LangSmithとRagasを組み合わせたRAG実装

こんにちは、福田です。
今回は「Ragas(RAG評価ツール)とLangSmithを組み合わせて、RAG実装をテストする方法に」ついてです。
こちらをまとめてみました。
Ragasとは
Ragasは、RAG実装をテストおよび評価するために使用できるフレームワークです。以下の画像に示すように、RAG評価プロセスは評価を2つのカテゴリーに分けます。生成と検索です。生成はさらに2つの指標、忠実度(Faithfullness, Relevance)と関連性に分けられます。検索はコンテキスト精度とコンテキスト再現率(Context Precision, Context Recall)に分けられます。詳細は以下の図をご覧ください。
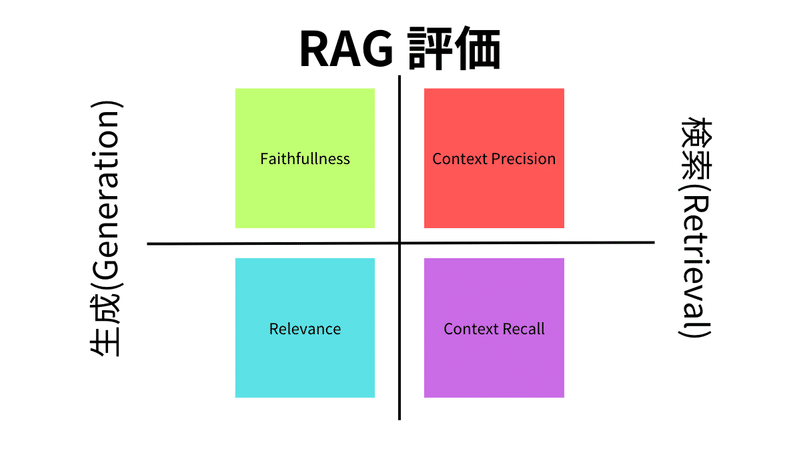
Ragasの評価軸は、以下のように解釈することが可能です:
信頼性(Faithfulness):生成された回答が与えられたコンテキストと事実上一致しているかどうかを測定します。
コンテキスト関連性(ContextRelevancy):生成された回答が与えられたコンテキストと関連しているかどうかを評価します。
コンテキスト再現性(Context Recall):生成された回答が与えられたコンテキストの情報をどの程度反映しているかを評価します。
回答の関連性(Context Precision):生成された回答が質問に対して適切であるかどうかを評価します。
さらに有害性など、直接スコアと関係のない部分も評価の対象となります。
アスペクト批評(AspectCritique):生成された回答が特定の観点(例えば、正確さ、有害性、一貫性、簡潔さ、悪意など)についてどの程度適切であるかを評価します。このスコアは最終的なragas_scoreには考慮されません。
LangSmithでの操作
それでは実際にLangSmithでの画面を確認してみます。
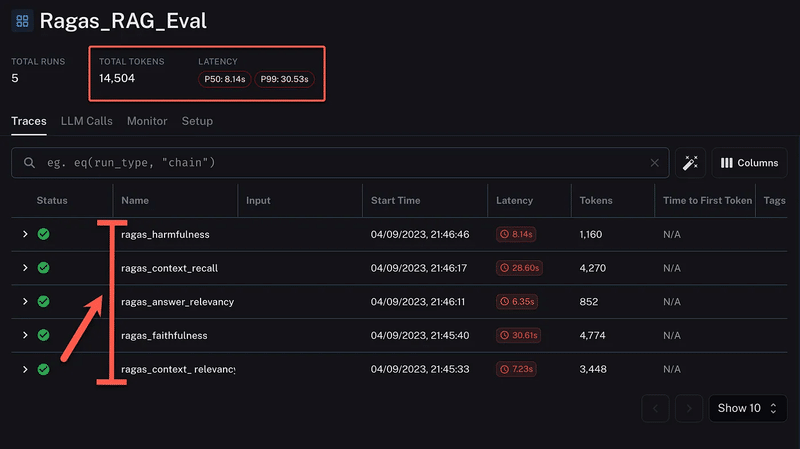
以下の画像は、LangSmithでのRagasセッションのビューで、合計14,504トークンが消費され、P50レイテンシーは8.14秒、P99レイテンシーは30.53秒でした。
現状(9月)、RagasはOpenAIを使用していますが、RagasがよりLLM非依存になるのは理にかなっています(LangChainでの活用を考えれば十分に実現可能)。
さらにLangSmithの統合により、Ragasを実行する際のコストとレイテンシーが明らかになります。この評価ベースの実装では、レイテンシーはそれほど重要ではないかもしれませんが、コストは課題になる可能性があります。
実際、今回の場合(画像)に表示されているのは5回の実行で、有害性、コンテキスト再現率、回答関連性、忠実度、コンテキスト関連性のスコアが表示されています。各行にはステータス、名前、開始時間、レイテンシー、消費したトークンが表示されています。Ragasは、従来の指標の制限に対処し、LLMを活用することでQA評価を強化すると考えられます。
実際にLangSmithは結果を視覚化するためのサポートプラットフォームとしてRagasをサポートしています。LangSmithでログ、トレース、モニタリングを使用すると、データセットへの追加機能を使用して、継続的な評価パイプラインを設定できます。これにより、テストデータセットを最新かつ包括的なデータセットで更新し続けることが可能です。
以下は有害性の実行で展開されたもので、各実行が表示されています。
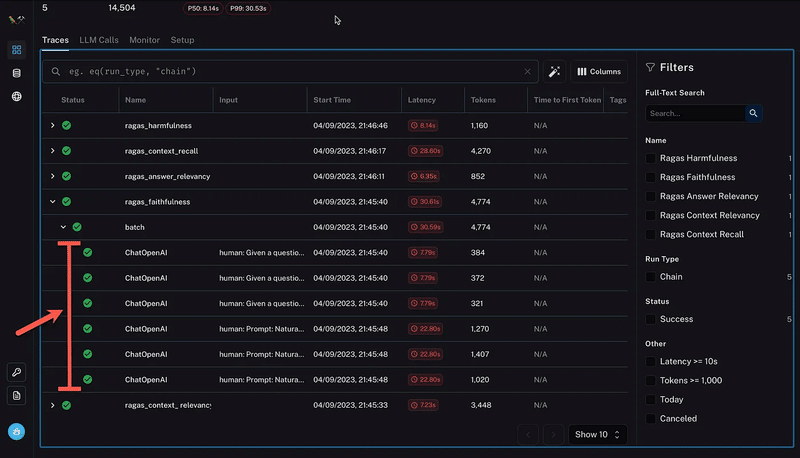
そして以下には忠実度のに関するチェーンが表示されており、6つのLLMインタラクションノードでチェーンを見ることができます。入力とLLM出力が表示されています。
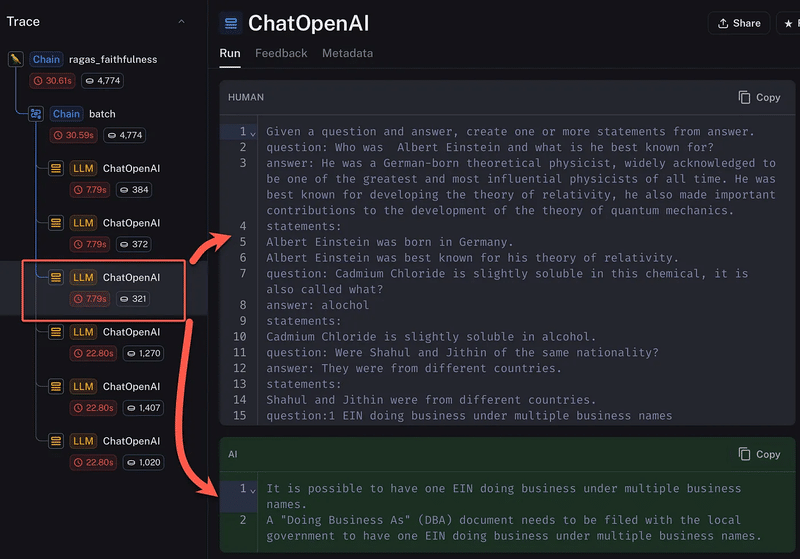
また以下のように、単一ノードのチェーンがOpenAIプレイグラウンドで複製されており、参考として表示されています。
OpenAIプレイグラウンドはこちらから→

