
第3章「阪神ファン-巨人ファンの2大勢力構造は本当か?」のベイズモデリングをPyMC Ver.5 で

この記事は、テキスト「たのしいベイズモデリング」の第3章「阪神ファン-巨人ファンの2大勢力構造は本当か?」のベイズモデルを用いて、PyMC Ver.5で「実験的」に実装する様子を描いた統計ドキュメンタリーです。
独特な確率分布「50過剰打ち切り正規分布」を利用したR・StanモデルをPyMCに翻訳できるのでしょうか!?
無事モデリングできた暁には、プロ野球ファンの気持ちが等高線図に現れます!
難しいことは抜きにして、ベイズ推論を楽しみましょう!
テキストの紹介、引用表記、シリーズまえがき、PyMC等のバージョン情報は、このリンクの記事をご参照ください。
テキストで使用するデータは、R・Stan等のサンプルスクリプトとともに、出版社サイトからダウンロードして取得できます。
サマリー
テキストの概要
執筆者 : 清水裕士 先生
モデル難易度: ★★★★★ (難しい)
自己評価
評点
$$
\begin{array}{c:c:c}
実装精度 & ★・・・・& 悪い\\
結果再現度 & ★・・・・& NG\ !! \\
楽しさ & ★★★★・ & 楽しそう \\
\end{array}
$$

評価ポイント
「50過剰打ち切り正規分布」のモデルは記述できた気がします(気がするだけです…)が、事後分布からのサンプリングが全然ダメでした。
「PyMCの実装」は失敗例としてご活用下さい(泣)とにかく$${\hat{R}}$$が非常に悪いです。収束できないです(泣)
工夫・喜び・反省
収束しない原因が分からず、独りでは改善できない状況です。
どうか応援をお願いします(泣)「0~100の感情温度」「無関心の50」というデータ生成メカニズムを受けて立ち上る確率モデル「50過剰打ち切り正規分布」に感動しました!
モデルの概要
テキストの調査・実験の概要
次の書籍に関連して収集されたセ・リーグ6球団に対する社会的態度のデータを用いて、回答者527名が6球団に抱く「感情温度」を「多次元展開法」で分析し、阪神ファン-巨人ファンの2大勢力の構造の存在有無を確認しています。
感情温度による社会的態度の測定手法のイメージです。

テキストのモデリング
■目的変数と関心のあるパラメータ
目的変数$${Y_{ij}}$$は球団$${j}$$に対する回答者$${i}$$の「感情温度」です。
ベイズ推論で分析するパラメータは、回答者と各球団との2次元空間の距離感であり、回答者の座標$${\theta_{ik}}$$と球団の座標$${\delta_{jk}}$$です。
地図に回答者と球団をマッピングする感じです。

■50過剰打ち切り正規分布モデル
感情温度データは次の3つの峰を持つようです。
好意も反感も持たず、プロ野球に関心のない「50」を回答
無関心の確率$${\gamma_i}$$の50と、関心ありの確率$${1-\gamma_i}$$の50が含まれると想定されます。
つまり、50の確率が過剰に(異常に)高くなります【50過剰】。マイナスの反感値を回答できないため仕方なく「0」を回答
感情温度0には、実質マイナスの分布も含まれると想定されます。
つまり、0で【打ち切り】となり、0の確率が高くなります。100超の好意値を回答できないため仕方なく「100」を回答
感情温度100には、実質100超の分布も含まれると想定されます。
つまり、100で【打ち切り】となり、100の確率が高くなります。

