack.html">\u300e\u3044\u3061\u3070\u3093\u3084\u3055\u3057\u3044\u30b0\u30ed\u30fc\u30b9\u30cf\u30c3\u30af\u306e\u6559\u672c\u300f\u306e\u305f\u3081\u306b\u306a\u3063\u305f\u3053\u3068\u3092\u307e\u3068\u3081\u305f</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/sukebe-kaggle.html">\u3010\u6025\u52df\u3011\u300e\u6b21\u306b\u58f2\u308c\u308bAV\u5973\u512a\u3092\u4e88\u6e2c\u3059\u308b\u300f\u30b9\u30b1\u30d9Kaggle\u3084\u308a\u307e\u3059\uff01\u4eba\u6750\u52df\u96c6\u4e2d\uff01</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/works-10years-later.html">\u300e10\u5e74\u5f8c\u306e\u4ed5\u4e8b\u56f3\u9451\u300f\u306e\u9762\u767d\u304b\u3063\u305f\u3068\u3053\u308d\u307e\u3068\u3081</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/moji-okoshi-kun.html">LINE\u304b\u3089\u64ae\u3063\u305f\u30c6\u30ad\u30b9\u30c8\u753b\u50cf\u3092\u81ea\u52d5\u3067\u6587\u5b57\u8d77\u3053\u3057\u3057\u3066\u304f\u308c\u308b\u300c\u6587\u5b57\u304a\u3053\u3057\u541b\u300d\u3092\u4f5c\u308a\u307e\u3057\u305f</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/blog-post_26.html">\u30d7\u30ed\u30b0\u30e9\u30df\u30f3\u30b0\u6559\u80b2\u306e\u50d5\u306e\u30b9\u30bf\u30f3\u30b9</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/blog-post_23.html">\u300e\u5b8c\u5168\u6559\u7956\u30de\u30cb\u30e5\u30a2\u30eb\u300f\u3092\u8aad\u3093\u3067\u300c\u30a4\u30f3\u30d5\u30eb\u30a8\u30f3\u30b5\u30fc\u300d\u3068\u300c\u6559\u7956\u300d\u3063\u3066\u4f3c\u3066\u3044\u308b\u3068\u601d\u3063\u305f\u8a71</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/engineer-carrier.html">\u65b0\u5352\u3067\u30d7\u30ed\u30b0\u30e9\u30de\u30fc\u3068\u3057\u3066\u63a1\u7528\u3055\u308c\u308b\u305f\u3081\u306b\u306f\uff1f\u5e02\u5834\u4fa1\u5024\u306e\u9ad8\u3044\u30d7\u30ed\u30b0\u30e9\u30de\u30fc\u306b\u306a\u308b\u305f\u3081\u306e\u6700\u77ed\u30eb\u30fc\u30c8\u3092\u8003\u3048\u3066\u307f\u305f</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/carreer.html">\u30b5\u30e9\u30ea\u30fc\u30de\u30f3\u3067\u793e\u5185\u8a55\u4fa1\u4e0a\u3052\u308b\u3088\u308a\u3082\u3001\u81ea\u5206\u3067\u30b3\u30f3\u30c6\u30f3\u30c4\u4f5c\u3063\u3066\u58f2\u3063\u3066\u7a3c\u3044\u3060\u307b\u3046\u304c\u306f\u308b\u304b\u306b\u7c21\u5358\u306b\u65e9\u304f\u5e74\u53ce\u304c\u4e0a\u304c\u308b\u3068\u3044\u3046\u8a71</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/note.html">\u3010\u30d7\u30ed\u30b0\u30e9\u30df\u30f3\u30b0\u521d\u5fc3\u8005\u5fc5\u898b\u3011note\u3067\u6280\u8853\u30c1\u30e5\u30fc\u30c8\u30ea\u30a2\u30eb\u3092\u4f5c\u3063\u3066\u3044\u308b\u4eba\u3092\u307e\u3068\u3081\u3066\u307f\u305f\u3088\uff01</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/learning-programming.html">\u30d7\u30ed\u30b0\u30e9\u30df\u30f3\u30b0\u72ec\u5b66\u8005\u306b\u8d85\u7d76\u304a\u52e7\u3081\u306e5\u3064\u306e\u52c9\u5f37\u6cd5\u3092\u307e\u3068\u3081\u3066\u307f\u305f</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/blog-post_9.html">\u767a\u9054\u969c\u5bb3\u8005\u304c\u5065\u5e38\u8005\u3068\u547c\u3070\u308c\u308b\u793e\u4f1a\u304c\u5275\u308a\u305f\u3044</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/python3-crontab.html">Python3\u3067Crontab\u3092\u8a2d\u5b9a\u3057\u6307\u5b9a\u3057\u305f\u30ad\u30fc\u30ef\u30fc\u30c9\u304b\u3089\u30c4\u30a4\u30c3\u30bf\u30fc\u306e\u3044\u3044\u306d\u306e\u81ea\u52d5\u5b9f\u884c\u3092\u884c\u3046</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/python3-pandasheaderdataframe.html">Python3 Pandas\u3067Header\u306e\u307f\u306eDataFrame\u3092\u4f5c\u6210\u3059\u308b</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/blog-post.html">\u9752\u3044\u4e16\u754c\u306b\u306f\u3001\u5bfe\u7acb\u4eee\u8aac\u304c\u5fc5\u305a\u5b58\u5728\u3059\u308b</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/flask-render-template-vs-reidirect.html">Flask\u306b\u304a\u3051\u308bredirect\u3068render_template\u30e1\u30bd\u30c3\u30c9\u306e\u9055\u3044</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/python3-flask-sqlite3.html">Python3 Flask SQlite3\u3067\u9023\u643a\u3057\u305f\u3068\u304d\u306b\u8d77\u3053\u3063\u305f\u30a8\u30e9\u30fc\u4e00\u89a7\u3068\u5bfe\u51e6\u6cd5</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/04/sqlite3.html">sqlite3\u899a\u66f8 \u30c7\u30fc\u30bf\u30d9\u30fc\u30b9\u306b\u63a5\u7d9a\u3057\u305f\u308a\u3001\u4e2d\u8eab\u306e\u30c6\u30fc\u30d6\u30eb\u78ba\u8a8d\u3057\u305f\u308a\u3002</a>\n</h3>,
<h3 class="post-title entry-title" itemprop="name">\n<a href="https://review-of-my-life.blogspot.com/2018/03/moji-okosi-1.html">LINE\u304b\u3089\u9001\u3063\u305f\u753b\u50cf\u3092\u6587\u5b57\u8d77\u3053\u3057\u3057\u3066\u304f\u308c\u308b\u30a2\u30d7\u30ea\u3092\u4f5c\u308b\u3068\u304d\u306e\u30e1\u30e2\u2460</a>\n</h3>]では、記事一覧を保存してみましょう。
TODO
1. 記事名を取得してください。
2. 記事のURLを取得してください。
解答
tags = soup.find_all("h3", {"class": "post-title"})
for tag in tags:
print (tag.a.string)
print (tag.a.get("href"))結果
『データ解析の実務プロセス入門(あんちべ)』を読んで特に学びが多かったこと
https://review-of-my-life.blogspot.com/2018/06/antibe-data-analysis.html
『プログラミング初心者病』にかかってませんか?自走したプログラミング学習者になるためにすべきことをまとめました。
https://review-of-my-life.blogspot.com/2018/05/programming-beginner-desease.html
『いちばんやさしいグロースハックの教本』のためになったことをまとめた
https://review-of-my-life.blogspot.com/2018/05/growth-hack.html
【急募】『次に売れるAV女優を予測する』スケベKaggleやります!人材募集中!
https://review-of-my-life.blogspot.com/2018/04/sukebe-kaggle.html
『10年後の仕事図鑑』の面白かったところまとめ
https://review-of-my-life.blogspot.com/2018/04/works-10years-later.html
LINEから撮ったテキスト画像を自動で文字起こししてくれる「文字おこし君」を作りました
https://review-of-my-life.blogspot.com/2018/04/moji-okoshi-kun.html
プログラミング教育の僕のスタンスpandas: CSVにデータを保存しよう
記事名とURLの取得に成功しましたので、今度はそのデータをCSVに落としてみましょう。 pandasというライブラリをインストールします。
import pandas as pd取得したいCSVはこんな感じにします。

