
ReazonSpeech v2, whisper-large v3, nue-asrを比較してみた

今年2024年の2月14日に、日本語音声の文字起こしエンジンReazonSpeechのv2がリリースされました。NVIDIAのNemoを採用し、学習データセットも強化され、Fast Conformerという手法により高速化されたそうです。強そう。
同じく今年の1月に、transformersが4.73になり、OpenAIによる文字起こしエンジンwhisperが、transfomersでBatched state-of-the-art long-form transcriptionに対応したそうです。LLM勢が慣れたtransformersのpipelineを使えるは嬉しい。
昨年2023年の12月には、rinna社からGPT-NeoXを利用した文字起こしエンジンのnue-asrが登場しています。nueは鵺(妖怪の ぬえ)から名付けられたそうです。
いずれもApache 2.0またはMITライセンスで提供されており、商用利用含めて無料で利用出来ます。
この2ヵ月ちょっとで一気に進展があったので、比較してみることにしました。
比較材料
普段使いを想定し、私がいつもオンラインミーティングに使っている普通の会議用マイクで、しゃべりのプロでも何でもない中年男性(私)がボソボソと吹き込んだ音声をテスト材料とします。文章も、この世に存在したことがない脈絡の無い文章のほうがテストしがいがあるだろうと思い、土星で発達した猫の文明というお題でChatGPTに生成してもらった文章を読み上げました。
音声の長さは2分35秒です。
先にざっとしたまとめ
jiwerというpythonのライブラリを使い、あくまでも簡易的にワードエラーレート(WER)を出してみました。比較対象として、クラウドサービスであるLINE CLOVA Noteによる文字起こしのエラーレートも出しました。
ReazonSpeech v2 WER: 0.05472636815920398
whisper large v3 WER: 0.06633499170812604
nue-asr WER: 0.19402985074626866
line clova note WER: 0.05638474295190713
2分35秒の音声をローカルPC(RTX4090環境)でテキスト化するのにかかった時間は以下です。モデルのロード時間は含まず処理時間のみです。
ReazonSpeech v2: 10.606995105743408 秒
whisper large v3: 6.07532000541687 秒
nue-asr: 10.26275110244751 秒
ReazonSpeech v2、かなりいい!
以下に、各エンジンをPtyhonで動かしたときのサンプルコードを載せます。
ReazonSpeech v2
以下のクイックスタートガイドの通りに進めます。
注意点としては、ffmpegとCythonをインストールしておく必要があることでしょうか。
# Pythonのvenv環境作成
python3 -m venv venv
source venv/bin/activate
# ffmpegとCythonをインストール
sudo apt install ffmpeg
pip install Cython
# インストール
git clone https://github.com/reazon-research/ReazonSpeech
pip install ReazonSpeech/pkg/nemo-asr動かし方は、HowToガイドにある以下のPythonコードで動きます。speech-001.wavのところを文字起こししたい音声ファイルにしてください。
from reazonspeech.nemo.asr import load_model, transcribe, audio_from_path
# 実行時にHugging Faceからモデルを取得します (2.3GB)
model = load_model(device='cuda')
# ローカルの音声ファイルを読み込む
audio = audio_from_path('speech-001.wav')
# 音声認識を適用する
ret = transcribe(model, audio)
print(ret.text)Whisper large v3をtransformersで
whisperをtransformersで動かすのは、サンプルコードの通りにやりました。
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True,
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=30,
batch_size=16,
return_timestamps=True,
torch_dtype=torch_dtype,
device=device,
)
result = pipe("土星猫文明.wav", generate_kwargs={"language": "japanese"})
print(result["text"])ちなみに、flash attention 2を使ったり、タイムスタンプを付けたりと、オプションも豊富なようです。
nue-asr
nue-asrは、2分35秒であっても長すぎて入力できず、30秒ごとに区切ってもなお「The input audio is 30.0 sec, but such long audio inputs may degrade recognition accuracy. It is recommended to split the audio into shorter segments.」と怒られたので、10秒ごとに区切って渡すことにしました。pydubというpythonで音声ファイルを扱えるライブラリを使っています。
どうしても区切り目で認識精度が低下するので、nue-asrの見かけ上のワードエラーレートが高くなってしまった原因だと感じています。発話の切れ目でファイルを切るなどの工夫できれば、一気にエラーレートは下がりそうです。
pip install pydub
pip install git+https://github.com/rinnakk/nue-asr.git
で必要なライブラリをインストールしておきます。
import nue_asr
from pydub import AudioSegment
import os
model = nue_asr.load_model("rinna/nue-asr")
tokenizer = nue_asr.load_tokenizer("rinna/nue-asr")
# 音声ファイルを読み込む
audio = AudioSegment.from_wav("土星猫文明.wav")
