垂直ハミング符号

目的
有線あるいは無線で電文を送付したり、メディアに情報を記録する場合にはエラーの検出と訂正が必ず必要になる。ここでは物理レイヤを設計するエンジニア向けに古典となるハミング符号と、それを応用した垂直ハミング符号について記す。垂直ハミング符号は筆者が考えたものだ。将来、墓石にビット列を刻むことがあるなら本ページが役に立つだろう。
符号と距離
符号とは『コード』のことである。例えば男性=0, 女性=1のように数値や記号を割り当てることを『符号化する』と言う。符号化記号として男性=u0, 女性=u1 とする。
各符号の差異のビット数のことを『距離』あるいは『ハミング距離』と呼ぶ。距離が遠いほどエラーに対する許容性が高いことは容易に想像できる。例えば
u0=00000000 // 男性
u1=11111111 // 女性としたら、この符号間の距離は8(単位はbit)である。
00100000という(一か所が化けた)電文を受信したときu0には距離1、u1には距離7なので、『u0により近い』、おそらくu0である。と判断することが出来る。逆に
u0=0 // 男性
u1=1 // 女性とした場合は距離が1なので、1bit狂っただけで隣の符号と同じになってしまう。これは距離が置かれていないという事になる。
一般的に距離がd[bit]だった場合に、(d-1)/2 bitまでの誤りを訂正できて、d-1ビットまでの誤りが検出可能である。
u0=000000 // 軽自動車
u1=000111 // 普通乗用車
u2=111000 // トラック
u3=111111 // バス
と符号化した場合、最小距離が3なので (3-1)/2 = 1bit までの誤りが修正可能で、3-1=2 bitまでの誤りが検出可能である。
ハミング符号
u1,u2,,, un までの各符号に対し、最小距離が3になるようなビット構成を考えれば1bitの誤りが修正可能で2bitの誤りが検出可能になる。
符号化
データ4bitに対して3ビットの検査ビットを付加し、合計を7ビットにする。d1~d4がデータ。c1~c3が検査ビットである。この7ビットを伝送するとき、d1~d4,c1~c3にはいずれのビットにも同じ確立で誤りが生じる可能性があるとする。

誤りの有無を確認するために偶数パリティーを3ビット用意し、s1~s3とする。 データが誤ったときの 誤りの状況をs1~s3で示すと、

s1 = d4 ^ c1 ^ c2 ^ c3 である。同様に (式1)
s2 = d2 ^ d3 ^ c2 ^ c3 (式2)
s3 = d1 ^ d3 ^ c1 ^ c3 (式3)
( ^ は xor を示す)誤りが無ければs1=s2=s3=0である。すなわち
0 = d4 ^ c1 ^ c2 ^ c3 (式4)
0 = d2 ^ d3 ^ c2 ^ c3 (式5)
0 = d1 ^ d3 ^ c1 ^ c3 (式6)が成り立つ。これをc1~c3の連立方程式として解く。
解き方はいろいろあるので例を示す。
(式4)と(式5)の両辺をxorで足す。
0 ^ 0 = (d4 ^ c1 ^ c2 ^ c3) ^ (d2 ^ d3 ^ c2 ^ c3)
0 = d4 ^ c1 ^ c2 ^ c3 ^ d2 ^ d3 ^ c2 ^ c3
ここで c2^c2=>0, c3^c3=>0なので打ち消しあい、
0 = d4 ^ c1 ^ d2 ^ d3
両辺にc1を xor で加えると
0 ^ c1 = d4 ^ c1 ^ d2 ^ d3 ^ c1
先ほどと同様にc1^c1=>0なので、整理すると
c1 = d2 ^ d3 ^ d4
が得られる。同様に解くと
c2 = d1 ^ d3 ^ d4
c3 = d1 ^ d2 ^ d4
となる。まとめると
c1 = d2 ^ d3 ^ d4 (式7)
c2 = d1 ^ d3 ^ d4 (式8)
c3 = d1 ^ d2 ^ d4 (式9)となる。c1~c3をd1~d4と共に符号化し、u1~u16の16通り(4bit)の符号に対して7bitのビットパターンを符号化する。

