Text Embeddingにおける言語・形式・長さによる影響

まとめ
文章のEmbeddingは、文章の内容の他に言語、形式、長さなどの情報の影響を受ける。
RAGでは検索するテキストの言語・形式を揃えることは重要。
RAGでは内容以外の要素の影響を受けにくい`text-embedding-3-large`を使うべきかもしれない。
背景
単語のEmbeddingでは、意味がベクトルとしてEmbedding空間に埋め込まれます。一方、文章のEmbeddingでは、文章の意味に加えて言語や形式、長さなどの要素がEmbeddingに影響を与えることが考えられます。
例えば、同じ意味の文章でも、日本語と英語では異なるEmbeddingになる可能性があります。また、散文形式とリスト形式では、同じ内容でもEmbeddingが異なるかもしれません。さらに、文章の長さによってもEmbeddingが影響を受ける可能性があります[1]。
RAG(Retrieval Augmented Generation)では、文章の意味のみに基づいて文書検索できることが理想ですが、形式による影響を受けてしまうことが懸念されます。
そこで本記事では、これらの要因が文章のEmbeddingにどのような影響を与えるかを実験的に検証することを目的とします。
実験
本記事では、食材に関する文章を異なる言語・形式(散文、箇条書き、Markdown、JSON、会話形式)・長さで生成し、それらの文章のembeddingを比較することで、文章の形式がembeddingにどのような影響を与えるかを調査することを目的としています。
実験の流れは以下の通りです。
対象の食材について、詳細な解説文を生成
生成した解説文を要約して、長い要約文と短い要約文を作成
各解説文と要約文を、各形式に変換
各言語に翻訳
embeddingを生成
UMAPを用いて次元削減し、散布図で可視化
各文章間のコサイン類似度を計算
合計で、6(食材)×3(長さ)×5(形式)×5(言語)=450の文章を生成します。
対話型言語モデルには`gpt-3.5-turbo-0125`、Embeddingモデルには以下の3モデルを使用しています。
text-embedding-ada-002
text-embedding-3-small
text-embedding-3-large
パイプライン構築にはLangChainのLCELを使用しています。
手順1:解説文生成
各食材について1000字程度の詳細な解説文を使って生成しています。プロンプトでは、原産国、栽培方法、栄養、調理方法、風味、旬の季節、相性のよい食材や調味料、その他の特徴に言及するよう指示しています。
じゃがいも
玉ねぎ
にんじん
なす
トマト
ピーマン
複数の言語に翻訳するため、食材の種類は、一応どの国でも食べられていそうなものにしています。
https://github.com/harukary/portfolio/blob/main/embedding_in_different_format/1_generate_prose.ipynb
手順2:解説文要約
生成した解説文を入力し、長い要約文(約300字)と短い要約文(約150字)を作成しています。要約文は元の解説文の情報を全て保持するよう指示しています。
長さは以下の3種類です。
full:元の解説文
long_sum:長い要約
short_sum:短い要約
https://github.com/harukary/portfolio/blob/main/embedding_in_different_format/2_summarize.ipynb
手順3:形式変換
散文形式である各解説文と要約文を各形式に変換しています。変換後のテキストは元の情報を全て保持するよう指示しています。
形式は以下の5種類です。
prose:散文
bullet_list:箇条書き
markdown:Markdown
json:Json
conversaton:会話形式