pandasでは、データフレームという、行と列で構成されたオブジェクトを利用して、CSVを作成することができます。 まずは列名を作成します。
columns = ["Name", "Url"]
df = pd.DataFrame(columns=columns) # 列名を指定する
print(df)実行結果
Empty DataFrame
Columns: [Name, Url]
Index: []今度は行を追加します。
se = pd.Series(['LINEから送った画像を文字起こししてくれるアプリを作るときのメモ①', 'https://review-of-my-life.blogspot.com/2018/03/moji-okosi-1.html'], columns) # 行を作成
df = df.append(se, columns) # データフレームに行を追加
df実行結果

では、さっそく実際にトライしてみましょう。
TODO
1.以下の表のようになるように、データフレームを作成してください。

解答
import pandas as pd
columns = ["Name", "Url"]
df1 = pd.DataFrame(columns=columns) # 列名を指定する
# TODO1 以下の表のようになるように、データフレームを作成してください。
se = pd.Series(['データ解析の実務プロセス入門(あんちべ)』を読んで特に学びが多かったこと', 'https://review-of-my-life.blogspot.com/2018/03/moji-okosi-1.html'], columns) # 行を作成
df1 = df1.append(se, columns) # データフレームに行を追加
se = pd.Series(['sqlite3覚書 データベースに接続したり、中身のテーブル確認したり', 'https://review-of-my-life.blogspot.com/2018/04/sqlite3.html'], columns) # 行を作成
df1 = df1.append(se, columns)
se = pd.Series(['LINEから送った画像を文字起こししてくれるアプリを作るときのメモ①', ' https://review-of-my-life.blogspot.com/2018/03/moji-okosi-1.html'], columns) # 行を作成
df1 = df1.append(se, columns)
df1結果