結果、このハミング符合は距離が3となるので1ビットのエラー訂正と2ビットのエラー検出能力を持つ。
復号化(エラー修正)
式1、式2、式3を計算する。
s1 = d4 ^ c1 ^ c2 ^ c3 (式1)
s2 = d2 ^ d3 ^ c2 ^ c3 (式2)
s3 = d1 ^ d3 ^ c1 ^ c3 (式3)s1,s2,s3は偶数パリティーである。ここで、s1=s2=s3=0の時はパリティーエラーが無いので全てのビットに誤りが無いという事になる。エラーが発生したときはs1~s3の値で示すビットが誤っている。したがって誤っているビットを反転したものが正しい値となる。
コーディング
ここではd1,c1がMSB側(上位ビット)、d4,c3がLSB側(下位ビット)としているので注意。

符号化(エンコード)
c1 = d2 ^ d3 ^ d4 (式7)
c2 = d1 ^ d3 ^ d4 (式8)
c3 = d1 ^ d2 ^ d4 (式9)普通に書くと
int hamming(int d){
int c1,c2,c3,d1,d2,d3,d4;
d1= (d>>3) & 1;
d2= (d>>2) & 1;
d3= (d>>1) & 1;
d4= (d>>0) & 1;
c1 = d2 ^ d3 ^ d4;
c2 = d1 ^ d3 ^ d4;
c3 = d1 ^ d2 ^ d4;
return d<<3 | c1<<2 | c2<<1 | c3<<0;
}である。もちろんこれでも正しい。 式(7)~(9)を表にすると

となり、●印のついたビットに関してパリティーを計算する。
従ってd1~d4の4ビットを右シフトしていき、
c1~c3を0で初期化 (int c=0)
一回目の右シフト(d4)を行い1なら
c1とc2とc3を反転 (c ^= 0b111 )
二回目の右シフト(d3)を行い1なら
c1とc2を反転 (c ^= 0b110 )
三回目の右シフト(d2)を行い1なら
c1とc3を反転 (c ^= 0b101 )
四回目の右シフト(d1)を行い1なら
c2とc2を反転 (c ^= 0b011 )これをC言語にすると以下のようになる。
int hamming2(int d){
int c=0;
if(d & 0x1)
c ^= 7; // 0b111;
if(d & 0x2)
c ^= 6; // 0b110;
if(d & 0x4)
c ^= 5; // 0b101;
if(d & 0x8)
c ^= 3; // 0b011;
return d<<3 | c;
}復号化(デコード)
s1 = d4 ^ c1 ^ c2 ^ c3 (式1)
s2 = d2 ^ d3 ^ c2 ^ c3 (式2)
s3 = d1 ^ d3 ^ c1 ^ c3 (式3)であるから、普通に書くと
int decode_hamming(int data){
int c1,c2,c3,d1,d2,d3,d4,s1,s2,s3,s;
d1 = (data>>6) & 1;
d2 = (data>>5) & 1;
d3 = (data>>4) & 1;
d4 = (data>>3) & 1;
c1 = (data>>2) & 1;
c2 = (data>>1) & 1;
c3 = (data>>0) & 1;
s1 = d4 ^ c1 ^ c2 ^ c3;
s2 = d2 ^ d3 ^ c2 ^ c3;
s3 = d1 ^ d3 ^ c1 ^ c3;
s=s1<<2 | s2<<1 | s3<<0;
if(s>0){
s--;
s=6-s; // 図では左から数えているので右から数えてのビットに直す
printf("復号化エラー bit%dが誤りです。\n",s);
data ^= 1<< s; // ビットsを反転する
}
return data>>3;
}である。もちろんこれでも正しい。 式(1)~(3)を表にすると