以下は、OpenAIをLLMとして使用し、LangSmithにメトリクスをログするRagasを実行するための全体コードです。OpenAI APIキーを追加し、LangSmithへのアクセスも必要です。
LangSmithのWaiting Listはこちらから→
pip install ragas
pip install tiktoken
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxxxxxx"
pip install -U langsmith
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Ragas_RAG_Eval"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "xxxxxxxxxxxx"
# data
from datasets import load_dataset
fiqa_eval = load_dataset("explodinggradients/fiqa", "ragas_eval")
fiqa_eval
from ragas.metrics import (
context_relevancy,
answer_relevancy,
faithfulness,
context_recall,
)
from ragas.metrics.critique import harmfulness
from ragas import evaluate
result = evaluate(
fiqa_eval["baseline"].select(range(3)),
metrics=[
context_relevancy,
faithfulness,
answer_relevancy,
context_recall,
harmfulness,
],
)
result
このコードを実行すると、Ragasが評価データセットに対してRAGモデルを使用して質問に回答し、各回答に対してそれぞれのメトリクスを計算します。結果は辞書形式で返されます。例えば、以下のような結果が得られます。
テスト結果
{
'ragas_score': 0.3519,
'context_ relevancy': 0.1296,
'faithfulness': 1.0000,
'answer_relevancy': 0.9257,
'context_recall': 0.6370,
'harmfulness': 0.0000
}また、データファイルを確認したい場合は以下のようにして確認します。
データファイルを確認
df = result.to_pandas()
df.head()
これらの結果は、LangSmithにもログされており、LangSmithのダッシュボードで視覚化することができます。

LangSmithでは、各評価セッションに一意のIDが割り当てられ、そのIDで結果を検索することができます。また、各評価セッションには、Ragasが使用した質問と回答のペアも含まれており、それらを詳細に確認することができます。LangSmithでは、Ragasの評価プロセスをより透明化し、より洞察力のあるフィードバックを提供することを目指しています。
さらに詳しい内容については、公式のDocumentationを確認してみてください。
最後まで読んでいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?