これらの特徴を入れ込んだのが「50過剰打ち切り正規分布」です。
$$
P(Y_{ij} \mid \mu_{ij},\ \sigma_j)=
\begin{cases}
\gamma_i + (1 - \gamma_i)\ \text{Normal}(50 \mid \mu_{ij},\ \sigma_j) & (Y_{ij}=50) \\
(1 - \gamma_i)\ \text{NormalCDF}(0 \mid \mu_{ij},\ \sigma_j) & (Y_{ij}=0) \\
(1 - \gamma_i)\ \text{NormalCCDF}(100 \mid \mu_{ij},\ \sigma_j) & (Y_{ij}=100) \\
(1 - \gamma_i)\ \text{Normal}(Y_{ij} \mid \mu_{ij},\ \sigma_j) & (otherwise) \\
\end{cases}
$$
1行目が「50過剰」、2・3行目が「打ち切り(Censored)」に相当します。
目的変数$${Y_{ij}}$$の値によって適用する確率関数が変わるということです(難しいのね・・・)
$${\gamma_i}$$は回答者$${i}$$がプロ野球に無関心である確率です。
正規分布の平均パラメータ$${\mu_{ij}}$$は回答者$${i}$$と球団$${j}$$の単位、標準偏差パラメータ$${\sigma_j}$$は球団$${j}$$の単位です。
■多次元展開法
正規分布の平均パラメータ$${\mu_{ij}}$$に回答者と球団の距離に基づく座標を持たせます。
$$
\mu_{ij}=\alpha - \beta\ d_{ij}(\theta_{ik},\ \delta_{jk})
$$
$${\theta_{ik}}$$は$${K=2}$$次元空間の回答者$${i}$$の座標、$${\delta_{jk}}$$は$${K=2}$$次元空間の球団$${j}$$の座標です。
地図にプロットする際、回答者$${i}$$の$${x,\ y}$$座標は$${(\theta_{i1},\ \theta_{i2})}$$というような感じです。
回答者と球団のユークリッド距離$${d_{ij}}$$は次式で求めます。
$$
d_{ij}(\theta_{ik},\ \delta_{jk}) = \sqrt{\sum^K_{k=1} (\theta_{ik} - \delta{jk})^2}
$$

■パラメータの事前分布
$${\theta_{ik},\ \delta_{jk}}$$の事前分布は0を中心として範囲$${R=3}$$の一様分布と仮定しています。
$$
\theta_{ik} \sim \text{Uniform(-3, 3)} \\
\delta_{jk} \sim \text{Uniform(-3, 3)} \\
$$
$${\alpha,\ \beta}$$は範囲の広い一様分布を仮定し、$${\beta>0}$$としています。
■分析結果
分析結果はテキストに記載のとおりです。
今回のPyMCモデリングでは事後分布が収束しておらず、ブログ掲載の分析情報は当てにならないです(スミマセン・・・)。

PyMC実装
Let's enjoy PyMC & Python !
準備・データ確認
1.インポート
### インポート
# ユーティリティ
import pickle
# 数値・確率計算
import pandas as pd
# PyMC
import pymc as pm
import pytensor.tensor as pt
import arviz as az
# 描画
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'Meiryo'
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')2.データの読み込み
csvファイルをpandasのデータフレームに読み込みます。
# データの読み込み
data_orgn = pd.read_csv('baseball_team.csv')
data_orgn【実行結果】
インデックスを回答者のIDに用います。
G::巨人、T:阪神、C:広島、D:中日、DB:横浜、S:ヤクルトに感情温度が記録されています。

3.データの外観・統計量
まず、球団ごとの要約統計量を確認します。
### 要約統計量の表示
data_orgn.describe().round(2)【実行結果】
25%点に注目です。G(巨人)は0。もしやアンチ・・・。

