ファイナンス機械学習:分数次差分をとった特徴量:練習問題 E-mini S&P500先物ドルバー対数累積分数次差分時系列へのトリプルバー

E-mini S&P500先物ティックバーからドルバーを取り、これを対数累積した時系列を$${d=2}$$で固定ウィンドウ法で差分した定常な時系列を扱う。
hをこの分数次差分時系列の標準偏差の2倍とし、CUSUMフィルターを適用する。
import Labels as labels
dv=500_000
Dbar=bars.getDollarBars(SP_data,dv)
close = Dbar['Close'].to_frame()
logClose=np.log(close.astype(float)).cumsum()
lCFFD = fracDiff_FFD(logClose, d=2.0, thres=1e-5).dropna()
thred=lCFFD['Close'].std()
Events=bars.getTEvents(log_fd2['Close'], thred*2.)
Events
CUSUMフィルターを通したタイムスタンプをインデックスを使い、分数次差分と価格を特徴量としてData Frameに加える。
dfEvents= pd.DataFrame(index = Events).assign(Close = close,
ffd = log_fd2['Close']).drop_duplicates().dropna()トリプルバリアを、日次標準偏差の2倍の大きさの水平バリアと5日間の垂直バリアとして適用し、ラベルを作成する。
span0=20
price=dfEvents['Close']
t1 = labels.addVerticalBarrier(price, Events, numDays=5)
dfEvents['DailyVol']=labels.getDailyVol(price,span0)
dfEvents.dropna()
ptsl=[2,2]
minRet = .0002
TPevents=labels.getEventsML(dfEvents['Close'],dfEvents.index,ptsl,dfEvents['DailyVol'],minRet,t1=t1,side=None).dropna()
TPlabels=labels.getBinsTUML(TPevents,dfEvents['Close'],t1)
TPlabels = TPlabels[~(TPlabels['bin'] == 0)]
TPlabels['bin'].value_counts()
TPlabels
Sequential Bagging Classifier
Sklearn.ensembleのBaggingClassifierを継承し、サンプルの平均独自性を計算しながらバギングを行うサンプリングを行うSequentiallyBoostrappedBaggingと、これを使用するSequentiallyBoostrappedBaggingClassifierのクラスを作成する。
import itertools
import numbers
from typing import Union
import numpy as np
import pandas as pd
from scipy import sparse
from sklearn.base import BaseEstimator
from sklearn.base import ClassifierMixin
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble._bagging import BaseBagging
from sklearn.ensemble._base import _partition_estimators
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.utils import check_array
from sklearn.utils import check_consistent_length
from sklearn.utils import check_random_state
from sklearn.utils import check_X_y
from sklearn.utils import indices_to_mask
from sklearn.utils._joblib import delayed
from sklearn.utils._joblib import Parallel
from sklearn.utils.random import sample_without_replacement
from sklearn.utils.validation import has_fit_parameter
from abc import ABCMeta, abstractmethod
from Weights import getIndMatrix, seqBootstrap, getAvgUniqueness
MAX_INT = np.iinfo(np.int32).max
def _generate_random_features(
random_state: np.random.RandomState,
bootstrap: bool,
n_population: int,
n_samples: int,):
if bootstrap:
indices = random_state.randint(0, n_population, n_samples)
else:
indices = sample_without_replacement(
n_population, n_samples, random_state=random_state
)
return indices
def _generate_bagging_indices(
random_state: np.random.RandomState,
bootstrap_features: bool,
n_features: int,
max_features: Union[int,float],
max_samples: Union[int,float],
indM,
):
random_state = check_random_state(random_state)
# Draw indices
feature_indices = _generate_random_features(
random_state, bootstrap_features, n_features, max_features
)
sample_indices = seqBootstrap(
pd.DataFrame(indM.toarray()), max_samples
)
print(sample_indices)
print('Average Uniqueness: ',getAvgUniqueness(pd.DataFrame(indM.toarray())[sample_indices]).mean())
return feature_indices, sample_indices
def _parallel_build_estimators(
n_estimators,
ensemble,
X,
y,
indM,
sample_weight,
seeds,
total_n_estimators,
verbose,
) :
# Retrieve settings
n_samples, n_features = X.shape
max_features = ensemble._max_features
max_samples = ensemble._max_samples
bootstrap_features = ensemble.bootstrap_features
support_sample_weight = has_fit_parameter(ensemble.estimator_, "sample_weight")
if not support_sample_weight and sample_weight is not None:
raise ValueError("The base estimator doesn't support sample weight")
# Build estimators
estimators = []
estimators_features = []
estimators_indices = []
#print('parallel build',indM)
for i in range(n_estimators):
if verbose > 1:
print(
"Building estimator %d of %d for this parallel run "
"(total %d)..." % (i + 1, n_estimators, total_n_estimators)