次に、作成したデータフレームをCSVに変換します。
df.to_csv("ファイル名.csv")でcsvファイルを作成できます。
from google.colab import filesでfiles.download('ファイル名.csv')で、自分のPCにファイルをダウンロードすることができます。
from google.colab import files
df1.to_csv("df1.csv")
files.download('df1.csv')結果:こんな感じでCSV(VR彼女などのスケベタイトルは研究の一環でダウンロードしています)
ホームページの記事名と記事URLのリストをCSVダウンロードしよう
ここまでできたら、最終的にホームページの記事一覧を取得して、記事名とURLを一括CSVでダウンロードしてみましょう。
# TODO
1 requestsで、指定されたURLのHTMLを取得してください。
解答
import pandas as pd # pandasのインポート
from bs4 import BeautifulSoup # BeautifulSoupのインポート
import requests # requestsのインポート
from google.colab import files
url = "https://review-of-my-life.blogspot.com"
# TODO1 requestsで、指定されたURLのHTMLを取得してください。
response = requests.get(url).text
print(response)
# TODO
1 requestsでrequestsで取得したHTMLをBeautifulSoupで呼び出してください。
解答
soup = BeautifulSoup(response, 'html.parser') # BeautifulSoupの初期化
print(soup.prettify())TODO
1. 記事タイトルのh3とクラス名で指定して複数取得し、tagsに格納してください。※さきほど開発者ツールで確認した記事タイトルのHTMLです
解答
#TODO3 h3を複数取得してください。
tags = soup.find_all("h3",{"class":"post-title"})
print(tags)ここからは以下のようなアルゴリズムを実装します。
・データフレームで列を作成
・for文でtagsを回す
・tagから、記事名を取得
・tagから、記事URLを取得
・pandasのSeriesに記事名と記事URLを代入
・データフレームに追加
・最後にCSVにして出力
TODO
1. 記事名と記事URLをすべて取得し、CSVに出力してください。
2. データフレームを作成してください。列名は、name, urlです。
3. 記事名と記事URLをデータフレームに追加してください
4. result.csvという名前でCSVに出力してください。
解答
# データフレームを作成してください。列名は、name, urlです。
columns = ["name", "url"]
df2 = pd.DataFrame(columns=columns)
# 記事名と記事URLをデータフレームに追加してください
for tag in tags:
name = tag.a.string
url = tag.a.get("href")
se = pd.Series([name, url], columns)
print(se)
df2 = df2.append(se, columns)
# result.csvという名前でCSVに出力してください。
filename = "result.csv"
df2.to_csv(filename, encoding = 'utf-8-sig') #encoding指定しないと 、エラーが起こります。おまじないだともって入力します。
files.download(filename)これでダウンロードが行われる画面に行けば、終了です。
お願い!
どうでしょうか?できましたでしょうか?もしできていたら、非常にうれしいです!
もしうまくいって、ほかの人にも伝えたい!と思えたら、このnoteのURLと、#DAINOTE のハッシュタグとともに、ツイッターで投稿してくれるとめちゃくちゃうれしいです!
以下のツイートに #DAINOTE と加えてもらえるような感じで投稿してもらえると、喜びます!
今後のステップ
今回はそのまま写経をして学んだと思いますが、この技術を使って、ほかの分野で応用されるととてもよいでしょう!
例えば、ysさんの場合は、僕のチュートリアルを何個か購入いただいていて、その技術を組み合わせつつこのように応用されています!
ただ写経するだけでは力がつかないので、応用してまた新しいことをやってみるのもよいでしょう!
このnoteをもとに、応用した事例と画像、noteのURLを #DAINOTE のハッシュタグとともに投稿していただけると、とてもうれしいです!
実際、フリーランスとして一番の収益が出ているこのnoteを無料公開するので、非常にダメージがでかいのですが、より多くの方にこのnoteを知ってほしいので、ぜひ助けていただけると嬉しいです!作れる人をどんどん増やしていきたいので!
また、もしこのnoteをやってみて、すごくよかった!という人がいらっしゃいましたら、ぜひ以下のマガジンで、さらに難しいスクレイピングをやってみてください!
3つのチュートリアル¥6,940相当を、セット割¥4,980のプランを用意しました!集中的に勉強してみたい方は、こちらもおすすめです!
・Pythonによるスクレイピング超絶入門
・Pythonによるスクレイピング応用
・スクレイピングを利用したAIアプリ開発
********

サポートでいただいたお金はFanzaの動画を購入するために利用されます。