しかし、もとの解説文を長くすることが難しかったこと、また、情報を残すように要約する指示をしたことから、文字数はあまり大きな差を出すことはできませんでした。
今思えば、先に短い文章を生成しておき、それを長くする方が良かったかもしれません。
https://github.com/harukary/portfolio/blob/main/embedding_in_different_format/3_transform.ipynb
手順4:翻訳
最後に、全ての文章を翻訳します。最後に翻訳することで、意味的には同じ文章になることを期待しています。
言語は以下の5種類です。
ja:日本語
en:英語
de:ドイツ語
ar:アラビア語
ru:ロシア語
最初は中国語にも翻訳する予定でした。しかし、OpenAIのサーバーで500エラーが毎回起きるようだったため、除外しました。(モデルが無効なUnicode出力を生成したとのことです。)
https://github.com/harukary/portfolio/blob/main/embedding_in_different_format/4_translate.ipynb
手順5:Embedding生成
全ての文章を3つのモデルでEmbeddingしています。
https://github.com/harukary/portfolio/blob/main/embedding_in_different_format/5_embedding.ipynb
手順6:UMAPによる可視化
UMAPを用いてembeddingを2次元に次元削減し、散布図で可視化しています。散布図では、食材、形式、言語、長さごとに色分けして表示しています。
https://github.com/harukary/portfolio/blob/main/embedding_in_different_format/6_visualize_umap.ipynb
手順7:類似度検索
各文章間のコサイン類似度を計算し、各食材の日本語の散文に対して類似度の高い文章を全探索で抽出しています。
実験結果
UMAPによる可視化結果
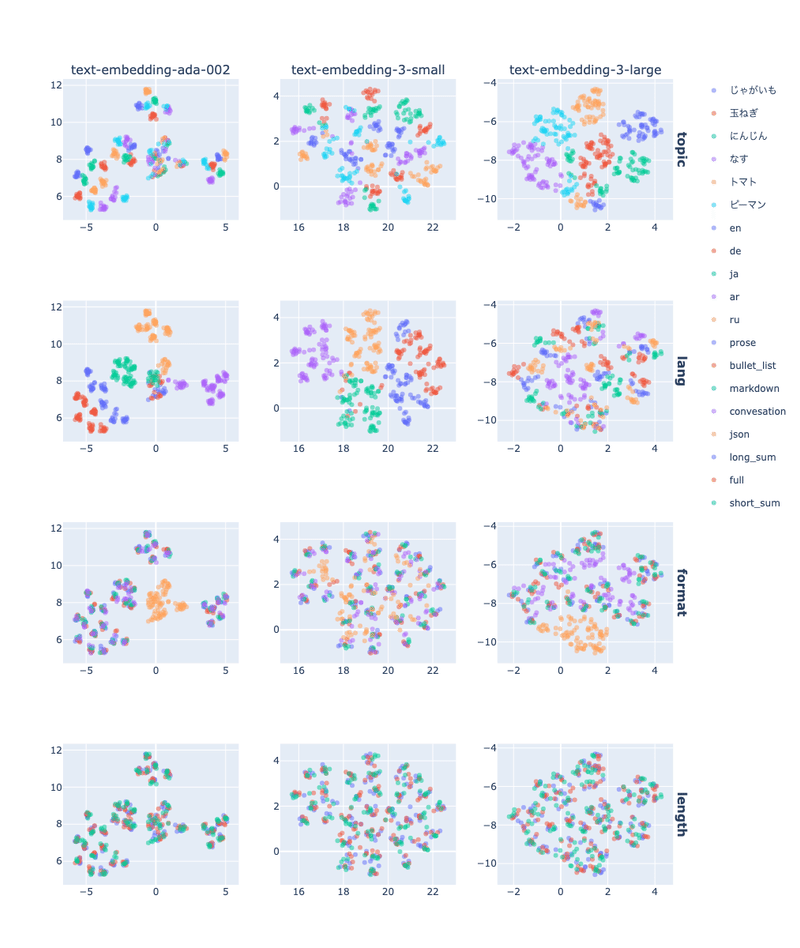
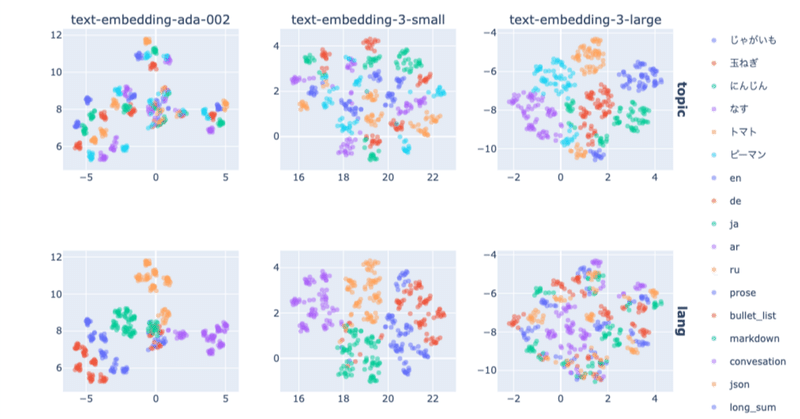
列ごとに各モデル、行ごとに文章の要素(内容、言語、形式、長さ)での色分けを比較できます。
topic:内容
lang:言語
format:形式
length:長さ
以下の内容が見て取れます。
`ada-002`、`3-small`では主に言語で分かれているのに対し、`3-large`では内容で分かれている
どのモデルでもJson形式は最も離れた位置にある
長さについてはほぼ影響がない
このことから、モデルは`3-large`が最もよい可能性が高いです。また、言語・形式についても揃えておいたほうがよいと考えられます。
長さについては、情報量に差が出てくれば、もちろん影響を受けると考えられるため、更なる実験が必要かもしれません。(解説文からより長い文章を生成する方法など)
類似度検索の結果
UMAPでの可視化結果が、実際の高次元空間でのベクトル検索でも同様の結果になるかの確認です。それぞれ、「玉ねぎ」の日本語の解説文(散文形式の元文章)をクエリとして検索した結果のTop-30を下に示します。
ada-002
1. 玉ねぎ-ja-prose-long_sum
2. 玉ねぎ-ja-bullet_list-long_sum
3. 玉ねぎ-ja-bullet_list-full
4. 玉ねぎ-ja-markdown-full
5. 玉ねぎ-ja-markdown-long_sum
6. 玉ねぎ-ja-convesation-full
7. 玉ねぎ-ja-convesation-long_sum
8. 玉ねぎ-ja-markdown-short_sum
9. 玉ねぎ-ja-prose-short_sum