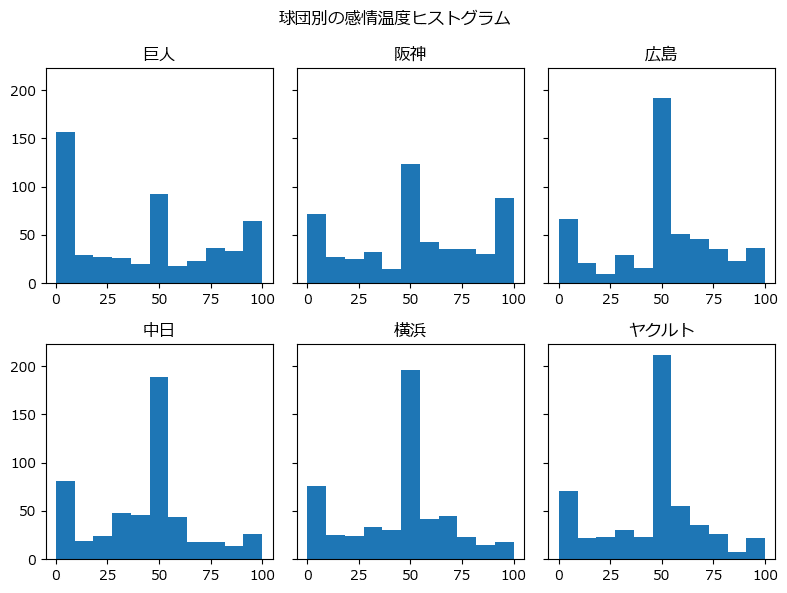
球団ごとのヒストグラムを確認しましょう
### ヒストグラムの描画
# 球団名リストの作成
team_list = ['巨人', '阪神', '広島', '中日', '横浜', 'ヤクルト']
# 描画
fig, ax = plt.subplots(2, 3, figsize=(8, 6), sharey=True)
# 球団ごとにヒストグラムを描画
for i, team in enumerate(data_orgn.columns):
ax[divmod(i, 3)].hist(data_orgn[team], bins=11)
ax[divmod(i, 3)].set_title(team_list[i])
# 修飾
plt.suptitle('球団別の感情温度ヒストグラム')
plt.tight_layout()
plt.show()【実行結果】
全球団が0、50、100に3つの峰を持っています。
巨人は0が多いです。
0過剰です。アンチ票が多かったのかもしれません。
広島・中日・横浜・ヤクルトは50が極端に多いです。
興味なしの50が多いのかもしれません。
テキスト図3.1のヒストグラムを描画しましょう。
### 阪神タイガースに対する感情温度のヒストグラム ★図3.1に対応
# ビンを0点~100点まで1点刻みにする
bins = list(range(0, 101))
# ヒストグラムの描画
plt.hist(data_orgn['T'], bins=bins)
# 修飾
plt.title('阪神タイガースに対する感情温度のヒストグラム')
plt.xlabel('感情温度')
plt.ylabel('度数:人')
plt.show()【実行結果】
50過剰、0と100で打ち切りの特徴を持つ正規分布に近似している感じです。

4.データの前処理
ID、球団、感情温度の3列構成に変更します。
pandasのmeltを用いて、横持ちから縦持ちに変換しています。
### データの前処理
# コピー
data = data_orgn.copy().reset_index()
# 列名変更
data.columns=['ID', '巨人', '阪神', '広島', '中日', '横浜', 'ヤクルト']
# pandasのmeltを用いて、横持ちから縦持ちに変換
data = pd.melt(data, id_vars=['ID'],value_vars=data.columns, var_name='球団',
value_name='感情温度')
display(data)【処理結果】