# 10秒ごとに分割
chunks = [audio[i:i+10000] for i in range(0, len(audio), 10000)]
# 分割した音声ファイルを保存
for i, chunk in enumerate(chunks):
chunk.export(f"chunk{i}.wav", format="wav")
# 分割した音声ファイルを順次処理
results = []
for i in range(len(chunks)):
result = nue_asr.transcribe(model, tokenizer, f"chunk{i}.wav")
results.append(result.text)
# 得られた文字を結合
combined_text = ' '.join(results)
# 結果をテキストファイルに保存
with open("combined_result.txt", "w", encoding="utf-8") as f:
f.write(combined_text)
# 分割した音声ファイルを削除
for i in range(len(chunks)):
os.remove(f"chunk{i}.wav")
print(combined_text)比較の方法(超簡易的)
文字起こしの比較は、ワードエラーレートというものを使うことが多いようです。jiwerというワードエラーレートを計算してくれるライブラリがあったので、こちらを使うことにしました。
jiwerは外国で開発されたものなので、単語区切りはスペースがあることを前提としています。そこで、janomeで形態素解析を行い、単語間にスペースを入れています。
また、句読点や改行は削除する前処理を入れています。
import unicodedata
import re
from jiwer import wer
from janome.tokenizer import Tokenizer
def preprocess_text(text):
# 句読点を除去し、全角文字を半角に統一する
text = unicodedata.normalize("NFKC", text)
# 句読点、空白、改行を除去
text = re.sub(r'[\s。、,.]', '', text)
return text
# 日本語テキストの前処理と単語分割
def preprocess_and_tokenize_japanese(text):
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text)
words = [token.surface for token in tokens]
return ' '.join(words)
# 元の台本テキストファイルを読み込む
with open("original_text.txt", "r", encoding="utf-8") as f:
original_text = f.read()
original_text = preprocess_text(original_text)
original_text = preprocess_and_tokenize_japanese(original_text)
# nueの文字起こしテキストファイルを読み込む
with open("nue_result.txt", "r", encoding="utf-8") as f:
nue_reslut = f.read()
nue_reslut = preprocess_text(nue_reslut)
nue_reslut = preprocess_and_tokenize_japanese(nue_reslut)
# whisperの文字起こしテキストファイルを読み込む
with open("whisper_result.txt", "r", encoding="utf-8") as f:
whisper_result = f.read()
whisper_result = preprocess_text(whisper_result)
whisper_result = preprocess_and_tokenize_japanese(whisper_result)
# reazonspeechの文字起こしテキストファイルを読み込む
with open("reazon_result.txt", "r", encoding="utf-8") as f:
reazon_result = f.read()
reazon_result = preprocess_text(reazon_result)
reazon_result = preprocess_and_tokenize_japanese(reazon_result)
# LINE Clova Noteの文字起こしテキストファイルを読み込む
with open("lineclovanote.txt", "r", encoding="utf-8") as f:
lineclovanote = f.read()
lineclovanote = preprocess_text(lineclovanote)
lineclovanote = preprocess_and_tokenize_japanese(lineclovanote)
print(f"original: {original_text[:300]}")
print(f"whisper: {whisper_result[:300]}")
print(f"nue: {nue_reslut[:300]}")
print(f"reazon: {reazon_result[:300]}")
print(f"lineclovanote: {lineclovanote[:300]}")
whisper_wer = wer(original_text, whisper_result)
nue_wer = wer(original_text, nue_reslut)
reazon_wer = wer(original_text, reazon_result)
lineclovanote_wer = wer(original_text, lineclovanote)
print(f"whisper WER: {whisper_wer}")
print(f"nue WER: {nue_wer}")
print(f"reazon WER: {reazon_wer}")
print(f"lineclovanote WER: {lineclovanote_wer}")これにより出したものが、この記事の最初のほうに入れたワードエラーレート(WER)です。私はこの辺は完全に素人なので、やり方が間違っていたら大変申し訳ありません。あくまでも簡易的な比較というコトで…。
長時間だとどうなのか?
