リクルートからも日本語CLIPが来た! recruit-jp/japanese-clip-vit-b-32-roberta-base を使って、ローカルの画像を日本語で検索してみる

一昨日、Googleのmultiligual SigLIPを使って画像検索する記事を書いたところで、なんと、昨日、リクルートからも日本語対応のCLIPが出ました。しかも商用可能なCC-BY-4.0ライセンス!ヤバい。今年はローカルで動くマルチモーダルがアツい年になりそうです。
CLIPとはスーパー雑に言えば、画像とテキストを同じ空間のベクトルにできるモデルで、テキストと画像が「近いか」を判定したりできます。この性質を利用して、任意のテキストタグで画像を分類したりできます。
というわけで、一昨日の記事と同じように、リクルートの日本語対応CLIPを使って、画像検索をするスクリプトをシュッと作ってみました。
↑一昨日の記事
Google Drive → AI → recruit-clip → images に、画像がたくさん保存されているとします。私は自分のスマホで撮った写真を500枚ほど入れました。作業ディレクトリは /content/drive/MyDrive/AI/recruit-clip としています。Google Colabで動きます。
!pip install pillow requests transformers torch torchvision sentencepiece ftfy gradio typingfrom google.colab import drive
drive.mount('/content/drive')%cd /content/drive/MyDrive/AI/recruit-clip/# imagesフォルダ内の画像をすべてベクトル化してJSONに保存する
import os
import glob
from tqdm import tqdm
import json
import io
import requests
import torch
import torchvision
from PIL import Image
from transformers import AutoTokenizer, AutoModel
model_name = "recruit-jp/japanese-clip-vit-b-32-roberta-base"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True).to(device)
def _convert_to_rgb(image):
return image.convert('RGB')
preprocess = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=224, interpolation=torchvision.transforms.InterpolationMode.BICUBIC, max_size=None),
torchvision.transforms.CenterCrop(size=(224, 224)),
_convert_to_rgb,
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073], std=[0.26862954, 0.26130258, 0.27577711])
])
def tokenize(tokenizer, texts):
texts = ["[CLS]" + text for text in texts]
encodings = [
# NOTE: the maximum token length that can be fed into this model is 77
tokenizer(text, max_length=77, padding="max_length", truncation=True, add_special_tokens=False)["input_ids"]
for text in texts
]
return torch.LongTensor(encodings)
# imagesフォルダの中身の画像を全てembeddingに変換
image_features = []
for image in tqdm(glob.glob("./images/*")):
# imageが画像ファイルでないならスキップ
if not image.endswith(('.jpg', '.png', '.jpeg')):
continue
# imageのファイルネームを取得
filename = os.path.basename(image)
try:
image = Image.open(image)
image = preprocess(image).unsqueeze(0).to(device)
with torch.no_grad():
embedding = model.get_image_features(image)
embedding = embedding / embedding.norm(dim=-1, keepdim=True)
image_features.append({'embedding': embedding,
'filename': filename})
except:
