
[競馬予想AI] ランク学習のバリエーションを増やしてアンサンブル学習すると?

前回は競馬データにランク学習を使用すると、なかなかイイ結果が得られたというnoteを書きました。
この記事の中で、targetというものを設定するお話をしました。これは、どのような基準でランク付けを行っていくかを決める変数です。前回ではtargetに「着順」を使用しましたが、このtargetの決め方には色んなバリエーションが考えられるというお話もしました。
ということで、色々なtargetを用いたモデルでアンサンブル学習するとどうなるか?というのが今回のnoteの主旨になります。
アンサンブル学習とは?
アンサンブル学習とは、色んな学習モデルの出力を集めて最終的な予測結果を算出する方法をいいます。具体的には、多数決であったり、各モデルの性能に応じて出力に重みをつけて合算する方法があります。
今回は、この両方について試してみました。
モデルの出力値
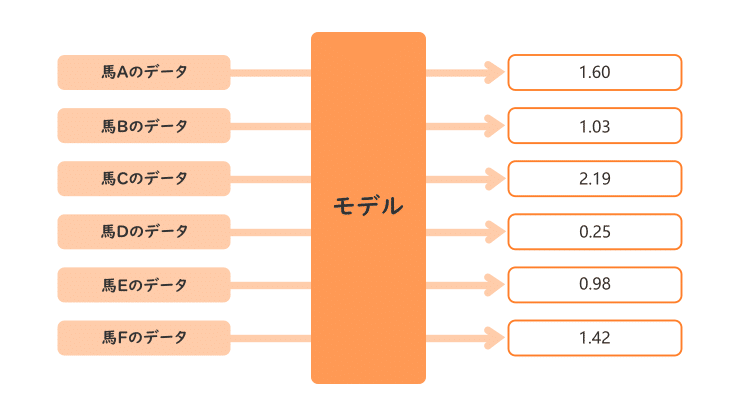
まず、モデルがどのような出力を行っているかをおさらいしておきます。
モデルの入力は本レースに出馬する馬の過去のデータであり、出力は各馬ごとに実数が出力され、この値が大きいほど強いことを表します。
出力値を標準化しておく
アンサンブル学習の実行に際して出力値を標準化しておきましょう。標準化とは、「平均が0、分散が1の正規分布に従う」ように数値変換することです。
標準化すると何が幸せになれるかというと、平均や分散が異なる数値どうしを比較することができるからです。例えば、体重(kg)と身長(m)の数値は単純に比較することができませんが、標準化してスケールを合わせておくと比較が可能になります。
各モデルが出力する値の平均と分散は異なっているという仮定のもと標準化しており、各モデルの出力値を比較することが可能になります。
標準化の計算は難しくないので自身でプログラム可能ですが、たいていのプログラミング言語には標準化のためのライブラリが用意されていますので1行程度のコーディングで済みます。
ちなみにですが、今まで作成してきたAIはアンサンブル学習を想定してすべて出力値を標準化してあります。
下準備はできたので、アンサンブル学習を行っていきましょう。
モデルの性能に応じた重みを付けて出力を合算する方法
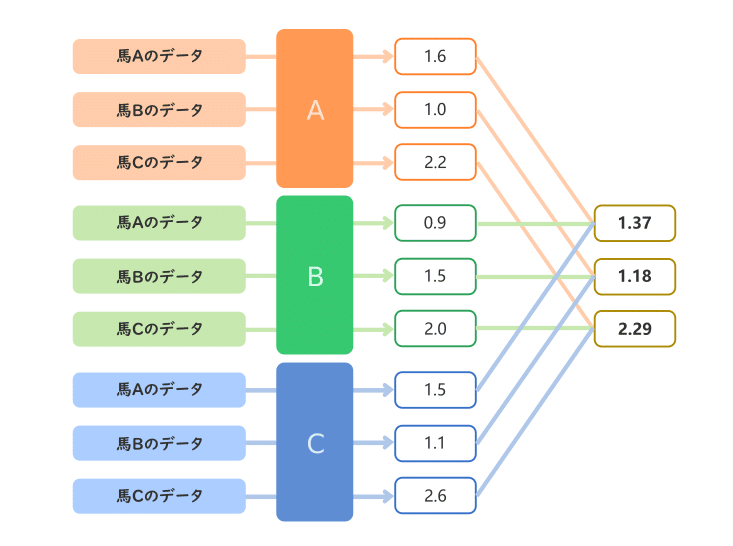
今回は3種類targetを用いた結果をアンサンブルさせます。この3種類の出力をどのように1つにまとめるかですが、まずは各モデルの性能に応じて重みを付けて合算してみようと思います。
例えば3つのモデルA, B, Cの精度が0.75, 0.6, 0.8だったとします。精度が高いモデルの影響力は高くしたいので、各モデルの影響力は次のように決めることにします。
モデルA:0.75 / (0.75+0.6+0.8) = 0.3488