試しに手元にある2時間13分の私的な音声ファイルを上記スクリプトのまま渡してみたところ、whiper large v3は普通に完走しました。そもそもpipelineのところで chunk_length_s=30, と30秒ごとに切断するようにしているので、長時間のファイルでも変わらないのでしょう。
ReazonSpeech v2の場合、長いファイルをそのまま読み込んだようなので、24GBのVRAMから溢れ、共有メモリも利用する状況になりました。なので、とてもとても時間がかかりました…。
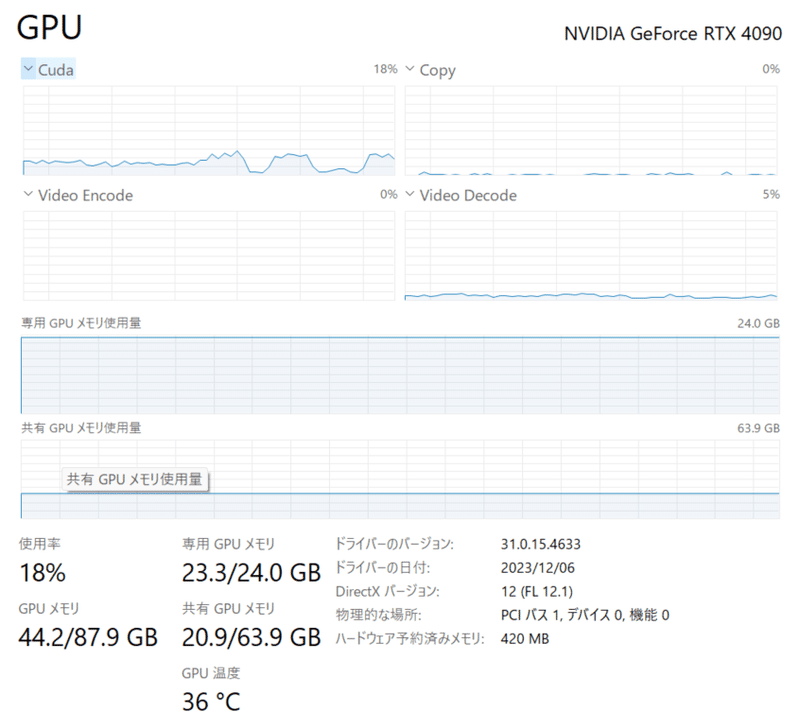
Nue-asrは2分35秒のファイルも細切れにしないといけなかったので、テストしていません。
実際に文字起こしされたテキストデータ
以下に、文字起こしの結果を貼ります。それぞれの傾向がわかるかもしれません。
元の台本
かつて、この宇宙の遥か彼方、土星の美しい輪の中に、猫たちが築き上げた高度な文明が存在した。彼らは地球上の猫とは異なり、高度な知能とテクノロジーを持ち合わせていた。この物語は、我々人類には想像もつかないような、猫たちの土星文明の歴史と文化についての探求である。
土星猫文明の始まりは、数万年前にさかのぼる。彼らは自然と調和しながら、独自の科学と哲学を発展させた。土星の輪を利用してエネルギーを得る技術、星間旅行を可能にする航法、そして、意識を共有することで社会を形成する独自のシステムが発展していった。
彼らの社会は、共感と理解を基盤として成り立っていた。猫たちは言葉を超えたコミュニケーションを行い、個々の意識を一つに結びつけることで、高度な社会的結束力を実現していた。この結束力こそが、土星猫文明が他の星の文明と平和的に交流する基盤となっていた。
しかし、彼らの文明は繁栄の中にも脆さを秘めていた。土星の輪が変化する宇宙のサイクルによって、彼らの生活基盤が脅かされることがあった。そのたびに、猫たちは団結し、知恵を絞って危機を乗り越えてきた。これらの困難を乗り越える中で、彼らはさらに強く、賢くなっていった。
猫たちの技術の中でも、特に注目すべきは彼らの建築技術である。土星の輪の物質を利用して建てられた彼らの都市は、宇宙の壮大な景観の中でもひときわ美しい。これらの都市は、猫たちの文化と哲学を反映したデザインが特徴で、和と調和の精神が込められていた。
文化面では、猫たちは音楽と舞踊を特に重視していた。彼らの音楽は、宇宙の調和と共鳴する特別な周波数を用いて作られており、聴く者の心と魂を癒やし、高める力があると言われている。舞踊は、宇宙との一体感を表現するためのもので、非常に複雑で美しい動きで構成されていた。
最終的に、土星猫文明は、彼らの知識と技術を宇宙の他の文明と共有することを決意した。彼らは、平和と調和のメッセージを持って、遠く離れた星々へと旅を続けている。地球にも彼らの影響が及び、古代の猫が持つ不思議な力や知恵は、実は土星からの訪問者の遺産かもしれないという説もある。
このようにして、土星の猫たちは宇宙の歴史にその名を刻んでいる。彼らの物語は、遥か彼方の星に住む我々人類にも、共感と理解、そして平和の大切さを教えてくれる。土星猫文明の先駆者たちの精神は、今も宇宙のどこかで生き続けており、我々の心にも響くメッセージとして残っているのである。
ReazonSpeech v2