10. 玉ねぎ-ja-bullet_list-short_sum
11. 玉ねぎ-ja-convesation-short_sum
12. にんじん-ja-prose-full
13. にんじん-ja-bullet_list-full
14. にんじん-ja-prose-long_sum
15. にんじん-ja-bullet_list-long_sum
16. にんじん-ja-prose-short_sum
17. にんじん-ja-bullet_list-short_sum
18. にんじん-ja-convesation-full
19. にんじん-ja-markdown-full
20. にんじん-ja-markdown-long_sum
21. じゃがいも-ja-prose-long_sum
22. じゃがいも-ja-bullet_list-long_sum
23. じゃがいも-ja-bullet_list-full
24. にんじん-ja-convesation-short_sum
25. じゃがいも-ja-prose-full
26. にんじん-ja-markdown-short_sum
27. なす-ja-prose-long_sum
28. ピーマン-ja-prose-long_sum
29. じゃがいも-ja-markdown-full
30. じゃがいも-ja-prose-short_sum
3-small
1. 玉ねぎ-ja-prose-long_sum
2. 玉ねぎ-ja-markdown-full
3. 玉ねぎ-ja-bullet_list-long_sum
4. 玉ねぎ-ja-bullet_list-full
5. 玉ねぎ-ja-markdown-long_sum
6. 玉ねぎ-ja-convesation-long_sum
7. 玉ねぎ-ja-markdown-short_sum
8. 玉ねぎ-ja-convesation-full
9. 玉ねぎ-ja-json-long_sum
10. 玉ねぎ-ja-prose-short_sum
11. 玉ねぎ-ja-convesation-short_sum
12. 玉ねぎ-ja-bullet_list-short_sum
13. 玉ねぎ-ja-json-short_sum
14. にんじん-ja-prose-full
15. 玉ねぎ-ja-json-full
16. にんじん-ja-markdown-full
17. にんじん-ja-markdown-long_sum
18. にんじん-ja-bullet_list-full
19. にんじん-ja-json-long_sum
20. にんじん-ja-bullet_list-long_sum
21. にんじん-ja-prose-long_sum
22. にんじん-ja-json-full
23. にんじん-ja-convesation-full
24. にんじん-ja-json-short_sum
25. ピーマン-ja-bullet_list-long_sum
26. じゃがいも-ja-prose-full
27. じゃがいも-ja-bullet_list-full
28. にんじん-ja-convesation-short_sum
29. にんじん-ja-markdown-short_sum
30. なす-ja-markdown-full
3-large
1. 玉ねぎ-ja-prose-long_sum
2. 玉ねぎ-ja-bullet_list-full
3. 玉ねぎ-ja-bullet_list-long_sum
4. 玉ねぎ-ja-markdown-full
5. 玉ねぎ-ja-markdown-long_sum
6. 玉ねぎ-ja-convesation-long_sum
7. 玉ねぎ-ja-markdown-short_sum
8. 玉ねぎ-ja-prose-short_sum
9. 玉ねぎ-ja-bullet_list-short_sum
10. 玉ねぎ-ja-convesation-full