print('error: ' + filename)
continue
# print(image_features[0])
# image_featuresを文字列に変換
image_features_json = []
for image_feat in image_features:
image_features_json.append({'embedding': image_feat['embedding'].tolist(),
'filename': image_feat['filename']})
# image_featuresをJSONに保存
with open('recruit_images_features.json', 'w', encoding='utf-8') as f:
json.dump(image_features_json, f, indent=4)# 画像検索UIをGradioで起動
import re, torch, gradio as gr
from typing import Union, List
# image_featuresをJSONから読み込み
with open('recruit_images_features.json', 'r', encoding='utf-8') as f:
image_features_json = json.load(f)
print(len(image_features_json))
# image_features_jsonをimage_featuresに変換
image_features = []
for image_feat in image_features_json:
image_features.append({'embedding': torch.tensor(image_feat['embedding']).to(device),
'filename': image_feat['filename']})
def find_similar_image_and_display(query: str):
text_tokens = tokenize(tokenizer, texts=[query]).to(device)
with torch.inference_mode():
text_features = model.get_text_features(input_ids=text_tokens)
text_features /= text_features.norm(dim=-1, keepdim=True)
# 画像の特徴量とテキストの特徴量の間のコサイン類似度を計算
cos_similarities = torch.stack([torch.nn.functional.cosine_similarity(
text_features[0], img_feat['embedding'], dim=-1
) for img_feat in image_features]).squeeze()
# cos_similaritiesが空でないことを確認
if len(cos_similarities) == 0:
return []
top_k = min(4, len(cos_similarities))
try:
top_sim_indices = cos_similarities.topk(top_k, largest=True).indices
selected_images = [image_features[idx]['filename'] for idx in top_sim_indices]
except RuntimeError as e:
print("Runtime error occurred:", e)
return []
# 画像のファイルパスを返す
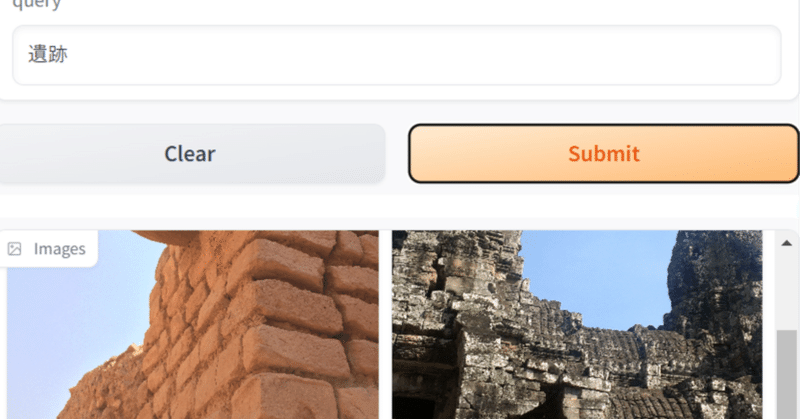
return [f"images/{filename}" for filename in selected_images]
# Gradioインターフェースの出力を変更
iface = gr.Interface(
fn=find_similar_image_and_display,
inputs="text",
outputs=gr.Gallery(label="Images")
)
iface.launch()無事、検索することができました。
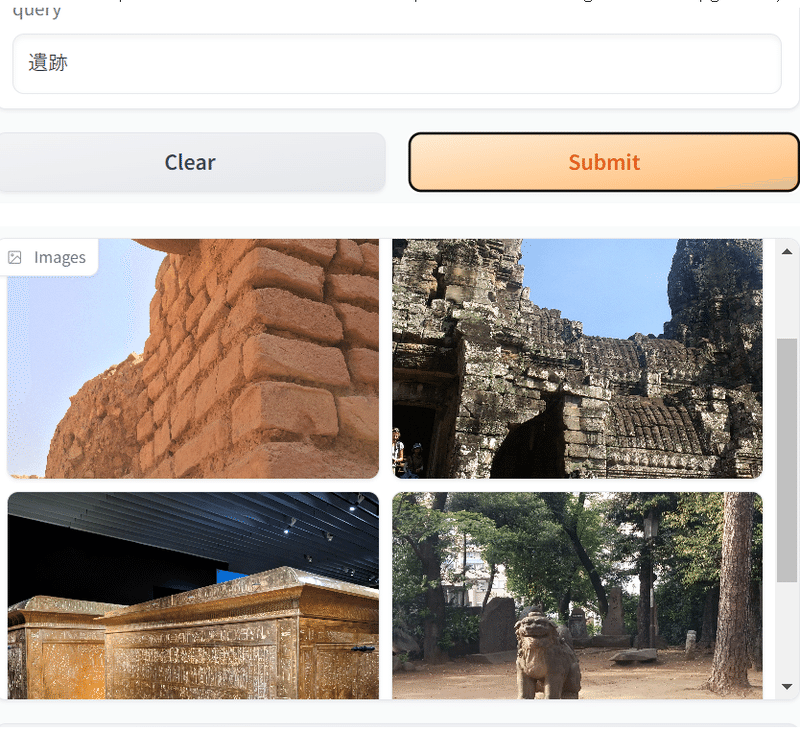
ソースコードを見ての通り、文字列は77トークンまでなので、あまり長文は入力できません。タグ付けには十分な長さだと思います。
また、今回のリクルートさんのモデルは、同時に評価用データセットが公開されたこともアツいと思います。
マルチモーダルをLLMに活用するには、評価データセットが不可欠だと思うので、こうした活動には本当に頭が下がる思いです。日本語圏で利用されている画像に適したマルチモーダルAIが発展することを期待しています。
ちなみに、CLIPは画像とテキストでしたが、同様に、音とテキストを結びつけるCLAPというモデルもLAIONから提案されています。
今後は、どこかの研究室か企業から、日本語対応CLAPも出てきそうな気がします。今年はローカルマルチモーダルがアツい!(多分)
この記事が気に入ったらサポートをしてみませんか?