Andrew 先生から ML Ops の基礎を学ぶ①

とあるきっかけで Coursera の「Machine Learning Engineering for Production (MLOps)専門講座」の受講を開始しました。細かい実装の技術には関心は薄いのですが、プロダクション環境に機械学習を乗っけるにあたってどういった手続きを踏んでどういった点を考慮する必要があるのかしっかり学び、ML系のプロジェクトを円滑に進められるようになりたいというモチベーションです。
専門講座はいくつかのコースで構成されていますが、もしかしたら 1 つめのコースである「Introduction to Machine Learning in Production」で満足するかもしれません。満足するところまで、学習メモを Note にとっていきながら進めていこうと思います。
Andrew 先生の Machine Learning 専門講座や Deep Learning 専門講座はとてもわかりやすかったので今回のコースもとても楽しみです。
初回は Introduction to Machine Learning in Production の Week1 の内容についてメモしようと思います。
ML プロジェクトのライフサイクル
ML プロジェクトにおいて、「モデルを開発する」という工程は全体のほんの一部。
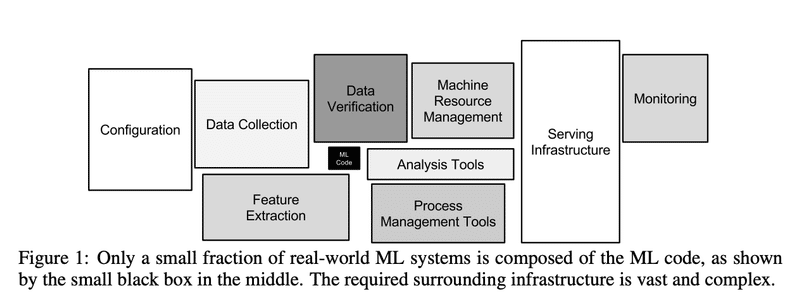
このコースの整理では ML プロジェクトのライフサイクルを次の様に定義する
Scopingフェーズ
プロジェクト定義, キーメトリクスの決定, リソースやプロジェクトのタイムラインを敷くなど
指標について(音声認識の例)
精度, レイテンシー, スループット, 1秒間にどれだけのクエリを処理できるか…
Data フェーズ
アルゴリズムに必要なデータを取得する
データ定義、データのラベリングなど
音声認識でのデータ定義の例
音量の正規化をどのように行うか?(話す人によっては大きな声の人もいれば小さな声の人もいる)
「あー」とか「えー」のような言葉を含めるか
話し手が話すのをやめたと判定するのは言葉を発しなくなってから何ミリ秒, 秒経ってからにするか?
アルゴリズムでの学習が行いやすいようにデータに一貫性をもたせることが大事。
Modeling フェーズ
モデルを選択、学習し、エラー分析により改善する
Research/Academia の領域と異なり、ビジネスシーンではデータ固定でモデル・アルゴリズム自体を改善していくよりかは、モデル固定でデータやハイパーパラメータの改善により性能を向上させることにリソースを割くことが効果的である
Deployment フェーズ
プロダクション環境にデプロイし、システムをモニタリングする
以降、各フェーズについて深ぼっていく形のコース構成になっている。
Week1 では Deployment, Week2 では Modeling フェーズ, Week3 では Data と Scoping フェーズに関するトピックが扱われる。
Deployment フェーズにおけるトピック
データドリフトとコンセプトドリフト
ML を運用していくにあたっては、Concept Drift と Data Drift の 2 つによりモデルの性能が劣化する。したがってこれらのドリフトを検知できるようにモニタリングすることが必要。
● Data drift
Data drift: 学習時のデータ分布と本番環境での入力データの分布が変化すること。別名 Feature drift, covariant shift …
例えば、新規ユーザーの購買確率を予測するモデルを考えたときに、ある時点を境にユーザーの獲得チャネルが変わったとする。以前は検索広告が中心だったが、SNS広告からの流入が増えてきた、等
学習時にはSNS広告での流入ユーザーが少なく、SNS広告ユーザーに対する予測性能があまり良くないモデル出会った場合、その比率が多くなってくると当然モデルの性能が劣化する。
● Concept drift
Concept drift: 予測対象の目的変数の意味 / 概念 / 統計的特性が学習時から変化すること。(ちょっとわかりづらい)
[2] によると、Concept drift は"Gradual concept drift", "Sudden concept drift", "Recurring concept drift" の 3 種類に分けられる。
Gradual concept drift は前提の変化が徐々に影響していくような concept drift。
例えば機器の品質を予測するモデルにおいて、対象の機器が時間が立つにつれて摩耗していくことで、特徴量は一緒でも予測性能が下がってしまう。あるいは売上を予測するモデルにおいて、競合他社が新製品を発売してその認知が市場に広がっていくことが徐々に影響していき、売上予測の精度が下がる、など。
どれくらい早く劣化していくか?については状況によりけりではあるが、デプロイ前に過去のデータシミュレーションをして事前にあらい見積を建てる事ができる。
Sudden concept drift は変化が急に影響する concept drift
Covid 19 がわかり易い例で、例えばネットショッピングをあまり利用しなかった人が急に利用するようになったことで、クレジットカードの使用方法が急激に変化し、クレジットカード利用の不正検知システムがワークしなくなる。あるいはアプリの UI が大幅に変わってしまうなど。
この場合は、変化後の環境でまたデータを集め直す必要があり、データが集まるまではモデルは停止したほうが良い。(そういった意味でも、ML を導入する際にはまずルールベースのロジックをいれて何かあったときにすぐ停止してたち戻れるのがよさそう。)
Recurring concept drift は周期的に現れる concept drift
例えば年間を通じてあまり買い物しないけれども、ブラックフライデーにはいっぱい買う。企業チャットツールのおけるメッセージ投稿数が週末になると少なくなる。といったこと。