かつてこの宇宙のはるかかなた土星の美しい輪の中にネコたちが築き上げた高度な文明が存在した彼らは地球上のネコとは異なり高度な知能とテクノロジーを持ち合わせていたこの物語は我々人類には想像もつかないような猫たちの土星文明の歴史と文化についての探求である土星猫文明の始まりは数万年前にさかのぼる彼らは自然と調和しながら独自の科学と哲学を発展させた土星の輪を利用してエネルギーを得る技術生還旅行を可能にする工法そして意識を共有することで社会を形成する独自のシステムが発展していった彼らの社会は共感と理解を基盤として成り立っていた猫たちは言葉を超えたコミュニケーションを行い個々の意識を1つに結び付けることで高度な社会的結束力を実現していたこの結束力こそが土星猫文明がほかの星の文明と平和的に交流する基盤となっていったしかし彼らの文明は繁栄の中にもろさを秘めていた土星の輪が変化する宇宙のサイクルによって彼らの生活基盤も脅かされることがあったその度に猫たちを団結し知恵を絞って危機を乗り越えてきたこれらの困難を乗り越える中で彼らはさらに強く賢くなっていった猫たちの技術の中でも特に注目すべきは彼らの建築技術である土星の和の物質を利用して建てられた彼らの都市は宇宙の壮大な景観の中でもひときわ美しいこれらの都市は猫たちの文化と哲学を反映したデザインが特徴で和と調和の精神が込められていた文化面では猫たちは音楽と舞踊を特に重視していた彼らの音楽は宇宙の調和と共鳴する特別な周波数を用いて作られており聴く者の心と魂を癒やし高める力があるといわれている舞踊は宇宙との一体感を表現するためのもので非常に美しい動きで構成されていた最終的に土星ネコ文明は彼らの知識と技術を宇宙のほかの文明と共有することを決意した彼らは平和と調和のメッセージを持って遠く離れた星々へ旅を続けている地球にも彼らの影響が及び古代のネコが持つ不思議な力や知恵は実は土星からの訪問者の依存かもしれないという説があるこのようにして土星の猫達は宇宙の歴史にその名を刻んでいる彼らの物語ははるかかなたの星に住む我々人類にも共感と理解そして平和の大切さを教えてくれるドセネコ文明の先駆者たちの精神は今も宇宙のどこかで生き続けており我々の心にも響くメッセージとして残っているのである。
whisper large v3
かつてこの宇宙の遥か彼方 土星の美しい輪の中に猫たちは築き上げた高度な文明が存在した彼らは地球上の猫とは異なり 高度な知能とテクノロジーを持ち合わせていたこの物語は我々人類には想像もつかないような猫たちの土星文明の歴史と文化についての探求である土星猫文明の始まりは数万年前に遡る彼らは自然と調和しながら 独自の科学と哲学を発展させた。土星の輪を利用してエネルギーを得る技術、生還旅行を可能にする工法、そして意識を共有することで社会を形成する独自のシステムが発展していった。彼らの社会は共感と理解を基盤として成り立っていた。猫たちは言葉を超えたコミュニケーションを行い個々の意識を一つに結びつけることで高度な社会的結束力を実現していた この結束力こそが土星猫文明が他の星の文明と平和的に交流する基盤となっていったしかし彼らの文明は繁栄の中にも脆さを秘めていた 土星の輪が変化する宇宙のサイクルによって彼らの生活基盤も脅かされることがあったその度に猫たちを団結し知恵を絞って危機を乗り越えてきた これらの困難を乗り越える中で彼らはさらに強く賢くなっていった猫たちの技術の中でも特に注目すべきは彼らの建築技術である 土星の輪の物質を利用して建てられた彼らの都市は宇宙の壮大な景観の中でも人気が美しいこれらの都市は猫たちの文化と哲学を反映したデザインが特徴で輪と調和の精神が込められていた文化面では猫たちは音楽と舞踊を特に重視していた彼らの音楽は宇宙の調和と共鳴する特別な周波数を用いて作られており聞く者の心と魂を癒し、高める力があると言われている。