
切り抜き動画を自動生成するpythonライブラリ「clipsai」が凄すぎて夢かと思った

皆様ハロー、お小遣い稼ぎ系エンジニアのスマイルです('ω')ノ
以前、VTuberの切り抜き動画を作るのにハマっていた時期があり自動化ツールとか作っていました。
しばらく切り抜き制作からは離れていたんですが、「clipsai」という面白そうなpythonライブラリを見つけたので試してみましたら、動画のシーンを自動で検出して切り分けるという強烈な切り抜き時短ライブラリである事が発覚したので、レポートをまとめました。
記事が面白かったらフォロー&♥よろしくお願いしますm(_ _)m
使ってる様子はこんな感じ
すっげぇ!「切り抜き位置の推定」という解決出来なかった問題が、ライブラリ1発で解消してしまった…
ちなみに公式のデモはこちら。
デモにはUIまで付いていますが、実際のライブラリは機能の中身だけでインターフェースは付属していません。入力画面などのフロント側まで欲しい人は自作する必要があります。
使ってみた感想

実際に使ってみた感想として、良かった点・悪かった点をまとめてみました。
ここが良き!
ボトルネックの自動化
:切り抜き動画を作った事がある人は分かると思いますが「面白いシーンを探す作業」ってのが一番重要で時間かかるんですよ。これを完全自動化できる事の意味は甚だ大きい。マジ夢のドリーム機能です。無料&無制限
:pythonライブラリなので課金も制限も一切なし!切り抜きたいだけ切り抜ける気持ちよさがハンパない。スクリプトを実行して自動で切り抜かれた動画ファイルがずらーーって出力される様子はたまらんす。シンプル!
:必要な機能だけがコンパクトにまとまってる感じが好印象。実装の行数も少なくてあんまり難しくないのもグッド。
ここはイマイチ…
公式ドキュメントが不親切
:あんまり詳しく書いてくれてない。コードを読み解いて自力で実装できる人は上手く使ってね!みたなスタンスなのでそれなりのpython力が必要かも。情報が少なすぎてchatGPTも歯が立たない。動画の長さがバラバラ
:出力結果をコントロールするような機能がなく、純粋に動画内容を判別して切り分けられちゃうのでショート動画としては長いし、長尺動画としては短いみたいな微妙な長さの動画が大量生産される。クオリティを目指すなら動画の結合なんかが必要になりそう。日本語だとほぼ検出不可能
:機能的には日本語対応しているハズなんだけど、会話のトピック検出精度がクソ。1シーンもトピックが検出されない事も多い。現段階では実質英語コンテンツ専用か?処理が重い
:動画を扱うライブラリなので当然ちゃ当然だけども、pytorchをCPUでゴリゴリ動かしてる感じで処理がかなり重い(上記画像参照)。マシンの処理能力がそれなりに備わってないとまともに動かないかも。
セットアップ
こっからは実際に使ってみたい人向けのセットアップ手順です、結構長いんで丁寧にいきましょ。
pythonのバージョンを指定する
pythonのバージョンは3.10.11で実行確認しました、3.12.xxの新しいpythonだとエラーが出たのでバージョンの一致推奨です。
僕はwindowsなので下記の通りですが、各自の環境に合った物を選択して下さい。

インストーラーを実行して適当にポチポチ押して3.10.11をインストール出来たらOK、そもそもpythonが分からんという方はまずは基本から覚えましょ。
clipsaiのインストール
clipsaiライブラリはpipで普通にインストール可能。
pip install clipsaiwhisperxのインストール
テキストの解析や文字起こしに使われるwhisperはgitから。
pip install whisperx@git+https://github.com/m-bain/whisperx.gitlibmagicのインストール
pip install python-magic-binffmpegのインストール
ffmpegをpythonで使うにはライブラリのインストールだけじゃなくて、本体のソフトをダウンロードしてローカルにパスを通す作業が必要です。
■ DL&環境変数の設定
下記の記事が分かりやすいのでffmpegの設定をされていない方は読みましょ。
■ pythonライブラリをインストールする
pip install ffmpeg-python実行テスト
ここまで出来たらセットアップ完了、公式のサンプルスクリプトがちゃんと動くかテストしてみます。
from clipsai import ClipFinder, Transcriber
transcriber = Transcriber()
transcription = transcriber.transcribe(audio_file_path="/abs/path/to/video.mp4")
clipfinder = ClipFinder()
clips = clipfinder.find_clips(transcription=transcription)
print("StartTime: ", clips[0].start_time)
print("EndTime: ", clips[0].end_time)実行結果がこんな感じにになれば正常にセットアップ完了。AIで判定したクリップのStartTimeとEndTimeが表示されているのが分かりますね。