●印のついたビットに関してパリティーを計算する。
従ってd1~d4、c1~c3の7ビットを右シフトしていき、
s1~s3を0で初期化 (int s=0)
一回目の右シフト(c3)を行い1なら
s1とs2とs3を反転 (s ^= 0b111 )
二回目の右シフト(c2)を行い1なら
s1とs2を反転 (s ^= 0b110 )
三回目の右シフト(c1)を行い1なら
s1とs3を反転 (s ^= 0b101 )
四回目の右シフト(d4)を行い1なら
s1を反転 (s ^= 0b100 )
五回目の右シフト(d3)を行い1なら
s2とs3を反転 (s ^= 0b011 )
六回目の右シフト(d2)を行い1なら
s2を反転 (s ^= 0b010 )
七回目の右シフト(d1)を行い1なら
s3を反転 (s ^= 0b001 )
こうして得られたsに対して
if(s==0) { エラーなし }
if(s>0) { 左から s ビット目に誤り(ビット反転)がある。 }これをC言語にすると以下のようになる。
int decode_hamming2(int data){
int s=0;
if(data & 0x01)
s ^= 7; // 0b111;
if(data & 0x02)
s ^= 6; // 0b110;
if(data & 0x04)
s ^= 5; // 0b101;
if(data & 0x08)
s ^= 4; // 0b100;
if(data & 0x10)
s ^= 3; // 0b011;
if(data & 0x20)
s ^= 2; // 0b010;
if(data & 0x40)
s ^= 1; // 0b001;
if(s>0){
s--;
s=6-s; // 図では左から数えているので右から数えてのビットに直す
printf("復号化エラー bit%dが誤りです。\n",s);
data ^= 1<< s; // ビットsを反転する
}
return data>>3;
}垂直ハミング
ノイズや外乱は連続したビットを傷つけることが大半である。

従ってデータとチェックビットは時間軸方向で離れていた方が訂正率が上がる。今までは水平にデータをチェックする方法を考慮したが、垂直にチェックを設ける方法を考える。
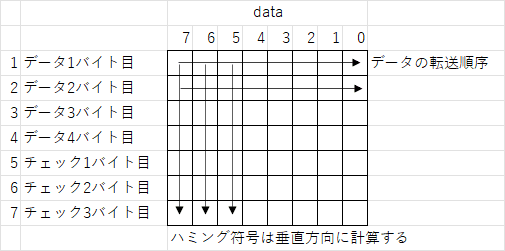
これによりバースト的に数ビットの連続データ失われても訂正確率が高まる。これを垂直ハミング方式と名付けた。1~4バイト目はデータそのものである。5,6,7バイト目をチェックバイトとする。
符号化(エンコード)
先ほどの表から、データ1~4のときに各々C1~C3を反転させればよいことが分かる。
c1~c3を初期化 (int c1=0, c2=0, c3=0)
c2 xor= d1
c3 xor= d1
c1 xor= d2
c3 xor= d2
c1 xor= d3
c2 xor= d3
c1 xor= d4
c2 xor= d4
c3 xor= d4にてc1~c3が作り出せる。
復号化(デコード)
先ほどの表より、d1,d2,d3,d4,c1,c2,c3の7バイトを受信した後、
int s1=0, s2=0, s3=0
s3 xor= d1
s2 xor= d2
s2 xor= d3
s3 xor= d3
s1 xor= d4
s1 xor= c1
s3 xor= c1
s1 xor= c2
s2 xor= c2
s1 xor= c3
s2 xor= c3
s3 xor= c3にてs1~s3を求める。、次にs1,s2,s3の各ビット毎に
(s1.bit0 << 2 + s2.bit0 << 1 + s3.bit0)
=> 0 ... 誤り無し
=> 1 ... d1.bit0が誤り
=> 2 ... d2.bit0が誤り
=> 3 ... d3.bit0が誤り
:
=> 7 ... c3.bit0が誤りのようにビット0~7について処理を行う。xorだけで演算でき恐ろしく高速である。
この記事が気に入ったらサポートをしてみませんか?