
PDFから表を抽出してエクセルに保存する Python

今回やりたいこと
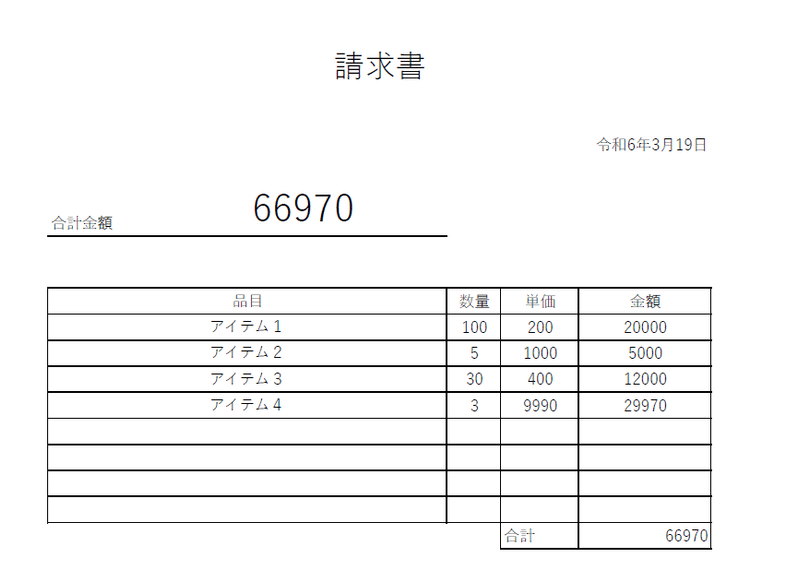
図1の請求書の表データを抜き取って、Excelに保存したい。
ライブラリ
PDFの表データを抽出するためにPyMuPDFというライブラリを使用する。
pipでのインストールは下記の通り。
pip install PyMuPDFPDFから表の抽出
PyMuPDFライブラリは、importする際、fitzという名前でimportする。ライブラリ名とimportの名前が異なるのは、歴史的経緯によるものらしい。
PDFファイルの読み込みは、fitzのopen関数を用いる。
import fitz
# PDFの読み込み
doc = fitz.open("請求書.pdf")次にPDFファイルの表データを探す。
# ページの指定
page = doc[0]
# 表データの検索
tables = page.find_tables()今回は1ページのみのファイルを想定しているので、docのところは、0を指定する。2ページ目や3ページ目がある場合は、docのところの数字をページ番号から1引いた値にすればよい。
find_tablesはページ内の表を検索する。
表データをExcelに保存
tablesで取得した表データの中身は
tables[0].extract()で取得できる。表データが複数ある場合は、tables[数値]の数値を変更することで取得できる。実際にtablesを表示すると、
[['品目', '数量', '単価', '金額'],
['アイテム1', '100', '200', '20000'],
['アイテム2', '5', '1000', '5000'],
['アイテム3', '30', '400', '12000'],
['アイテム4', '3', '9990', '29970'],
['', '', '', ''],
['', '', '', ''],
['', '', '', ''],
['', '', '', ''],
['', None, '合計', '66970']]のようにリストとなって取得できる。
1番最初の行をカラム名として、pandasを用いてデータフレームを作成する。
# 列名にするデータを取得
columns = table_data[0]
# 表のデータを取得
data_rows = table_data[1:]
# データフレームを作成
df = pd.DataFrame(data_rows, columns=columns)作成したデータフレームを表示すると、
品目 数量 単価 金額
0 アイテム1 100 200 20000
1 アイテム2 5 1000 5000
2 アイテム3 30 400 12000
3 アイテム4 3 9990 29970
4
5
6
7
8 None 合計 66970となる。このまま保存してもよいが、空白行はない方が見栄えがいいので、削除する。
空白行を削除するには、空白セルをnanに置き換えると、dropnaを用いて簡単に削除できる。
df1 = df.replace("", np.nan) # nanに置き換え
df2 = df1.dropna(how="all") # すべての列がnanの行を削除これによって、
品目 数量 単価 金額
0 アイテム1 100 200 20000
1 アイテム2 5 1000 5000
2 アイテム3 30 400 12000
3 アイテム4 3 9990 29970
8 NaN None 合計 66970となり、空白行を消すことができた。
あとは、to_excelを用いてExcelファイルに保存すればよい。
# データフレームをExcelに保存
df2.to_excel("請求書.xlsx", index=False)コード全体
import fitz
import pandas as pd
import numpy as np
# PDFの読み込み
doc = fitz.open("請求書.pdf")
# ページの指定
page = doc[0]
# 表データの検索
tables = page.find_tables()
if tables.tables:
table_data = tables[0].extract()
# 列名にするデータを取得
columns = table_data[0]
# 表のデータを取得
data_rows = table_data[1:]
# データフレームを作成
df = pd.DataFrame(data_rows, columns=columns)
df1 = df.replace("", np.nan) # nanに置き換え
df2 = df1.dropna(how="all") # すべての列がnanの行を削除
# データフレームをExcelに保存
df2.to_excel("請求書.xlsx", index=False)サイト
https://sites.google.com/view/elemagscience/%E3%83%9B%E3%83%BC%E3%83%A0
この記事が気に入ったらサポートをしてみませんか?