ちなみにclipsリストに格納されてる情報は下記の通り、入っている情報は4種類だけ。

clipsaiで出来る事
主な機能は「トピックの検出&セグメント化 / 動画のトリミング / 動画サイズの変更 / 文字起こし」の4つ。公式の不親切なサンプルスクリプトも載せておきますので、手元で試しながら読むと理解が深まると思います。
トピックの検出&セグメント化
from clipsai import ClipFinder, Transcriber
transcriber = Transcriber()
transcription = transcriber.transcribe(audio_file_path="/abs/path/to/video.mp4")
clipfinder = ClipFinder()
clips = clipfinder.find_clips(transcription=transcription)
print("StartTime: ", clips[0].start_time)
print("EndTime: ", clips[0].end_time)動画の内容を判別してシーンの切れ目を自動で検出してくれる機能。返り値としては上述のclipsリストへclips[0],clips[1],clips[2]…とシーン別に格納される感じ。
clips[0]はたぶん固定で動画全体の前後をちょこっとトリミングしただけっぽい。切り抜き動画として使うならclips[1]以降だけでいいかも。
動画のトリミング(切り抜き)
media_editor = clipsai.MediaEditor()
# use this if the file contains audio stream only
media_file = clipsai.AudioFile("/abs/path/to/audio_only_file.mp4")
# use this if the file contains both audio and video stream
media_file = clipsai.AudioVideoFile("/abs/path/to/video.mp4")
clip = clips[0] # select the clip you'd like to trim
clip_media_file = media_editor.trim(
media_file=media_file,
start_time=clip.start_time,
end_time=clip.end_time,
trimmed_media_file_path="/abs/path/to/clip.mp4", # doesn't exist yet
)検出されたシーンのstart_time・end_timeから動画を切り抜いて出力する機能。音声のみなら「clipsai.AudioFile」、動画なら「clipsai.AudioVideoFile」を使う。
動画サイズの変更
from clipsai import resize
crops = resize(
video_file_path="/abs/path/to/video.mp4",
pyannote_auth_token="pyannote_token",
aspect_ratio=(9, 16)
)
print("Crops: ", crops.segments)動画の出力サイズを変更する機能。16:9のワイド動画を9:16の縦長動画にリサイズしたい時に使う。
顔認識機能とかも備えていて、シーン変化時に自動的に話者の顔面を動画の中央に持ってくるように位置を補正してくれる。
この機能はHuggingFaceで公開されている2つのモデルを利用しており、それぞれユーザー条件に同意しないと利用できないため、スクリプトを実行する前に利用申請を行う必要がある。僕は下記のように申請したら使えるようになった。
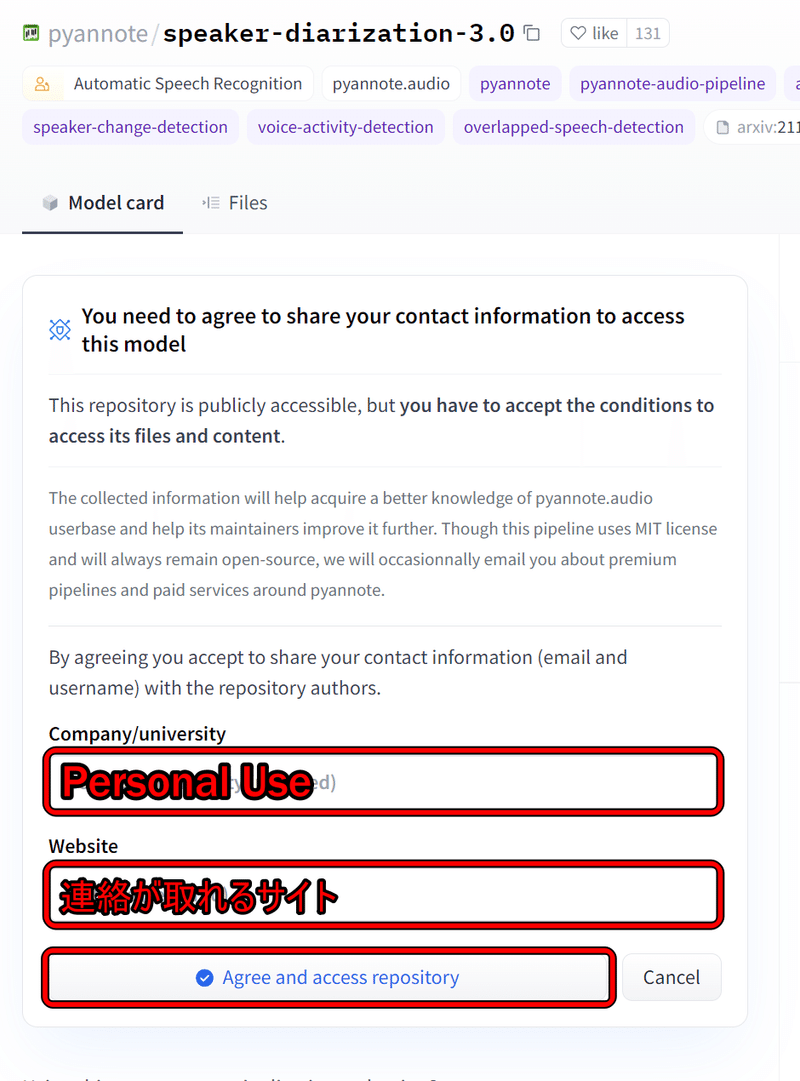
これを以下2つのモデルで実施する。
HuggingFaceのアクセストークンは下記で確認できる。