舞踊は、宇宙との一体感を表現するためのもので、 非常に美しい動きで構成されていた。最終的に、土星猫文明は、彼らの知識と技術を 宇宙の他の文明と共有することを決意した。彼らは、平和と調和のメッセージをージを持って遠く離れた星々へ旅を続けている地球にも彼らの影響及び古代の猫が持つ不思議な力や知恵は実は土星からの訪問者の 遺産かもしれないという説があるこのようにして土星の猫たちは宇宙の歴史にその名を刻んでいる 彼らの物語は遥か彼方の星に住む我々人類にも共感と理解の物語は遥か彼方の星に住む我々 人類にも共感と理解そして平和の大切さを教えてくれる土星猫 文明の先駆者たちの精神は今も宇宙のどこかで生き続けており 我々の心にも響くメッセージとして残っているのである
Nue-asr
かつてこの宇宙のはるかかなた土星の美しい輪の中に猫たちが築き上げた高度な文明が存在した彼らは地球上の猫とは異なり。 高度な知能とテクノロジーを持ち合わせていたこの物語は我々人類には想像もつかないような猫たちの同性文明の歴史と文化についての探究である。 文明の始まりは数万年前に遡る彼らは自然と調和しながら独自の科学と哲学を発展させた土星の輪を利用してエネルギーを得る技術。 そして意識を共有することで社会を形成する独自のシステムが発展していった。 猫たちは言葉を超えたコミュニケーションを行い個々の意識を一つに結び付けることで高度な社会的結束力を実現していた。 この結束力こそが土星・猫文明がほかの星の文明と平和的に交流する基盤となっていった。 土星の環が変化する宇宙のサイクルによって彼らの生活基盤も脅かされることがあったその度に猫たちは団結し知恵を絞って危機を乗り切ったのです。 これらの困難を乗り越える中で彼らは更に強く賢くなっていった猫たちの技術の中でも特に注目すべきは彼らの建築技術である。 土星の環の物質を利用して建てられた彼らの都市は宇宙の壮大な景観の中でもひときわ美しいこれらの都市は猫たちの文化と哲学を反映したデザインとなっています。 文化面では猫たちは音楽と舞踊を特に重視していた彼らの音楽は宇宙の調和と共存の象徴でした。 特別な周波数を用いて作られており聴く者の心と魂を癒やし高める力があるといわれている舞踊は宇宙との一体感を表現するものなんです。 最終的に土星ネコ文明は彼らの知識と技術を宇宙のほかの文明と共有するためのものです。 彼らは平和と調和のメッセージを持って遠くはなれた星々へ旅を続けている地球にも彼らの影響が及び古代の猫が持つ不思議な能力。 実は土星からの訪問者の遺産かもしれないという説があるこのようにして土星の猫たちは宇宙の歴史にその名を刻んでいる。 はるか彼方の星に住む我々人類にも共感と理解そして平和の大切さを教えてくれる土星ネコ文明の先駆者たちの精神はいざ知らずです。 今も宇宙のどこかで生き続けており我々の心にも響くメッセージとして残っているのである。