モデル構築
モデルの数式表現
目指したいPyMCのモデルの雰囲気を混ぜた「なんちゃって数式」表記です。
パラメータの事前分布
$$
\begin{align*}
\alpha &\sim \text{Uniform}(-2, 2) \\
\beta &\sim \text{Uniform}(0, 100) \\
\theta_{ik} &\sim \text{Uniform}(-3, 3, \text{shape}=(527, 2)) \\
\delta_{jk} &\sim \text{Uniform}(-3, 3, \text{shape}=(6, 2)) \\
\sigma_{j} &\sim \text{Uniform}(0, 100) \\
\gamma_{i} &\sim \text{Uniform}(0, 1) \\
\mu_{ij} &= \alpha - \beta \ \sqrt{(\theta_{i0} - \delta_{j0})^2 + (\theta_{i1} - \delta_{j1})^2} \\
likelihood &\sim
\begin{cases}
\gamma_{i} + (1-\gamma{i})\ \text{Normal}(\text{mu}=\mu_{ij},\ \text{sigma}=\sigma_j) \quad (y_{ij}=50)\\
(1-\gamma{i})\ \text{CensoredNormal}(\text{mu}=\mu_{ij},\ \text{sigma}=\sigma_j,\ \text{l}=0,\ \text{u}=100) \quad (y_{ij} \neq 50)\\\end{cases}
\end{align*}
$$
blood_idxは変数「血液型」の値を次の整数値に置き換えたものです。
1.モデルの定義
大きく初期値や関数の定義部分とモデル定義部分に分かれます。
distance関数は$${\theta_{ik}}$$と$${\delta_{jk}}$$のユークリッド距離を計算する関数です。
custom_dist関数は50過剰打ち切り正規分布の定義部です。
### 50過剰打ち切り正規分布のモデル
# https://zenn.dev/yoshida0312/articles/7e0cfaa471b168
# 初期値設定 theta, deltaの一様分布のパラメータ定数
R = 3
# カテゴリ変数「球団」のインデックス作成
team_list = ['巨人', '阪神', '広島', '中日', '横浜', 'ヤクルト'] # 再定義
team_dict = dict(zip(team_list, [i for i in range(len(team_list))]))
team_idx = data['球団'].replace(team_dict)
# 距離計算関数の定義(多次元展開法の太陽)
def distance(theta, delta):
return pt.sqrt(pt.pow(theta[:, 0]-delta[:, 0], 2)
+ pt.pow(theta[:, 1]-delta[:, 1], 2))
# 50過剰打ち切り正規分布を実現するcustom_dist関数の定義
# yを1/100でスケーリングしているので、0.5過剰、0,1打ち切り正規分布になる
def custom_dist(
y: pt.TensorVariable,
mu: pt.TensorVariable,
sigma: pt.TensorVariable,
gamma: pt.TensorVariable,
size: pt.TensorVariable,
) -> pt.TensorVariable:
# yが0.5の場合
if pt.eq(y, 0.5):
return pm.Normal.dist(mu=mu, sigma=sigma, size=size) \
* (1 - gamma) + gamma
# yが0.5以外の場合、下限0・上限1の打ち切り:Censored正規分布を用いる
else:
distTmp = pm.Normal.dist(mu=mu, sigma=sigma)
return pm.Censored.dist(distTmp, lower=0, upper=1, size=size) \
* (1 - gamma)
# モデルの定義
with pm.Model() as model:
## データ関連定義
# coordの定義
model.add_coord('data', values=data.index, mutable=True)
model.add_coord('team', values=team_list, mutable=True)
model.add_coord('id', values=data_orgn.index, mutable=True)
model.add_coord('k', values=[1, 2], mutable=True)
# dataの定義 yは1/100にスケーリング
y = pm.ConstantData('y', value=data['感情温度'].values / 100, dims='data')
teamIdx = pm.ConstantData('teamIdx', value=team_idx, dims='data')
idIdx = pm.ConstantData('idIdx', value=data['ID'].values, dims='data')
## 事前分布
alpha = pm.Uniform('alpha', lower=-2, upper=2)
beta = pm.Uniform('beta', lower=0, upper=100)
theta = pm.Uniform('theta', lower=-R, upper=R, dims=('id', 'k'))
delta = pm.Uniform('delta', lower=-R, upper=R, dims=('team', 'k'))
sigma = pm.Uniform('sigma', lower=0, upper=100, dims='team')
gamma = pm.Uniform('gamma', lower=0, upper=1, dims='id')
## muの計算
mu = pm.Deterministic('mu',
(alpha - beta * distance(theta[idIdx, :],
delta[teamIdx, :])),
dims='data')
## 尤度:観測データ custom_dist関数で確率計算を行う
pm.CustomDist('fiftyInflatedCensoredNormal',
y, mu, sigma[teamIdx], gamma[idIdx],
dist=custom_dist, observed=y, dims='data')【モデル注釈】
coordの定義
座標に名前を付けたり、その座標が取りうる値を設定できます。
今回は次の4つを設定しました。行の座標:名前「data」、値「行インデックス」
球団の座標:名前「team」、値「巨人、阪神、広島、中日、横浜、ヤクルト」
回答者の座標:名前「id」、値「ID」
2次元空間の軸の座標:名前「k」、値「1、2」
dataの定義
目的変数である感情温度$${y}$$、球団インデックス$${teamIdx}$$、回答者インデックス$${idIdx}$$を設定しました。
なお、感情温度は$${\boldsymbol{1/100}}$$でスケーリングし直しています(Rスクリプトと同様)。パラメータの事前分布
基本的にテキスト掲載またはRスクリプト等の分布・値を使用しました。
$${\beta}$$と$${\sigma_j}$$の一様分布の上限100は「範囲の広い一様分布」の文言から推測しました。$${\mu_{ij}}$$
distance関数を参照して定義しています。
【不安要素】distance関数が適切なのかどうか不安です。尤度
custom_dist関数の「50過剰打ち切り正規分布」を参照します。custom_dist関数
Censord.dist(lower=0, upper=100)にて、下限0・上限100で打ち切りする分布を定義できます。
【不安要素】custum_dist関数が適切なのかどうか不安です。
3.モデルの外観の確認
### モデルの表示
model【実行結果】

