AtCoder Beginner Contest 325 振り返り

遅くなりましたが、前回の振り返り
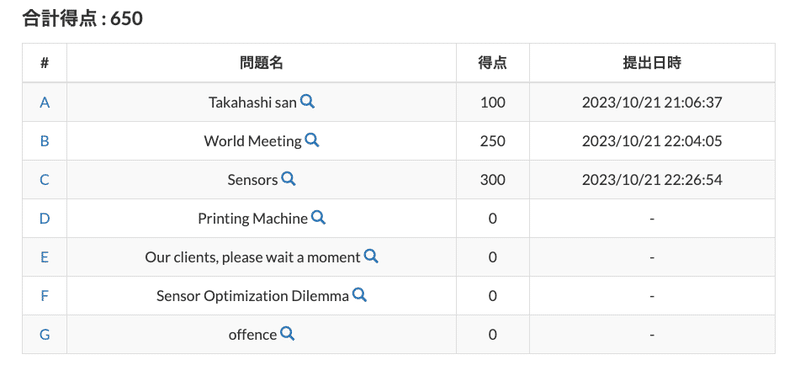
結果
今回もC問題まで解けましたが、正直棚ぼたな感じ。。
各問題の振り返り
A - Takahashi san
最近のA問題の中でも特に簡単だったように思います。データを取得して文字列を追記するだけです。
main :: IO ()
main = do
[s, _] <- words <$> getLine
putStrLn $ s ++ " san"B-3-smooth Numbers
そんなに難しい問題ではないのですが、時間の範囲検索の仕方をミスって時間がかかってしまいました。
時差を +9時間 で解いたのはいいのですが、日跨ぎのところで悩んで時間がかかってしまいました。日跨ぎするとendがstartより早い時間になるので、それで範囲検索すればよかっただけだったのですが…
judgeInTime :: Int -> Int -> Bool
judgeInTime start time
| start <= end = time >= start && time < end
| otherwise = time >= start || time < end
where
end = (start + 9) `mod` 24
numParticipants :: [(Int, Int)] -> Int -> Int
numParticipants es time = sum [w| (w, x) <- es, judgeInTime x time]
main :: IO ()
main = do
n <- readInputInt
es <- replicateM n readPairInt
print $ maximum [numParticipants es time | time <- [0..24]]ちなみに、HaskellにはinRange関数があるのでそっちを使うこともできたようです。(https://hoogle.haskell.org/?hoogle=inRange)
C - Sensors
ChatGPTさんと相談しながら解いてたらなぜか解けてしまった問題。自分の今の実力的には解けなかった問題だったんじゃないかなあと思っています。
Graphに突っ込んで、scc(強連結成分分解)で分解することで解きました。実行時間が1622 msとかなり遅いので、正直ギリギリだと思います。。
buildGraph :: UArray (Int, Int) Char -> Graph
buildGraph grid = graph
where
(h, w) = snd $ bounds grid
indicesInBounds = [(i, j) | i <- [1 .. h], j <- [1 .. w], grid ! (i, j) == '#']
inBounds (i, j) = i >= 1 && i <= h && j >= 1 && j <= w
adjacentNodes (i, j) =
filter
(\pos -> inBounds pos && grid ! pos == '#')
[(i - 1, j), (i + 1, j), (i, j - 1), (i, j + 1), (i - 1, j - 1), (i - 1, j + 1), (i + 1, j - 1), (i + 1, j + 1)]
edges = [(node, node, adjacentNodes node) | node <- indicesInBounds]
(graph, _, _) = graphFromEdges edges
countSensors :: UArray (Int, Int) Char -> Int
countSensors grid = length $ scc graph
where
graph = buildGraph grid
main :: IO ()
main = do
(h, w) <- readPairInt
gridLines <- replicateM h getLine
let grid = listArray ((1, 1), (h, w)) $ concat gridLines :: UArray (Int, Int) Char
print $ countSensors gridコンテスト後に調べるとUnionFindで解くのがセオリーだったので、そちらでも解いてみました。https://zenn.dev/naoya_ito/articles/50e79d637d55c3 を参考に解いてみました。UnionFind自体の詳しい説明はそちらに譲ります。ちなみにunion-findライブラリが使えないので、自前で実装する必要があります。
data UF s = UF {parent :: VM.STVector s Int, rank :: VM.STVector s Int}
toID :: Int -> Int -> Int -> Int
toID w i j = i * w + j
initialize :: Int -> ST s (UF s)
initialize n = do
p <- VM.generate n id
r <- VM.replicate n 0
return $ UF p r
findRoot :: UF s -> Int -> ST s Int
findRoot uf i = do
p <- VM.read (parent uf) i
if p == i
then return i
else do
root <- findRoot uf p
VM.write (parent uf) i root
return root
union' :: UF s -> Int -> Int -> ST s ()
union' uf x y = do
rootX <- findRoot uf x
rootY <- findRoot uf y
when (rootX /= rootY) $ do
rankX <- VM.read (rank uf) rootX
rankY <- VM.read (rank uf) rootY
if rankX < rankY
then do
VM.write (parent uf) rootX rootY
else
if rankX > rankY
then do
VM.write (parent uf) rootY rootX
else do
VM.write (parent uf) rootY rootX
VM.modify (rank uf) (+ 1) rootX
solve :: Int -> Int -> V.Vector (V.Vector Char) -> Int
solve h w grid = runST $ do
uf <- initialize (h * w)
let sensors = [(i, j) | i <- [0 .. (h - 1)], j <- [0 .. (w - 1)], grid V.! i V.! j == '#']
dirs = [(-1, 0), (1, 0), (0, -1), (0, 1), (-1, -1), (-1, 1), (1, -1), (1, 1)]
forM_ sensors $ \(i, j) ->
forM_ dirs $ \(di, dj) ->
when (i + di >= 0 && i + di < h && j + dj >= 0 && j + dj < w && grid V.! (i + di) V.! (j + dj) == '#') $
union' uf (toID w i j) (toID w (i + di) (j + dj))
roots <- mapM (findRoot uf) [toID w i j | i <- [0 .. h - 1], j <- [0 .. w - 1], grid V.! i V.! j == '#']
let uniqueRoots = Set.fromList roots
return $ Set.size uniqueRoots
main :: IO ()
main = do
(h, w) <- readPairInt
grid <- V.fromList <$> replicateM h (V.fromList <$> getLine)
print $ solve h w grid実行結果は374 msとかなり高速化できました。
補足
HaskellのnubはものによるとO(n^2)かかるようで、効率悪いこともあるようです。シグネチャによってオーダは違うので、https://hoogle.haskell.org/?hoogle=nub を参照すると良いと思います。
全体を振り返って
今回は棚ぼたでしたが、GraphやUnionFindといったアルゴリズムを実装することで、Haskellのより詳細な特徴(純粋であることによる非効率さとか、STモナド)を知ることができたと思います。
もっともっといろんな問題を解いて、Haskellと仲良くなっていきたいです。
この記事が気に入ったらサポートをしてみませんか?