11. 玉ねぎ-en-prose-full
12. 玉ねぎ-en-bullet_list-long_sum
13. 玉ねぎ-en-bullet_list-full
14. 玉ねぎ-en-prose-long_sum
15. にんじん-ja-bullet_list-full
16. 玉ねぎ-en-markdown-long_sum
17. 玉ねぎ-de-bullet_list-full
18. 玉ねぎ-en-markdown-full
19. にんじん-ja-prose-full
20. 玉ねぎ-ja-convesation-short_sum
21. にんじん-ja-bullet_list-long_sum
22. 玉ねぎ-de-bullet_list-long_sum
23. 玉ねぎ-de-prose-full
24. 玉ねぎ-ru-prose-long_sum
25. 玉ねぎ-ru-prose-full
26. にんじん-ja-prose-long_sum
27. にんじん-ja-markdown-long_sum
28. 玉ねぎ-de-prose-long_sum
29. 玉ねぎ-ru-bullet_list-full
30. 玉ねぎ-ru-bullet_list-long_sum
やはり、`ada-002`、`3-small`では主に言語が同じ文章しか上位にランクインしていないのに対し、`3-large`では異なる言語の文章でも上位にランクインしています。
しかし、`3-large`でも同じ日本語の「にんじん」は様々な形式でランクインしています。このため、言語の影響を受けにくいとしても、揃えた方が良さそうです。
ちなみに、気づいた方もいらっしゃるかもしれませんが、アラビア語はTop-30にランクインしていません。Top-50まで見ると発見できました。形式の中のJsonのように、言語の中のアラビア語はEmbeddingに強く影響する要素なのでしょう。
3-large(31位以下)
31. にんじん-ja-markdown-full
32. にんじん-ja-markdown-short_sum
33. にんじん-ja-bullet_list-short_sum
34. 玉ねぎ-ja-json-long_sum
35. 玉ねぎ-en-convesation-long_sum
36. 玉ねぎ-de-markdown-long_sum
37. にんじん-ja-prose-short_sum
38. 玉ねぎ-ru-markdown-long_sum
39. 玉ねぎ-de-markdown-full
40. 玉ねぎ-ru-markdown-full
41. 玉ねぎ-en-convesation-full
42. 玉ねぎ-en-bullet_list-short_sum
43. 玉ねぎ-ar-prose-full
44. 玉ねぎ-en-prose-short_sum
45. 玉ねぎ-ar-prose-long_sum
46. 玉ねぎ-ja-json-short_sum
47. 玉ねぎ-en-markdown-short_sum
48. 玉ねぎ-ar-bullet_list-full
49. 玉ねぎ-ar-markdown-long_sum
50. 玉ねぎ-de-convesation-long_sum
まとめ
本実験では、食材に関する文章を異なる形式で生成し、それらの文章のembeddingを比較することで、文章の形式がembeddingに与える影響を調査しました。実験の結果、文章のembeddingは形式と言語の影響を大きく受けることがわかりました。また、embeddingモデルの種類によっても分布の傾向が異なることがわかりました。
今後は、RAGにおいて内容以外の影響を小さくする方法をご紹介できればと思います。
本実験で得られた知見が、LLM活用、RAGシステム開発に関わる方に役に立つことを期待しています。
参考
この記事が気に入ったらサポートをしてみませんか?