)
random_state = seeds[i]
estimator = ensemble._make_estimator(append=False, random_state=random_state)
# Draw random feature, sample indices
features, indices = _generate_bagging_indices(
random_state,
bootstrap_features,
n_features,
max_features,
max_samples,
indM,
)
# Draw samples, using sample weights, and then fit
if support_sample_weight:
if sample_weight is None:
curr_sample_weight = np.ones((n_samples,))
else:
curr_sample_weight = sample_weight.copy()
sample_counts = np.bincount(indices, minlength=n_samples)
curr_sample_weight *= sample_counts
estimator.fit(X[:, features], y, sample_weight=curr_sample_weight)
else:
estimator.fit((X[indices])[:, features], y[indices])
estimators.append(estimator)
estimators_features.append(features)
estimators_indices.append(indices)
return estimators, estimators_features, estimators_indices
class SequentiallyBootstrappedBaseBagging(BaseBagging, metaclass=ABCMeta):
"""
Base class for Sequentially Bootstrapped Classifier and Regressor, extension of sklearn's BaseBagging
"""
@abstractmethod
def __init__(
self,
t1:pd.Series,
estimator: BaseEstimator = None,
n_estimators: int = 10,
max_samples: Union[int, float] = 1.0,
max_features: Union[int, float] = 1.0,
bootstrap_features: bool = False,
oob_score: bool = False,
warm_start: bool = False,
n_jobs: int = None,
random_state: Union[int, np.random.RandomState, None] = None,
verbose: int = 0,
):
super().__init__(
estimator=estimator,
n_estimators=n_estimators,
bootstrap=True,
max_samples=max_samples,
max_features=max_features,
bootstrap_features=bootstrap_features,
oob_score=oob_score,
warm_start=warm_start,
n_jobs=n_jobs,
random_state=random_state,
verbose=verbose,
)
self.t1= t1
self.barIx = t1.index
self._indM = None
/
# Used for create get ind_matrix subsample during cross-validation
self.timestamp_int_index_mapping = pd.Series(
index=self.barIx, data=range(self.indM.shape[1])
)
self.X_time_index = None # Timestamp index of X_train
@property
def indM(self):
if self._indM is None:
self._indM = getIndMatrix(
self.barIx, self.t1
)
return self._indM
def fit(
self,
X: pd.DataFrame,
y: pd.Series,
sample_weight: pd.Series = None,
):
return self._fit(X, y, self.max_samples, sample_weight=sample_weight)
def _fit(
self,
X: pd.DataFrame,
y: pd.Series,
max_samples:Union[int, float] = None,
max_depth = None,
sample_weight: pd.Series = None,
):
assert isinstance(X, pd.DataFrame), "X should be a dataframe with time indices"
assert isinstance(y, pd.Series), "y should be a series with time indices"
assert isinstance(
X.index, pd.DatetimeIndex
), "X index should be a DatetimeIndex"
assert isinstance(
y.index, pd.DatetimeIndex
), "y index should be a DatetimeIndex"
random_state = check_random_state(self.random_state)
self.X_time_index = X.index # Remember X index for future sampling
set(self.X_time_index)
assert set(self.timestamp_int_index_mapping.index).issuperset(
set(self.X_time_index)
),"The ind matrix timestamps should have all the timestamps in the training data"
indM = csr_matrix(self.indM.astype(pd.SparseDtype("float64",0)).sparse.to_coo())
subsampled_indM = indM[
:, self.timestamp_int_index_mapping.loc[self.X_time_index]
]
# Convert data (X is required to be 2d and indexable)
X, y = check_X_y(
X, y, ["csr", "csc"], dtype=None, force_all_finite=False, multi_output=True
)
if sample_weight is not None:
sample_weight = check_array(sample_weight, ensure_2d=False)
check_consistent_length(y, sample_weight)
# Remap output
n_samples, self.n_features_ = X.shape
self._n_samples = n_samples
y = self._validate_y(y)
# Check parameters
self._validate_estimator()
# Validate max_samples
if not isinstance(max_samples, (numbers.Integral, np.integer)):
max_samples = int(max_samples * X.shape[0])
if not (0 < max_samples <= X.shape[0]):
raise ValueError("max_samples must be in (0, n_samples]")
# Store validated integer row sampling value
self._max_samples = max_samples