HuggingFaceのREADアクセストークンをコピーしてスクリプトに貼り付けると、各モデルをHuggingFaceのアクセストークン経由で使えるようになる。
clipsaiのバージョンによっては利用するモデルが変更になる可能性があるので、エラー内容を確認してモデルを特定し必要な申請を行うべし。
文字起こし
from clipsai import Transcriber
transcriber = Transcriber()
transcription: Transcription = transcriber.transcribe(
audio_file_path="/abs/path/to/video.mp4"
)whisperを使ってるので当然文字起こしも出来ちゃう。レスポンスはtranscriptionオブジェクトに格納されて中身は以下の通り。
# Transcription Data Structure
## Characters Information
- `char`: 文字を表す。
- `start_time`: 文字が始まる時間(秒)。
- `end_time`: 文字が終わる時間(秒)。
- `speaker`: 話者の情報。
- `word_index`: 単語のインデックス。
- `sentence_index`: 文のインデックス。
## Words Information
- `word`: 単語を表す。
- `start_char`: 単語の開始文字のインデックス。
- `end_char`: 単語の終了文字のインデックス。
- `start_time`: 単語が始まる時間(秒)。
- `end_time`: 単語が終わる時間(秒)。
- `speaker`: 話者の情報。
## Sentences Information
- `_sentence_info`: 各文に関する情報。
- `sentence`: 文のテキスト。
- `start_char`: 文の開始文字インデックス。
- `start_time`: 文が始まる時間(秒)。
- `end_char`: 文の終了文字インデックス。
- `end_time`: 文が終わる時間(秒)。
## Additional Information
- `source_software`: 文字起こしに使用されたソフトウェア。
- `time_created`: 文字起こしが行われた時間。
- `language`: 使用された言語。
- `num_speakers`: 話者の数。
- `_type_checker`: 型チェッカーのオブジェクト。データ構造を上手く表現する方法を知らないので、サンプルデータの.txtもそのまま掲載しちゃう。詳しく知りたい方はご参照下さい。
上手く行かない人向け
ここまでは公式リファレンスの内容に基づいて解説しましたが、カスタマイズして使っている僕の環境をご紹介します。
ファイル構造
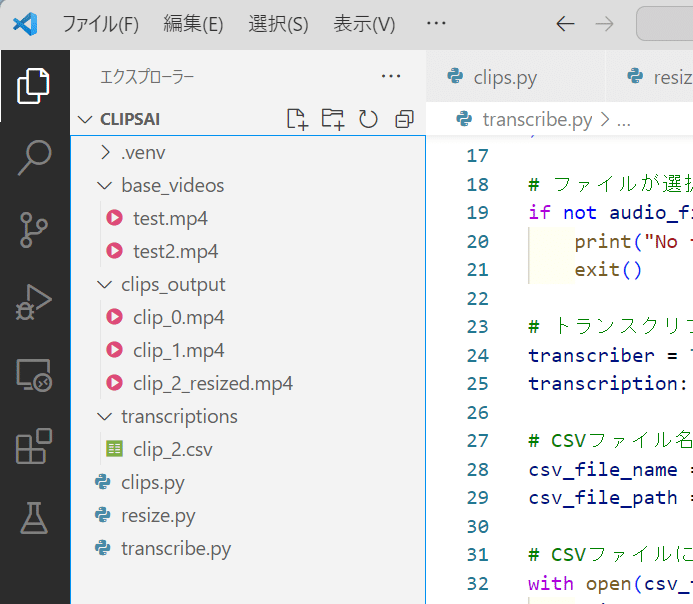
.venv:仮想環境
base_videosフォルダ:切り抜き元の動画をここに置く
clips_outputフォルダ:clips.pyでトピック毎に切り抜かれた動画がここに保存される
transcriptionsフォルダ:transcribe.pyで文字起こしした結果がCSVでここに保存される
clips.py:動画切り抜き用の実行ファイル
resize.py:動画リサイズ用の実行ファイル
transcribe.py:文字起こし用の実行ファイル
清書済みコピペスクリプト
公式のサンプルスクリプトが微妙に不親切だったんで、ファイルの選択画面付けてちゃんと動作するように清書しました。
トピック検出&動画の切り抜き(clips.py)
9:16縦長動画への変換(resize.py)
文字起こしデータのCSV出力(transcribe.py)
それぞれのスクリプトを実行するとエクスプローラーが表示されますんで、処理したい動画を選択して下さい。後は待っていれば結果がそれぞれのフォルダに出力されます。
コピペスクリプトを置いておきますんで必要な方は使ってみて下さい。
◆ clips.py
ここから先は
よろしければサポートお願いします、頂いたサポートは活動費として使用させて頂きより有意義な記事を書けるように頑張ります!