LINE Clova Note
かつてこの宇宙の遥かかなた女性の美しい輪の中に、猫たちが築き上げた高度の文明が存在した。
彼らは地球上の猫とは異なり、高度な知能とテクノロジーを持ち合わせていた。
この物語は、我々人類には想像もつかないような、猫たちの女性文明の歴史と文化についての探求である。
女性コ文明の始まりは数万年前にさかのぼる。彼らは自然と調和しながら独自の科学と哲学を発展させた。
女性の輪を利用してエネルギーを得る技術、生館旅行を可能にする方法、そして意識を共有することで社会を形成する独自のシステムが発展していった。
彼らの社会は共感と理解を基盤として成り立っていた。猫たちは言葉を超えたコミュニケーションを行い、個々の意識を一つに結びつけることで、
高度な社会的結束力を実現していた。この結束力こそが、女性コ文明が他の星の文明と平和的に交流する基盤となっていった。
しかし、彼らの文明は繁栄の中にももろさを秘めていた。女性の輪が変化する宇宙のサイクルによって、彼らの生活基盤を脅かされることがあった。その度に猫たちは団結し、知恵を絞って危機を乗り越えてきた。
これらの困難を乗り越える中で、彼らはさらに強く賢くなっていった。猫たちの技術の中でも特に注目すべきは、彼らの建築技術である。
女性の輪の物質を利用して建てられた彼らの年は、宇宙の壮大な景観の中でも一際美しい。
これらの都市は猫たちの文化と哲学を反映したデザインが特徴で、和と調和の精神が込められていた。
文化面では、猫たちは音楽と舞踊を特に重視していた。彼らの音楽は宇宙の調和と共鳴する特別な周波数を用いて作られており、
聞く者の心と魂を癒し、高める力があると言われている。舞踊は 宇宙との一体感を表現するためのもので、非常に美しい動きで構成されていた。
最終的に、女性猫文明は彼らの知識と技術を宇宙の他の文明と共有することを決意した。
彼らは平和と調和のメッセージを持って、遠く離れた星々へ旅を続けている。
地球にも彼らの影響が及び、古代の猫が持つ不思議な力や知恵は、実は女性からの訪問者の遺産かもしれないという説がある。
このようにして、野性の猫たちは宇宙の歴史にその名を刻んでいる。
彼らの物語は、遥か彼方の星に住む我々人類にも共感と理解、そして平和の大切さを教えてくれる。
女性コ文明の先駆者たちの精神は、今も宇宙のどこかで生き続けており、我々の心にも響くメッセージとして残っているのである。
ReazonSpeech v2は精度が高いものの、句読点がなくて読みにくいかもしれません。Nue-asrは句読点を入れてくれたりするので読みやすいものの、もともと「だ・である調」だったもの一部「です・ます調」になっていたりと、GPT-NeoXによる「生成」が入っているような気がします。whisper-large-v3はその中間という感じでしょうか。
上記の結果だけを見るとwhisperが使いやすそうですが、whisperはノイズの多い環境やフランクなフリートークでは謎のハルシネーションが多発する体感もあります。無音のはずのところで「チャンネル登録よろしくお願いします」などと出てきたこともありました。YouTubeで学習しているのか…??
なので、ReazonSpeechにはかなり期待しています。さまざまなユースケースで使ってみて、その結果も見ていきたいです。
この記事が気に入ったらサポートをしてみませんか?