# モデルの可視化
pm.model_to_graphviz(model)【実行結果】
「50過剰打ち切り正規分布」の名称が長かったです・・・。

MCMCの実行
1.事後分布からのサンプリング
乱数生成数(draws, tune, chains)のうち、tuneは、収束してくれることを願って、テキストのバーンイン期間1000回よりも増やしています。
nuts_sampler='numpyro'とすることで、numpyroをNUTSサンプラーに利用できます。
処理時間が130分かかるのでご注意下さい。
なお、テキストではStanの自動変分推論による推定結果を初期値として与えていますが、こちらのサンプリングでは初期値を与えていません。
### 事後分布からのサンプリング ※NUTSサンプラーにnumpyroを使用 130分
with model:
idata = pm.sample(draws=5000, tune=10000, chains=4, target_accept=0.95,
nuts_sampler='numpyro', random_seed=1234)【実行結果】省略
2.サンプリングデータの確認
$${\hat{R}}$$、事後分布の要約統計量、トレースプロットを確認します。
事後分布の収束確認はテキストにならって$${\hat{R} \leq 1.1}$$としています。
### r_hat>1.1の確認
rhat_idata = az.rhat(idata)
(rhat_idata>1.1).sum()【実行結果】
全データが収束していません!

📢 分析断念のお知らせ 📢
収束させることができないため、ベイズ推論による分析ができません。
ここからは、Pythonコードの参考例の位置づけで続行します。
事後分布の要約統計量です。
テキストの表3.1作成に相当する処理です。
### 推論データの要約統計情報の表示(MEDを除く) ★表3.1に対応
var_names = ['alpha', 'beta', 'delta', 'delta', 'sigma']
pm.summary(idata, hdi_prob=0.95, var_names=var_names).round(2)【実行結果】
mean(EAP)、sd(post.sd)はテキストと全然合っていません。

トレースプロットです。
### トレースプロットの描画
pm.plot_trace(idata, var_names=var_names, combined=True, figsize=(12, 10))
plt.tight_layout();【実行結果】
バーコードのような黒い縦線は収束していない(divergence)データを示しています。真っ黒です…(泣)
alpha、betaは峰が複数あります。

分析用コード
1.セ・リーグ6球団に対する社会的態度の構造図の作成
テキストの図3.6に近い等高線図を描画するコードです。
まず、カーネル密度推定の処理時間を短くする目的で、データを間引きます(thinning)。
sel()とslice()にて、idataから100ごとに抽出します。
### 乱数を100ごとに抽出:KDEプロット処理時間短縮のため
thinned_idata = idata.sel(draw=slice(None, None, 100))
display(thinned_idata)【実行結果】
drawが、idataの5000から1/100の50に減少しています。

等高線図を描画しましょう。
回答者の座標$${\theta}$$データをseabornのkdeplotでカーネル密度推定して等高線図を描画します。
球団の座標$${\delta}$$データは平均値を算定して、matplotlibのplotで描画します。
1分ほど時間がかかります。
### セ・リーグ球団に対する社会的態度の構造図の描画 ★図3.4に対応
## データの準備
# 回答者の座標θデータを作成 shape=(chain4*draw50*id527, 2)
thinned_id_plot = thinned_idata.posterior.theta.data.reshape(105400, 2)
# 球団の座標δ平均データを作成:shape=(6)
team_plot = idata.posterior.delta.mean(['chain', 'draw']).data
## 描画
# 回答者の座標θを二次元のKDEプロットで描画
sns.kdeplot(x=thinned_id_plot[:, 0], y=thinned_id_plot[:, 1],
fill=True, thresh=0.01, cmap='autumn', cbar=True)
# 球団の座標δ平均を描画
plt.plot(team_plot[:, 0], team_plot[:, 1], 'o', color='black')
for coord, name in zip(team_plot, team_list):
plt.annotate(name, xy=(coord[0]+0.08, coord[1]+0.08))
# 修飾
plt.title('セ・リーグ球団に対する社会的態度のKDEプロット')
plt.xlabel('Dim1')
plt.ylabel('Dim2')
plt.show()【実行結果】
色で標高の高低を表現しています。
オレンジが低い、黄色が高いです。