# Validate max_features
if isinstance(self.max_features, (numbers.Integral, np.integer)):
max_features = self.max_features
elif isinstance(self.max_features, float):
max_features = self.max_features * self.n_features_
else:
print(type(self.max_features))
raise ValueError("max_features must be int or float")
if not (0 < max_features <= self.n_features_):
raise ValueError("max_features must be in (0, n_features]")
max_features = max(1, int(max_features))
# Store validated integer feature sampling value
self._max_features = max_features
if self.warm_start and self.oob_score:
raise ValueError("Out of bag estimate only available if warm_start=False")
if not self.warm_start or not hasattr(self, "estimators_"):
# Free allocated memory, if anyexpiritation
self.estimators_ = []
self.estimators_features_ = []
self.sequentially_bootstrapped_samples_ = []
n_more_estimators = self.n_estimators - len(self.estimators_)
if n_more_estimators < 0:
raise ValueError(
"n_estimators=%d must be larger or equal to "
"len(estimators_)=%d when warm_start==True"
% (self.n_estimators, len(self.estimators_))
)
elif n_more_estimators == 0:
warn(
"Warm-start fitting without increasing n_estimators does not "
"fit new trees."
)
return self
# Parallel loop
n_jobs, n_estimators, starts = _partition_estimators(
n_more_estimators, self.n_jobs
)
total_n_estimators = sum(n_estimators)
# Advance random state to state after training
# the first n_estimators
if self.warm_start and len(self.estimators_) > 0:
random_state.randint(MAX_INT, size=len(self.estimators_))
seeds = random_state.randint(MAX_INT, size=n_more_estimators)
self._seeds = seeds
all_results = Parallel(n_jobs=n_jobs, verbose=self.verbose,)(
delayed(_parallel_build_estimators)(
n_estimators[i],
self,
X,
y,
subsampled_indM,
sample_weight,
seeds[starts[i] : starts[i + 1]],
total_n_estimators,
verbose=self.verbose,
)
for i in range(n_jobs)
)
# Reduce
self.estimators_ += list(
itertools.chain.from_iterable(t[0] for t in all_results)
)
self.estimators_features_ += list(
itertools.chain.from_iterable(t[1] for t in all_results)
)
self.sequentially_bootstrapped_samples_ += list(
itertools.chain.from_iterable(t[2] for t in all_results)
)
if self.oob_score:
self._set_oob_score(X, y)
self._ind_mat = None
return self
class SequentiallyBootstrappedBaggingClassifier(
SequentiallyBootstrappedBaseBagging, BaggingClassifier, ClassifierMixin
):
def __init__(
self,
t1:pd.Series,
estimator: BaseEstimator = None,
n_estimators: int = 10,
max_samples: Union[float,int] = 1.0,
max_features: Union[float, int] = 1.0,
bootstrap_features: bool = False,
oob_score: bool = False,
warm_start: bool = False,
n_jobs: int = None,
random_state: Union[int, np.random.RandomState, None]=None,
verbose: int = 0,
):
super().__init__(
t1,
estimator=estimator,
n_estimators=n_estimators,
max_samples=max_samples,
max_features=max_features,
bootstrap_features=bootstrap_features,
oob_score=oob_score,
warm_start=warm_start,
n_jobs=n_jobs,
random_state=random_state,
verbose=verbose,
)
def _validate_estimator(self):
"""
Check the estimator and set the base_estimator_ attribute.
"""
super(BaggingClassifier, self)._validate_estimator(
default=DecisionTreeClassifier()
)
def _set_oob_score(self, X: pd.DataFrame, y: pd.Series):
n_samples = y.shape[0]
n_classes_ = self.n_classes_
predictions = np.zeros((n_samples, n_classes_))
for estimator, samples, features in zip(
self.estimators_,
self.sequentially_bootstrapped_samples_,
self.estimators_features_,
):
# Create mask for OOB samples
mask = ~indices_to_mask(samples, n_samples)
if hasattr(estimator, "predict_proba"):
predictions[mask, :] += estimator.predict_proba(
(X[mask, :])[:, features]
)
else:
p = estimator.predict((X[mask, :])[:, features])
j = 0
for i in range(n_samples):
if mask[i]:
predictions[i, p[j]] += 1
j += 1
if (predictions.sum(axis=1) == 0).any():
warn(
"Some inputs do not have OOB scores. "
"This probably means too few estimators were used "
"to compute any reliable oob estimates."