モデルB:0.6 / (0.75+0.6+0.8) = 0.2791
モデルC:0.8 / (0.75+0.6+0.8) = 0.3721
この影響力を重みとして各モデルの出力値に掛けた後、3つの出力値を合算してみます。
多数決で決定する方法
もうひとつ、多数決で最終的な出力を決定する方法があります。
これはとても単純で、各順位にどの馬があてはまるか各モデルの多数決で決定します。
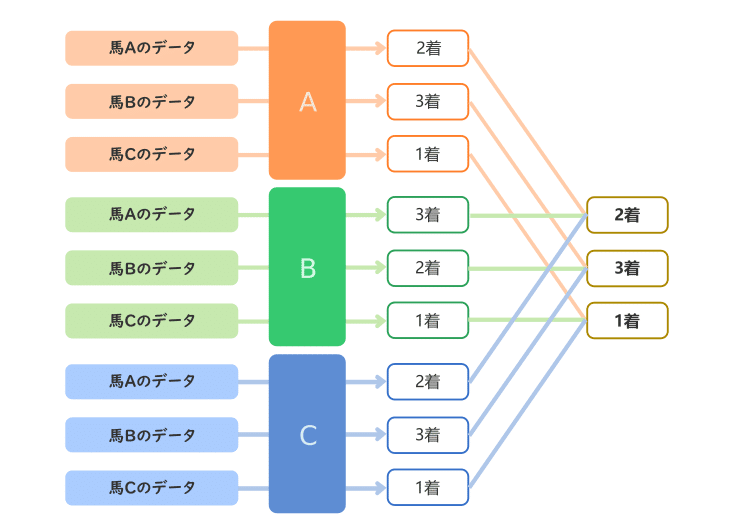
票が均衡する場合がありますのでその時にどのように着順を決定するかを決めておく必要があります。例えば、精度の高い方のモデルの結果を優先するようにしておきます。
アンサンブル学習の結果
紹介した2つの方法でアンサンブル学習をした結果は以下の通りです。モデルの性能の良さはNDCG@3を基準にしています。
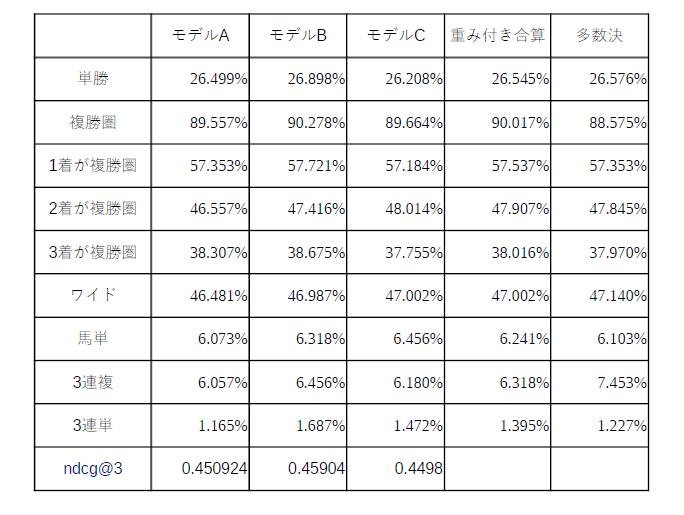
各項目の意味については前回の記事を参照ください。
アンサンブル学習の結果、各モデルの平均的な結果が出てしまいました。唯一各モデルより正解率が上がったのは多数決のワイドと3連複のみとなりました。3連複の精度が上がったのは大きいかなとは思いますが、全体的に見ると大きな精度向上に至らなかったのが残念です。
(3連複の参考回収率:195.1%)
総括
今回、多少強引にアンサンブル学習を行いました。というのも、通常アンサンブル学習は異なるアルゴリズムを使ったモデルどうしで行うのが一般的であるため、今回のような、アルゴリズムは一緒でtargetのみ変更(しかも似たような値)してアンサンブル学習をさせるのはあまり良い使い方ではありません。
AIコンペでは王道的な機械学習と深層学習のアンサンブル学習がよく行われているようです。なので、今後深層学習を実装した際は再びアンサンブル学習にチャレンジしてみようと思います。
今後について
ランク学習については一通りやった感がありますが、まだパラメータチューニングをやっていません。もしかすると、今回のアンサンブル学習よりは良い成果が出るかもしれませんので次回noteで紹介できればと思います。
(追記)
▼チューニング後のアンサンブル学習が完了しました。
その後、いよいよ深層学習に着手していこうと思いますので、こちらの勉強も進めてまいります。
サポートいただきありがとうございます
今までにたくさんの方にサポートいただいており、この度、深層学習の書籍を購入させていただきました。

サポートいただいた皆様には個別にお礼のメッセージを送らせていただいておりますが、この場を借りて改めて感謝申し上げます。
今後とも当noteをどうぞよろしくお願い致します。
よろしければサポートをよろしくお願い致します。いただいたサポートは今後の技術向上のために書籍費用等に当てられ、このnoteで還元できればと思います。