【分析】
事後分布からのサンプリングデータが適切では無いため、上の等高線図を用いた分析を省略します。
ぜひ、テキストの勢力図をご堪能下さい!
2.推論データ(idata)の保存
推論データを再利用することはないと思いますが、ひとまずファイルに保存しましょう。
idataをpickleで保存します。
### idataの保存 pickle
file = r'idata_ch03.pkl'
with open(file, 'wb') as f:
pickle.dump(idata, f)読み込みコードは次のとおりです。
### idataの読み込み pickle
file = r'idata_ch03.pkl'
with open(file, 'rb') as f:
idata_load = pickle.load(f)
おまけ:自動変分推論もどき
テキストで初期値を求めた自動変分推論に近づいてみよう!という事で、PyMCのADVI(自動微分変分推論)を試してみます。
いまいちADVIを理解していないので、PyMC公式サイトの参考コード通りに動かしてみます。
①モデルにADVIを適用して平均場近似データを生成
### ADVIの適用して平均場近似mean_fieldを取得
with model:
mean_field = pm.fit(method='advi')【実行結果】
損失が7300ほどあるとのこと。

②平均場近似からサンプリング
### 平均場近似mean_fieldからサンプリング
mf_sample = mean_field.sample(1000)
mf_sample【実行結果】
chain=1、draw=1000、つまり1000件のデータをサンプリングしました。

③サンプリングデータの平均値を初期値用辞書に格納
### サンプリングデータの平均値をmodelのパラメータの初期値に設定
alpha_init = mf_sample.posterior.alpha.mean().data
beta_init = mf_sample.posterior.beta.mean().data
theta_init = mf_sample.posterior.theta.mean(['chain', 'draw']).data
delta_init = mf_sample.posterior.delta.mean(['chain', 'draw']).data
sigma_init = mf_sample.posterior.sigma.mean(['chain', 'draw']).data
gamma_init = mf_sample.posterior.gamma.mean(['chain', 'draw']).data
init_vals = {'alpha': alpha_init,
'beta': beta_init,
'theta': theta_init,
'delta': delta_init,
'sigma': sigma_init,
'gamma': gamma_init,}【実行結果】なし
④初期値を指定して事後分布からのサンプリングを実行
テキストの乱数発生数と同数をサンプリングします。
tuneが少ないです。
処理時間に50分ほどかかったのでご注意下さい。
### 事後分布からのサンプリング
# initvalを指定して、テキストの乱数発生数をサンプリング 50分
with model:
idata_advi = pm.sample(draws=5000, tune=1000, chains=4, target_accept=0.95,
initvals=init_vals, nuts_sampler='numpyro',
random_seed=1234)【実行結果】省略
⑤$${\hat{R}}$$の確認
### r_hat>1.1の確認
rhat_idata_t = az.rhat(idata_advi)
(rhat_idata_t > 1.1).sum()【実行結果】
収束していないです(泣)

要約統計量は省略します。
トレースプロットを見てみましょう。
### トレースプロットの描画
pm.plot_trace(idata_advi, var_names=var_names, combined=True, figsize=(12, 15))
plt.tight_layout();【実行結果】
何らかの傾向がありそうですね・・・。

最後にテキストの一撃必殺の一文を引用させていただきます。
「思っていた分布と違う!」というときこそ、ベイズ統計モデリングの出番であるということを伝えて本章を閉じたいと思う。
「思っていた結果と違う!」結果となり、本来のモデルを実装できなくて、残念です…。
以上で第3章は終了です。
おわりに
プロ野球ファンの熱狂
全打席空振り三振、こんな気分です。
がっくし。
もしもファンがいたならば、どんな野次?応援?が飛んでくることでしょう?
次回に期待したいです。
どうか簡単なモデルでありますように🙏
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で4つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
2.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析トピックを PythonとPyMC Ver.5で取り組みます。
豊富なテーマ(お題)を実践することによって、PythonとPyMCの基礎体力づくりにつながる、そう信じています。
日々、Web検索に勤しみ、時系列モデルの理解、Pythonパッケージの把握、R・Stanコードの翻訳に励んでいます!
このシリーズがPython時系列分析の入門者の参考になれば幸いです🍀
3.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learn と PyTorch の教科書です。
よかったらぜひ、お試しくださいませ。
4.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Python のコラムを不定期に綴っています。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
ベイズ書籍の実践記録も掲載中です。
最後までお読みいただきまして、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?