これらは concept drift としてモニタリングしていこうね、というよりは事前に周期性を特徴量としてモデルに組み込んで上げるのが良い。
Software Engineering Issues
データの問題だけではなく、ソフトウェアエンジニアリングの観点で考慮しないといけない点も多々ある。チェックしたい点は下記の通り
リアルタイム推論かバッチ推論か
推論環境はクラウドか、あるいは Edge / Browser か
どれだけの Computer Resources(CPU / GPU / memory)を使用できるか
レイテンシーやスループット
ロギング
セキュリティとプライバシー要件
Deployment patterns
デプロイの方法にはいくつかのパターンがあり、ユースケースごとにデプロイパターンが変わってくる。(もともと予測システムがある場合, ない場合。もともと人が行っていたタスクである場合, そうでない場合。)
● デプロイパターン1 - Shadow mode deployment
システムのユーザーに対して知らせず、こっそりとシステムに組み込んでおく。はじめは ML の予測結果を何の意思決定にも使用しない。
そうすることで、shadow mode の期間においてシステムの予測結果と人間の意思決定結果の両方のデータが揃うことになり、これをもってより ML システムの信頼性を担保した上で展開していくことができる。
● デプロイパターン2 - Canary deployment
例えば全体の 5% といったスモールトラッフィクに対してのみ初期は ML を意思決定に利用する。
システムをモニタリングして安定性・信頼性を確認しながら徐々に対応するトラフィックを増やしていく。
● デプロイパターン3 -Blue Green deployment
Router を介して「昔のシステム(Blue version)」と「新しいMLシステム(Green version)」のどちらにインプットデータを送るか制御できるようにする。 ※ 既に古い予測システムがサービスで稼働している前提
Green version に切り替えたい際には、ルーターが Blue version にデータを送るのをやめて、一気に Green version に送るようにする。100% を一気に切り替えるのではなく、もっと緩やかに変更する方法ももちろんOK
ロールバックが容易な点が利点。
Andrew 先生曰く、導入するかしないかの 01 で考えるのではなく、MLでの意思決定の自動化の程度を考慮して決めるとよい。ML による自動化の程度には次のようなグラデーションがある。
human only: ML を全く使わない
shadow mode: オペレーションは human only と同じだが、裏で ML を稼働させる
AI assistance: ML は意思決定のサポートのみに利用し、最終的な意思決定はすべて人が行う
Partial automation: 最終的な意思決定の一部を ML に任せる(信頼性の高い予測結果だけ自動化し、信頼性の低いもののみを人が判断する、等)
Full automation: 意思決定を完全に ML に任せる
最終的なゴールをどこにするにせよ、(上から下に)段階的に進めていくのが安全。
Monitoring
MLシステムの性能を監視するにあたって一般的な方法は、メトリクスを定義した上でダッシュボードでモニタリングすること。
ではどんなメトリクスをモニタリングするのか?という点については、問題が発生する可能性のあるすべての事柄についてブレインストーミングして決める。例えば、「ユーザーのトラフィックが急増し過負荷でさばききれなくなる」懸念があれば、「サーバーの負荷率」というメトリクスを見るのが良い。はじめにたくさんの種類のメトリクスを上げて追跡し、時間が経ってそれが有用でないとわかったらモニタリング対象から削除していく。
モニタリングするメトリクスの例としては…
Software Metrics: memory, compute, latency, throughput, server load …
Input metrics: 入力データの分布の変化を捉えられるような指標。Avg input length(音声認識の場合), Avg input volume, 欠損の数・割合(構造化データの場合), Avg image brightness(画像認識の場合)…
output metrics: MLがうまく機能しているか捉えられるような指標。
(ウェブ検索の場合)CTR -> 検索結果に満足しなかったことを反映している
(音声認識の場合)タイピングに切り替えた回数 -> 音声システムの結果に満足しなかったことを反映
試行錯誤の上、モニタリングするメトリクスが固まったら、アラートを出す閾値を設定する。
Pipeline monitoring
多くのAIシステムでは、単一の ML モデルで構成されているわけではなく、複数のステップから構成されている。例えば音声認識システムの場合には、「誰かが話しているかどうかの判定」 -> 「話している内容の文字起こし」といった形で 2 段階の処理が行われる。この場合 1 つめのモジュールの出力の変化が 2 つめのモジュールの出力にも影響する。そのため、監視するメトリクスには、パイプラインの各コンポーネントとパイプライン全体に対するソフトウェア・メトリクスを考慮すると良い。
References
[1] Introduction to Machine Learning in Production
[2] Machine Learning in Production: Why You Should Care About Data and Concept Drift
[3] Sculley et al. Hidden Technical Debt in Machine Learning Systems, 2015
この記事が気に入ったらサポートをしてみませんか?