)
oob_decision_function = predictions / predictions.sum(axis=1)[:, np.newaxis]
oob_score = accuracy_score(y, np.argmax(predictions, axis=1))
self.oob_decision_function_ = oob_decision_function
self.oob_score_ = oob_scoreこのファイルをインポートする。
import SeqBoostCassfier as SeqB
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.metrics import precision_score, recall_score, f1_score
np.random.seed(1251)
n_estimate = 10
random_state = 42
max_samples = 50
tree = DecisionTreeClassifier(criterion='entropy',
max_depth=None,
random_state=random_state)
bagtree = SeqB.SequentiallyBootstrappedBaggingClassifier(estimator=tree,
t1=t1,
n_estimators=n_estimate,
max_samples=max_samples,
max_features=1.0,
bootstrap_features=False,
oob_score = True,
n_jobs=1,
random_state=random_state) 特徴量Xは価格時系列、対数価格累積の分数次差分時系列、日次ボラティリティとし、トリプルバリアのラベルをyとする。
トリプルバリアのラベルは、t1でのリターンに符号に一致するから、Xから抜くこととする。
X=dfEvents.drop(['bin','ret'],axis=1)
y=dfEvents['bin'].astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)
bag.fit(X_train,y_train)
y_pred = bagtree.predict(X_test)
y_prob = bagtree.predict_proba(X_test)[:,1]
print(f'RF OOB accuracy: {bagtree.oob_score_}')
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve,auc
print(classification_report(y_true=y_test, y_pred=y_pred))
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr,tpr,label=' ROC area = %0.2f' %(roc_auc))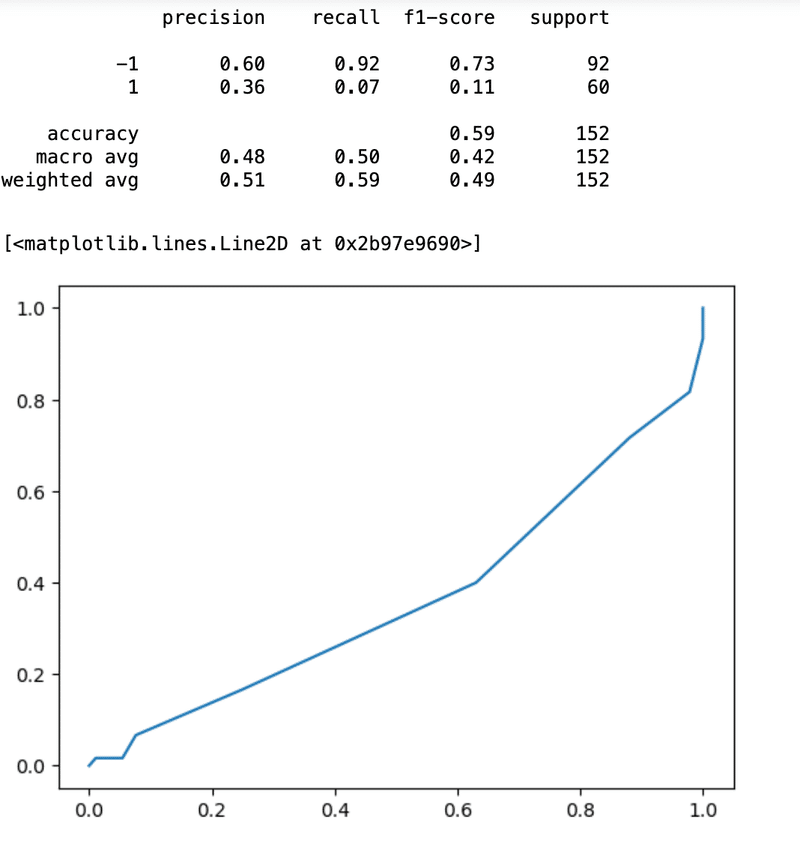
この記事が気に入ったらサポートをしてみませんか?